- +1
看了946條辟謠信息,我們提煉出一些信息辨別方法
“剛接通知,定于今晚12點對全市主干道進行大面積消殺、消毒工作。因此次消毒藥水濃度較大,請各位今晚10點后務必呆在家中……”
“水廠的朋友來電告知,非常時期,自來水中在允許的范圍內加大了氯氣的注入,水靜置兩小時以上再用……”
疫情期間,上述信息出現了全國各地版本,特殊時期公眾對信息更為渴求,在信息的海洋中,普通公眾又該如何有效鑒別信息呢。我們爬取了“微博辟謠”平臺于1月20日至2月11日間發布的與新型冠狀病毒肺炎相關的全部微博共804條,刪除重復、拆分合集后共946條(下稱“相關微博”),其內容涉及被判定為謠言的內容以及辟謠信息,我們從內容分類、發布主體、呈現形式等維度進行編碼、分析。“微博辟謠”是新浪微博虛假消息辟謠官方賬號,通常轉載其它認證賬號發布的“辟謠信息”,每日匯總為合集置頂推送。
數據分析發現,“微博辟謠”賬號轉發的相關微博,其主題集中在“疫情傳播情況”與“政府政策措施”上,呈現形式以文字為主,近7成被判定為謠言的信息中未交代信源。

在近千條相關微博中,除“肺炎”“疫情”“武漢”“新型冠狀病毒”等與事件直接相關的詞匯外,“車輛”“口罩”“消毒”“人員”“指揮部”等是主要的高頻詞。與人們生活貼近的“小區”“門店”“超市”“外出”等也頻頻被提及。“轉發”“轉告”等高頻詞映射出相關內容的傳播需求。

將“微博辟謠”平臺試圖撇清的謠言按內容分類繪制成折線圖,每條折線代表不同內容類別的微博隨時間變化的情況,有關“疫情傳播情況”與“政府政策措施”的內容數量最多,比如“xx地又確診了xx例病例”、“xx剛從武漢回來”等內容分別在1月28日和2月6日達到高峰。隨著各地防控措施的加碼,“我市今晚12點進行大規模消毒”、“我市即將封城、封路”等有關政策措施的內容也隨之流傳。
分析相關微博,我們發現被“微博辟謠”轉載被判定為謠言的內容中,52%的內容以純文字的形式呈現,單獨以視頻形式傳播的內容占到了8%,圖片配文字以及視頻配文字的形式也較為多見。
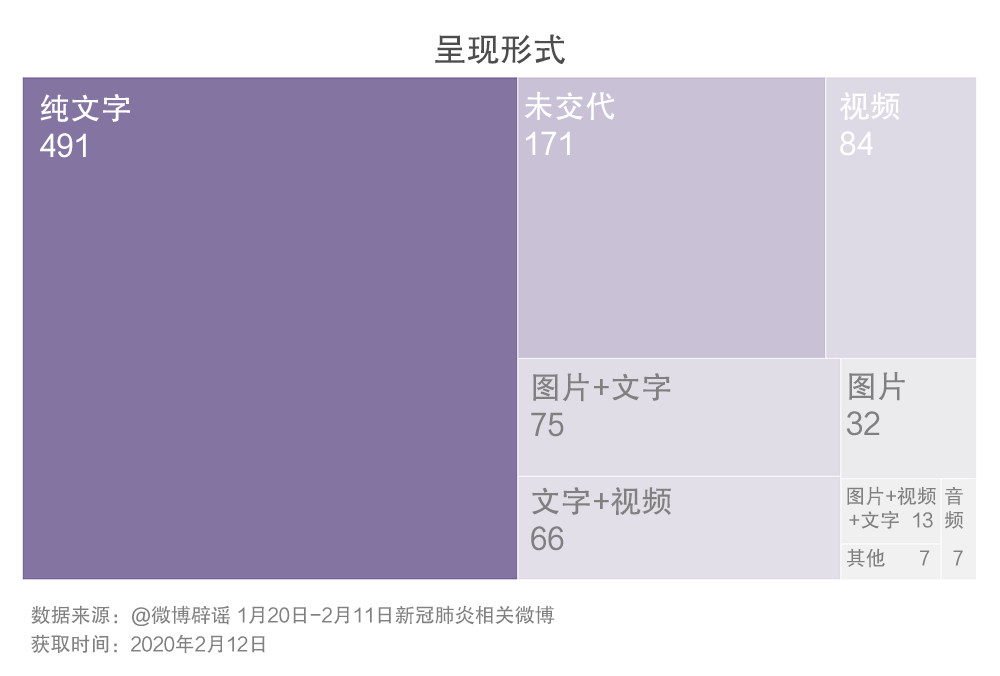
力求真實與客觀規范的新聞寫作中強調交代信息來源,并且要交代信息來源的全稱或全名,也就是具名。在我們分析的相關微博內容中,未交代信源的占69.8%,不足1.5%交代了信息來源的名稱。
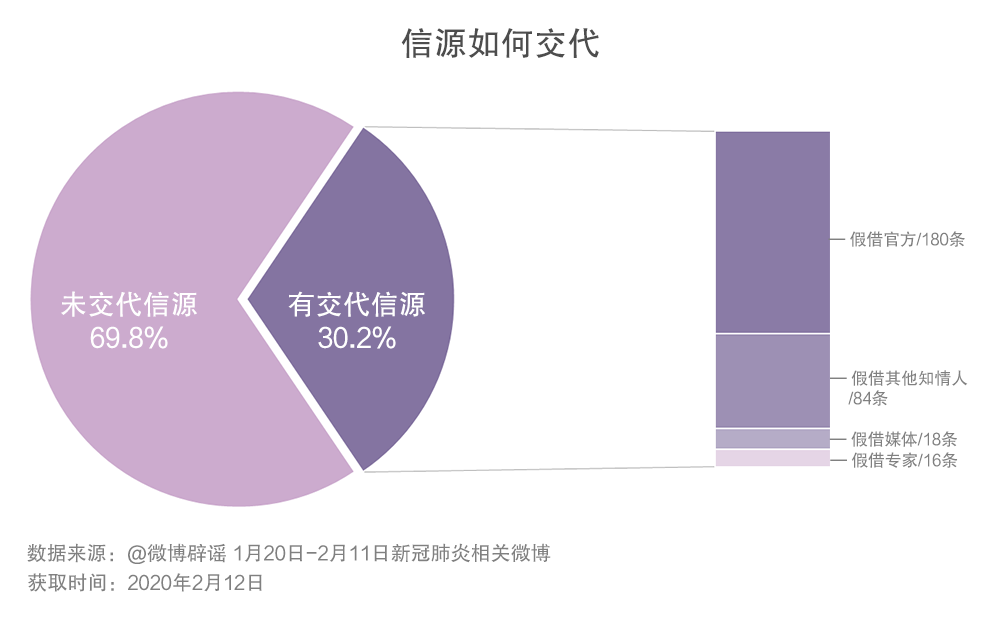
被判定為謠言的內容中,有30.2%寫明了信源,假借官方發布內容是最常見的方式,例如以“市政府辦”、“公安局網絡中心”等落款。其次則是假借其他“知情人”消息,例如有些內容來自內部工作人員透露。還有部分內容假借了媒體和專家的名義,如通過PS合成電視節目截圖,或“鐘南山院士稱鹽水漱口可防病毒”等。
新聞寫作專業規范也要求提供時間和地點信息,這是新聞五要素(5W)的重要組成部分。被認定為謠言的內容中,包含時間和地點要素的內容占47.46%,另有36%的內容提供了地點信息,這些內容通常在特定地區傳播,比如某地確定病例超過幾千等。也有的內容在全國各地復現,例如“全城大消殺”、“某小區酒精消毒后開空調導致火災”等,反映出較為普遍的社會心態。
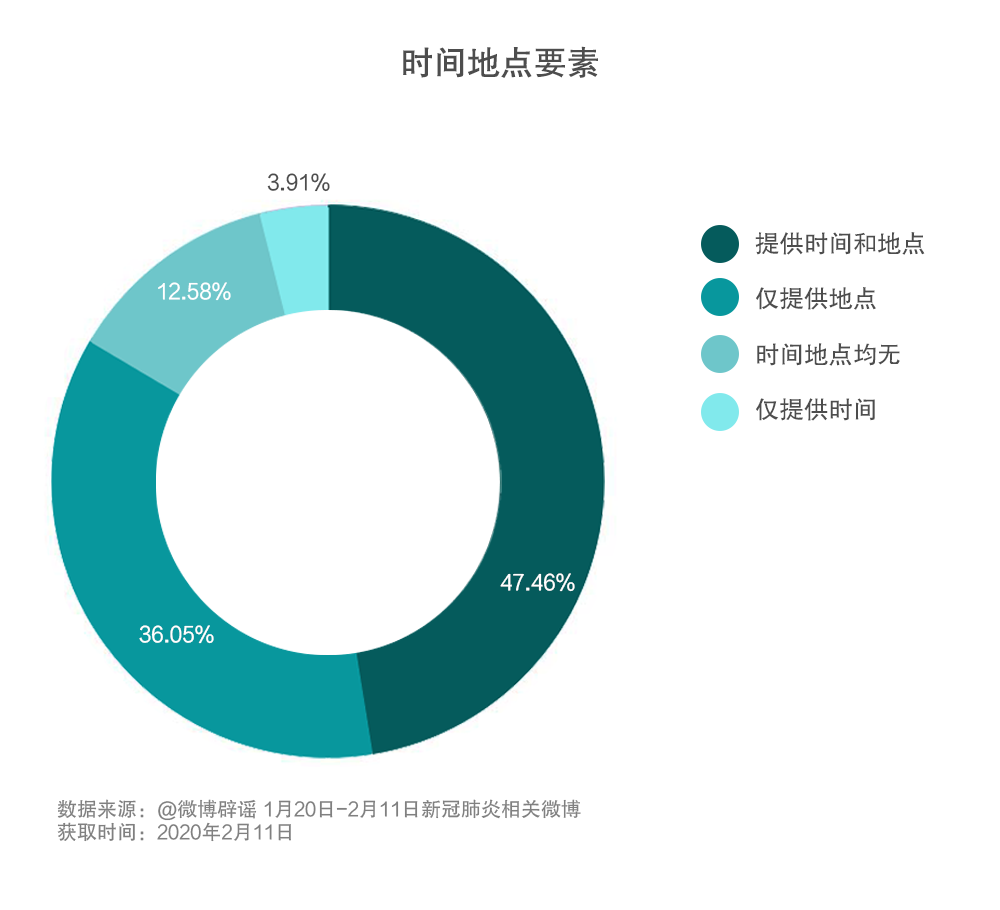
復旦大學新聞學院周葆華教授認為,帶有時間和地點的信息,使得內容看上去比較具體、準確,對傳播有作用;訴諸權威信源的策略則反映了來自權威部門的信息容易獲得信任和傳播,這也提醒政府部門應當及時公開與疫情有關的重要公共信息。
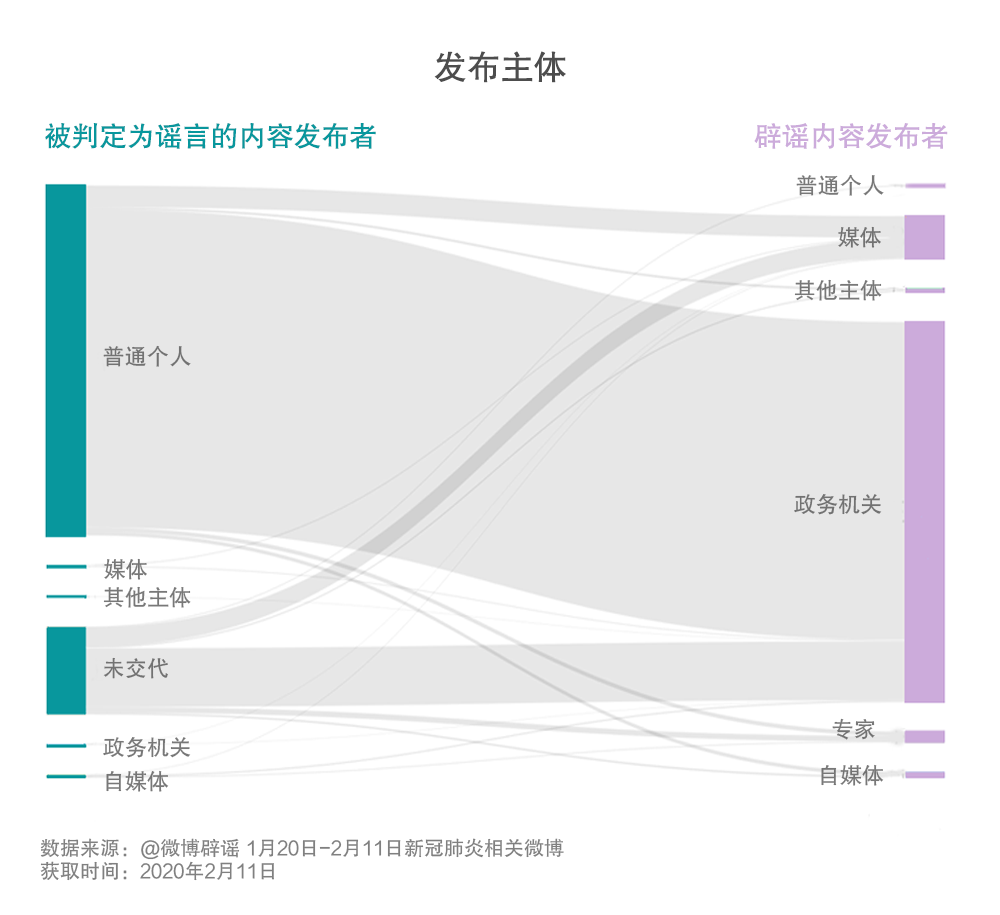
那么是誰在發布被判定為謠言的內容,又是誰在發布辟謠信息呢?從獲取的數據來看,除去未交代發布主體的微博,絕大部分被判定為謠言的內容都是由普通個人發布的,也有極少數出自媒體、政務機關、自媒體等。而發布辟謠信息的則多為政務機關,媒體也是較為重要的辟謠主體,此外,少數辟謠信息由專家、普通個人、自媒體等發布。
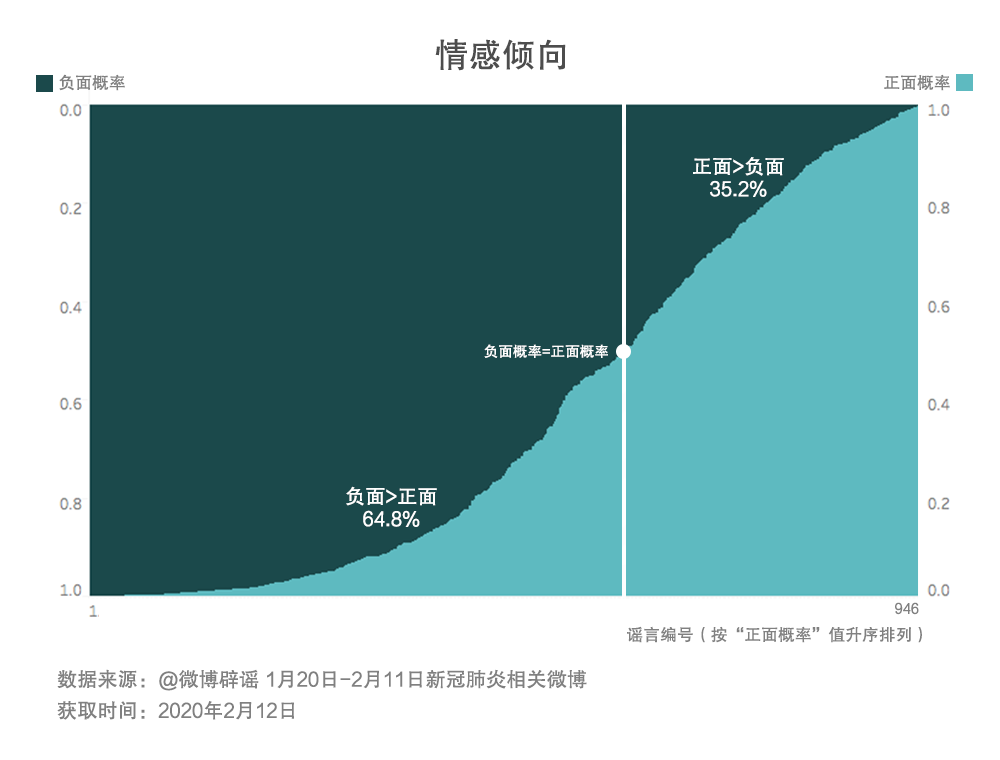
使用百度AI情感分析相關微博,結果顯示,負面情感大于正面情感的內容占到六成以上,相關的內容涉及感染情況等。而正面情感大于負面情感的內容則多與新藥研發、防治方法等相關。
疫情事件本身的重要性、高風險、高關注決定了相關信息的大量傳播,周葆華認為,疫情事關每個人的生命健康與安全,充滿風險與不確定性,公眾對疫情信息的需求度很高。同時,我們身處信息高速流動的移動互聯網時代,加速了信息的傳播;與疫情有關重要信息的公開、透明不夠及時、充分,也是影響部分傳言或謠言產生的可能因素。
根據學者研究,謠言中的“謠”在古代漢語中指不用樂器伴奏的歌唱,這種隨意性、搖擺性和不確定性為其向謠言、謠傳等詞匯的過渡埋下了伏筆。[i] 在不同社會情境中,對謠言的界定尚存爭議。不過研究者大多認同:“謠言的產生首先與信息結構有關系。面對不確定的事件,如果權威的信息無法及時跟進或不足以消除大眾疑慮,謠言就會填補這個空白,幫助人們建構事件的意義。在沒有權威信息之前,傳播謠言能幫助緩解焦慮。”[ii]
由于社會環境、社會心理等因素,謠言作為一種面對重要事件、存在模糊性情境下必然會產生的“即興”信息,不可能完全消除,但可以減少其規模與負面影響。周葆華教授認為,首先,在信息的供給方面,政府等掌握公共信息的部門應當堅持公開透明,及時發布信息、回應公眾關切,減少公眾疑慮;在公眾對信息的接受方面,則需要增強對紛繁復雜信息的鑒別力,例如對信息、信源的核實查證能力,通過多個渠道來校驗與核實信息,提高自己的信息素養。
彩蛋:
識別照片真偽小工具TinEye
信息海洋時而可見移花接木的信息,比如三年前拍攝的圖片,重新成為熱點,使用TinEye等圖像反向搜索引擎即可幫助公眾鑒別圖片真偽。

用戶可以在TinEye主頁面中上傳提交圖像文件或輸入圖像地址,隨后TinEye會匹配尋找該圖像的大量編輯版本,在搜索結果中提供各編輯版本的圖像網址和發布時間,將搜索結果“按最舊排序”則可尋找到最接近源圖像的編輯版本,根據其網頁內容辨別圖片真偽。
附錄:研究方法
本研究自“微博辟謠”賬號平臺爬取了2020年1月20日至2月11日間與新型冠狀病毒肺炎(NCP)相關的辟謠微博共804條,其內容涉及被認定為謠言的信息以及辟謠信息。隨后我們對疫情無關和重復謠言進行刪除、對合集謠言進行拆分后共得謠言946條。
基于相關文獻回溯,本研究從內容特征、呈現形式及發布主體等維度進行分析。其中,內容特征包括內容類別、信源交代方式、信源是否具名、是否含時間、是否含地點等維度。呈現形式包括純文字、文圖、文字加視頻等。發布主體主要分為普通個人、媒體、政務機關等。
編碼由四位經過系統編碼培訓的編碼員共同完成。以下是編碼規則。

在編碼培訓中,所有編碼員兩次對隨機選取的數據進行預編碼,并嚴格對比編碼結果,集中討論編碼過程中遇到的問題,解決編碼分歧,最終對編碼標準進行了統一。正式編碼中,依照評價一致度計算(Krippendorff’s alpha coefficient),編碼員互相信度平均值為0.728。
此外,編碼員在編碼過程中還對被認定為謠言的原微博進行了采集,由于原始內容或被刪除,采集的原始內容多來自辟謠微博描述或截圖。通過對整體文本的內容分析,研究增加了詞頻分析和情感分析維度,情感分析工具為百度AI情感傾向分析平臺。
參考資料:
[i] 張志平,“‘謠言’的詞源學和現象學釋義”,《社會學家茶座》,2009年第3期,102-103頁。
[ii] 劉海龍,“技術已經這么發達,謠言為什么還滅不完?這不奇怪”,2019年,https://new.qq.com/rain/a/20190409A0O9EE00。
作者:何詒雯、李泓、麻慧琳、陶晨、溫瑞琪、張淑凡、朱月萌、王晶晶(華東師范大學通信與電子工程學院)、徐奕湛(華東師范大學通信與電子工程學院)
復旦大學新聞學院《數據分析與信息可視化》(本科生)、《數據新聞與可視化》(碩士生)課程專欄
指導老師:周葆華、徐笛、崔迪
本文為湃客·有數欄目首發稿件,未經授權,禁止轉載。

本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

