- +1
OpenAI路線遭質(zhì)疑!Meta研究員:根本無法構(gòu)建超級智能
超級智能(Superintelligence)是處于 AGI 之上、甚至通用能力超過人類的更高維 AI 發(fā)展方向。
扎克伯格不惜以一億美金年薪挖角 OpenAI 等競爭對手的動作背后,便暴露了 Meta 等頭部玩家追求“超級智能”的巨大野心。
那么,超級智能將如何實現(xiàn)?現(xiàn)有大語言模型(LLM)的研究路徑是否正確?Scaling Laws 能夠在這一過程中繼續(xù)奏效?
早在 2023 年,OpenAI 首席執(zhí)行官 Sam Altman 便表示,構(gòu)建 AGI 是一個科學(xué)問題,而構(gòu)建超級智能卻是一個工程問題。這似乎暗示了他們知道構(gòu)建超級智能的可行路徑。
然而,在 Meta AI 研究員 Jack Morris 看來,Altman 提到超級智能的“工程問題”,在于“構(gòu)建大量適用于不同任務(wù)的 RL 環(huán)境,并訓(xùn)練 LLM 同時處理所有這些任務(wù)”。他認(rèn)為,這一由 OpenAI 等公司當(dāng)前大力推進(jìn)的路徑——基于 LLM 的 RL——根本無法構(gòu)建超級智能。
“我謙卑的預(yù)測是:LLM 將繼續(xù)在訓(xùn)練分布內(nèi)的任務(wù)上變得更好。隨著我們收集更多類型的任務(wù)并進(jìn)行訓(xùn)練,這將產(chǎn)生在廣泛任務(wù)上越來越有用的 LLM。但它不會成為一個單一的超級智能模型。”
Morris 在一篇題為“Superintelligence, from First Principles”的博客中,探討了構(gòu)建超級智能的 3 種可能方式:完全由監(jiān)督學(xué)習(xí)(SL)、來自人類驗證者的強化學(xué)習(xí)(RL)、來自自動驗證器的 RL。
此外,他還認(rèn)為,將非文本數(shù)據(jù)整合到模型中并不能帶來模型整體性能的提升,“由實際人類撰寫的文本攜帶某種內(nèi)在價值,而我們周圍世界純粹的感官輸入永遠(yuǎn)無法具備這種價值。”
學(xué)術(shù)頭條在不改變原文大意的情況下,對整體內(nèi)容做了精編,如下:

原文鏈接:
https://blog.jxmo.io/p/superintelligence-from-first-principles
許多人都在討論如何利用當(dāng)前技術(shù)實現(xiàn)AGI(通用人工智能)或ASI(超級人工智能)。Meta最近宣布,他們正在建立一個秘密的“超級智能”實驗室,投入了數(shù)十億美元的資金。OpenAI、Anthropic和Google DeepMind都以不同方式表達(dá)了構(gòu)建超級智能機器的目標(biāo)。
Sam Altman特別表示,超級智能僅僅是一個工程問題:

這暗示著OpenAI的研究人員知道如何構(gòu)建超級智能,只需要投入時間和精力來建立所需的系統(tǒng)就行了。
作為一名AI研究員,我并不清楚如何構(gòu)建超級智能——我甚至不確定這是否可能。因此,在這篇文章中,我希望深入探討一些細(xì)節(jié),并推測是否有人能夠從第一性原理出發(fā)來嘗試構(gòu)建超級智能。
我們假設(shè)實現(xiàn)這一技術(shù)的基本構(gòu)建模塊已經(jīng)確定:即采用神經(jīng)網(wǎng)絡(luò)作為基礎(chǔ)架構(gòu),并通過反向傳播算法以及某種形式的機器學(xué)習(xí)方法對其進(jìn)行訓(xùn)練。
我認(rèn)為架構(gòu)(神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu))并不是最關(guān)鍵的因素。因此,我們將略過有關(guān)架構(gòu)的細(xì)節(jié),并做出一個大膽的假設(shè):超級智能將采用Transformers構(gòu)建,這是目前在大型數(shù)據(jù)集上訓(xùn)練這類系統(tǒng)的最流行架構(gòu)。
那么,我們已經(jīng)知道很多:超級智能將是一個Transformers神經(jīng)網(wǎng)絡(luò),它將通過某種機器學(xué)習(xí)目標(biāo)函數(shù)和基于梯度的反向傳播進(jìn)行訓(xùn)練。這里仍然有兩個主要的開放性問題。我們使用哪種學(xué)習(xí)算法,以及使用什么數(shù)據(jù)?
讓我們從數(shù)據(jù)開始。
數(shù)據(jù):必須是文本
導(dǎo)致ChatGPT誕生的許多重大突破,很大程度上源于對互聯(lián)網(wǎng)上龐大的人類知識寶庫的學(xué)習(xí)。盡管它的大部分復(fù)雜性都被現(xiàn)代工程巧妙地隱藏了起來,但讓我們花點時間試圖弄清楚這一切。
目前最好的系統(tǒng)都依賴于從互聯(lián)網(wǎng)的文本數(shù)據(jù)中學(xué)習(xí)。截至本文撰寫時(2025年6月),我認(rèn)為將非文本數(shù)據(jù)整合到模型中并未帶來整體性能的提升。這包括圖像、視頻、音頻以及機器人技術(shù)的超感官數(shù)據(jù)——我們尚不清楚如何利用這些模態(tài)來提升ChatGPT的智能水平。
為什么會這樣呢?這可能只是一個科學(xué)或工程挑戰(zhàn),我們可能沒有采用正確的方法;但也有可能文本本身具有某種特殊性。畢竟,互聯(lián)網(wǎng)上的每一段文本(在LLM出現(xiàn)之前)都是人類思維過程的反映。從某種意義上說,人類撰寫的文本經(jīng)過預(yù)處理,具有非常高的信息含量。
相比之下,圖像只是我們周圍世界未經(jīng)人類干預(yù)的原始視角。確實有可能,由實際人類撰寫的文本攜帶某種內(nèi)在價值,而我們周圍世界純粹的感官輸入永遠(yuǎn)無法具備這種價值。
因此,在有人證明情況相反之前,讓我們假設(shè)只有文本數(shù)據(jù)才是重要的。
那么,我們有多少文本數(shù)據(jù)呢?
下一個問題是,這個數(shù)據(jù)集可能有多大。
許多人已經(jīng)討論過,如果文本數(shù)據(jù)用完了,我們應(yīng)該如何應(yīng)對。這種情況被稱為“數(shù)據(jù)墻”或“token危機”,人們已經(jīng)探討了如果我們真的用完了數(shù)據(jù)該怎么辦,以及如何擴展我們的模型。
而這種情況似乎真的正在發(fā)生。許多大型人工智能實驗室的工程師已經(jīng)花費了無數(shù)小時,從網(wǎng)絡(luò)的各個角落刮取每一個有用的文本片段,甚至轉(zhuǎn)錄了數(shù)百萬小時的YouTube視頻,并購買了大量新聞故事來進(jìn)行訓(xùn)練。
幸運的是,這里可能還有另一個數(shù)據(jù)源可用(可驗證的環(huán)境!),但我們稍后再討論這個。
學(xué)習(xí)算法
在上文中,我們發(fā)現(xiàn)了一個重要的原則:通向超級智能的最佳路徑在于文本數(shù)據(jù)。換句話說,AGI很可能就是LLM,或根本不存在。其他一些有前景的領(lǐng)域包括從視頻和機器人技術(shù)中學(xué)習(xí),但這些領(lǐng)域似乎都遠(yuǎn)未達(dá)到在2030年前產(chǎn)生獨立智能系統(tǒng)的水平。它們也需要大量數(shù)據(jù);從文本中學(xué)習(xí)自然非常高效。
現(xiàn)在我們必須面對最重要的問題。超級智能的學(xué)習(xí)算法是什么?
在機器學(xué)習(xí)領(lǐng)域,從大型數(shù)據(jù)集中學(xué)習(xí)的基本方法(經(jīng)過驗證)有兩種。一種是SL,即訓(xùn)練模型以增加某些示例數(shù)據(jù)的概率。另一種是RL,涉及從模型中生成數(shù)據(jù),并因其采取“良好”行動(由用戶定義的“良好”標(biāo)準(zhǔn))而給予獎勵。
既然我們了解了這一分類,就清楚任何潛在的超級智能系統(tǒng)都必須通過SL或RL(或兩者結(jié)合)進(jìn)行訓(xùn)練。
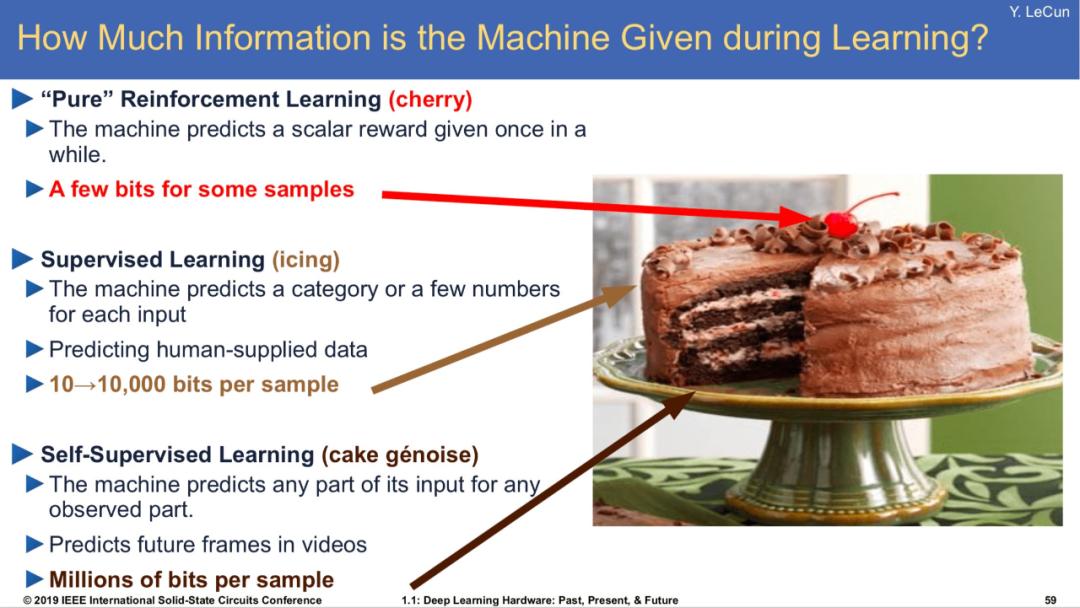
圖|楊立昆(Yann LeCun)曾表示他知道通向智能的秘訣。事實上,智能就像一塊蛋糕,而RL只是上面的一小顆櫻桃。
讓我們分別探討這兩種方案。
1.假設(shè)1:超級智能來自SL
還記得2023年嗎?那正是人們開始對scaling laws感到興奮的時候;GPT-4發(fā)布后,人們擔(dān)心如果模型繼續(xù)規(guī)模化,可能會變得危險。

圖|大約在2023年,很多人開始擔(dān)心,LLM通過簡單的監(jiān)督學(xué)習(xí)擴展后,很快會演化為超級智能。
有一段時間,人們普遍認(rèn)為大量的SL,特別是以“next-token prediction”的形式,可能導(dǎo)致超級智能AI的出現(xiàn)。值得注意的是,Ilya Sutskeve曾發(fā)表過一場演講,指出next-token prediction本質(zhì)上是在學(xué)習(xí)壓縮“(信息)宇宙”,因為要做好這一點需要模擬所有可能的程序(或者類似的東西)。
我認(rèn)為他的論點大致如下:
準(zhǔn)確的next-token prediction需要對任何人在任何情境下會寫的內(nèi)容進(jìn)行建模
你對一個人的建模越準(zhǔn)確,就越能接近這個人的智能
由于互聯(lián)網(wǎng)包含許多人撰寫的文本,因此在大型文本預(yù)訓(xùn)練數(shù)據(jù)集上進(jìn)行訓(xùn)練,就需要準(zhǔn)確建模許多人的智能
準(zhǔn)確建模許多人的智能就是超級智能
(1)“氛圍”論:我們能否通過模擬人類實現(xiàn)超級智能?
我個人認(rèn)為,這種邏輯存在一些缺陷,首先,我們似乎已經(jīng)創(chuàng)建了在next-token prediction方面遠(yuǎn)超人類水平的系統(tǒng),但這些系統(tǒng)仍無法展現(xiàn)人類級別的通用智能。某種程度上,我們構(gòu)建的系統(tǒng)雖然學(xué)會了我們要求它們學(xué)習(xí)的內(nèi)容(next-token prediction),卻仍無法完成我們期望它們完成的任務(wù)(如不憑空杜撰地回答問題、完美遵循指令等)。
這可能僅僅是機器學(xué)習(xí)的失敗。我們一直在訓(xùn)練一個模型,以預(yù)測每種情況下的人類平均結(jié)果。這種學(xué)習(xí)目標(biāo)鼓勵模型避免給任何一種可能的結(jié)果賦予過低的概率。這種范式常常導(dǎo)致所謂的“模式崩潰”(mode collapse),即模型在預(yù)測平均結(jié)果方面非常出色,卻未能學(xué)習(xí)分布的尾部。
這些問題可能在規(guī)模擴展后消失。擁有數(shù)十億參數(shù)的模型,如Llama,會產(chǎn)生幻覺,但僅有10^9個參數(shù)。當(dāng)我們訓(xùn)練擁有10^19個參數(shù)的模型時會發(fā)生什么?或許這足以讓單個LLM獨立給全球80億人類建模,并為每個人提供獨立的數(shù)據(jù)驅(qū)動預(yù)測。
(2)Infra論:我們無法擴展模型和數(shù)據(jù)
但事實證明,這已無關(guān)緊要,因為我們可能永遠(yuǎn)無法擴展到10^19個參數(shù)(的規(guī)模)。這一假設(shè)基本上源于2022年左右的深度學(xué)習(xí)學(xué)派,他們受語言模型scaling laws的巨大成功驅(qū)動,認(rèn)為持續(xù)擴展模型和數(shù)據(jù)規(guī)模將實現(xiàn)完美智能。
現(xiàn)在是2025年。這一理論論點仍未被挑戰(zhàn),scaling laws也一直有效。但事實證明,當(dāng)規(guī)模超過一定閾值后,擴展模型變得非常困難(而早在2022年,我們已經(jīng)非常接近能夠有效處理的極限)。企業(yè)已經(jīng)遠(yuǎn)遠(yuǎn)超出了我們用單臺機器能夠做到的范圍——所有最新模型都是在由數(shù)百臺機器組成的巨型網(wǎng)絡(luò)上訓(xùn)練的。
繼續(xù)將模型規(guī)模擴展到萬億級參數(shù),正引發(fā)硬件短缺和電力短缺。更大的模型將消耗如此多的電力,以至于無法集中部署于單一地點;企業(yè)正在研究如何將模型訓(xùn)練分布到多個遙遠(yuǎn)的數(shù)據(jù)中心,甚至收購、修復(fù)廢棄核電站來訓(xùn)練下一代更大規(guī)模的AI模型。我們正處于一個瘋狂的時代。
除了模型規(guī)模,我們可能還面臨數(shù)據(jù)不足的問題。沒有人知道每個模型在訓(xùn)練過程中使用了多少互聯(lián)網(wǎng)數(shù)據(jù),但可以肯定的是,數(shù)量相當(dāng)龐大。過去幾年,大型人工智能實驗室投入了巨大的工程努力,從互聯(lián)網(wǎng)文本數(shù)據(jù)中榨取最后一點價值:例如,OpenAI似乎已經(jīng)轉(zhuǎn)錄了整個YouTube,而像Reddit這樣的高質(zhì)量信息網(wǎng)站也被反復(fù)抓取。
將模型規(guī)模擴展到超過1000億參數(shù)似乎很困難,同樣,將數(shù)據(jù)規(guī)模擴大到20T tokens以上也很困難。這些因素似乎表明,在未來三到四年內(nèi),SL的規(guī)模很難再擴展10倍以上——因此,對超級智能的探索可能不得不從其他地方尋找突破口。
2.假設(shè)2:通過結(jié)合SL與RL實現(xiàn)超級智能
也許你認(rèn)同上述觀點之一:要么我們在很長一段時間內(nèi)都無法將預(yù)訓(xùn)練規(guī)模再提升幾個數(shù)量級,要么即使我們做到了,在預(yù)測人類token方面表現(xiàn)得非常出色,也無法構(gòu)建比人類更聰明的系統(tǒng)。
還有另一種方法。RL領(lǐng)域提供了一整套方法,可通過反饋而非僅依賴演示進(jìn)行學(xué)習(xí)。
為什么我們需要SL?
RL是非常難的。你可能會好奇,為什么我們不能全程使用RL。從實際角度來看,RL有許多缺點。簡而言之,SL比RL穩(wěn)定且高效得多。一個易于理解的原因是,由于RL通過讓模型生成動作并對其進(jìn)行評分來工作,一個隨機初始化的模型基本上是糟糕的,所有動作都毫無用處,它必須偶然做好一些事才能獲得任何形式的獎勵。這就是所謂的冷啟動問題,而這只是RL眾多問題中的一個。基于人類數(shù)據(jù)的SL被證明是解決冷啟動問題的有效方法。
讓我們重新梳理RL的范式:模型嘗試各種操作,然后我們告知模型這些操作的表現(xiàn)好壞。這可通過兩種方式實現(xiàn):要么由人類評估者告知模型表現(xiàn)優(yōu)劣(這大致是典型RLHF的工作原理),要么由自動化系統(tǒng)完成此任務(wù)。
3.假設(shè)2A:來自人類驗證者的RL
在此第一種范式下,我們?yōu)槟P吞峁┗谌祟惖莫剟睢N覀兿MP途邆涑壷悄埽虼讼M麑ζ渖筛咏壷悄埽ㄓ扇祟愒u判)的文本進(jìn)行獎勵。
實際上,這類數(shù)據(jù)的收集成本極高。典型的RLHF設(shè)置中,需要訓(xùn)練一個獎勵模型來模擬人類反饋信號。獎勵模型是必要的,因為它們使我們能夠提供遠(yuǎn)超實際人類反饋量的反饋。換言之,它們是計算上的輔助工具。我們將把獎勵模型視為工程細(xì)節(jié),暫且忽略它們。
因此,設(shè)想這樣一個世界:我們擁有無限數(shù)量的人類來為LLM標(biāo)注數(shù)據(jù),并提供任意獎勵,其中高獎勵意味著模型的輸出更接近超級智能。

圖|“一千只猴子在一千臺打字機前工作。很快,它們將寫出人類歷史上最偉大的小說。”——伯恩斯先生,《辛普森一家》
忽略所有程序復(fù)雜性。假設(shè)這種方法能夠?qū)崿F(xiàn)大規(guī)模應(yīng)用(盡管目前可能無法實現(xiàn),但未來或許可行)。這會有效嗎?一個僅通過人類獎勵信號學(xué)習(xí)的機器,能否沿著智能階梯不斷進(jìn)步,并最終超越人類?
換個方式問:我們能否“驗證”超級智能的存在,即便我們自己不能生成它?記住,人類從定義上來說不是超級智能。但當(dāng)我們看到超級智能時,能否識別出它?我們能否以足夠可靠的方式識別,從而為LLM提供有用的梯度信號,使其可以收集大量此類反饋自我提升至超級智能?
有人會指出“生成自然會比驗證更難”。你看一部好電影時就知道它好,但這并不意味著你可以自己去制作一部。這種二分法在機器學(xué)習(xí)中經(jīng)常出現(xiàn)。區(qū)分貓的照片和狗的照片在計算上要比生成完整的貓容易得多。
同樣地,如果人類能夠驗證超級智能,那么可能可以通過RLHF來訓(xùn)練一個超級智能模型。以具體例子來說,你可以讓一個LLM撰寫大量小說,根據(jù)人類對“好小說”的定義對其進(jìn)行獎勵,然后多次重復(fù)這個過程,直到你得到一個能夠撰寫小說的超級智能機器。
你是否注意到這種邏輯中存在任何問題?
4.假設(shè)2B:來自自動驗證器的RL
最近,人們對使用類似方法訓(xùn)練更好的語言模型感到興奮。
當(dāng)我們讓計算機評估RL算法的階段性性能時,可以使用模型或自動驗證器。對于自動驗證器,可以參考國際象棋或編程場景。我們可以編寫規(guī)則來檢查計算機是否贏得了國際象棋比賽,并在將死對手時給予獎勵。在編程中,我們可以運行單元測試,對編寫符合某些規(guī)格的代碼的計算機給予獎勵。
使用驗證器會更加實用——它將使我們能夠完全去除人類的參與(盡管人類曾用于編寫整個互聯(lián)網(wǎng))。使用驗證器實現(xiàn)超級智能的方案大致如下:
使用SL在大量互聯(lián)網(wǎng)文本上預(yù)訓(xùn)練一個LLM;
將其接入一個能夠為優(yōu)質(zhì)LLM輸出提供獎勵的驗證系統(tǒng);
運行很長時間;
實現(xiàn)超級智能。
這個思路靠譜嗎?它真的可行嗎?
眾所周知,DeepMind的AlphaGo通過RL與SL的結(jié)合實現(xiàn)了“圍棋霸主地位”(即擊敗所有人類選手,甚至那些訓(xùn)練了數(shù)十年的高手)。AlphaGo的第二個版本AlphaGo Zero通過連續(xù)40天與自己對弈來學(xué)習(xí)。

圖|2016年,AlphaGo以四勝一負(fù)的成績擊敗了當(dāng)時的人類圍棋冠軍李世石。最初的AlphaGo是通過SL進(jìn)行訓(xùn)練的。接下來的AlphaGo版本通過RL進(jìn)行學(xué)習(xí):通過自我對戰(zhàn)數(shù)百萬局進(jìn)行學(xué)習(xí)。
需要注意的是,圍棋具有許多現(xiàn)實世界任務(wù)所不具備的重要特性,圍棋具有固有的可驗證性。我們可以將圍棋對局輸入到基于規(guī)則的計算機程序中,并獲得一個信號,指示我是否獲勝。從長遠(yuǎn)來看,你可以根據(jù)某一步棋對游戲以勝利結(jié)束的概率的影響,判斷這一步棋是否“好”。這基本上就是RL的工作原理。
借助這種可驗證性,AlphaGo 實現(xiàn)了AI實驗室長期以來追求的一個重要目標(biāo):AlphaGo 在思考時間更長時表現(xiàn)更佳。語言模型默認(rèn)無法做到這一點。
但這正是OpenAI去年秋季宣布的突破性成果。他們利用可驗證獎勵強化學(xué)習(xí)(RLVR)訓(xùn)練了o1模型,該模型與AlphaGo一樣,能夠通過更長時間的思考產(chǎn)生更優(yōu)的輸出:
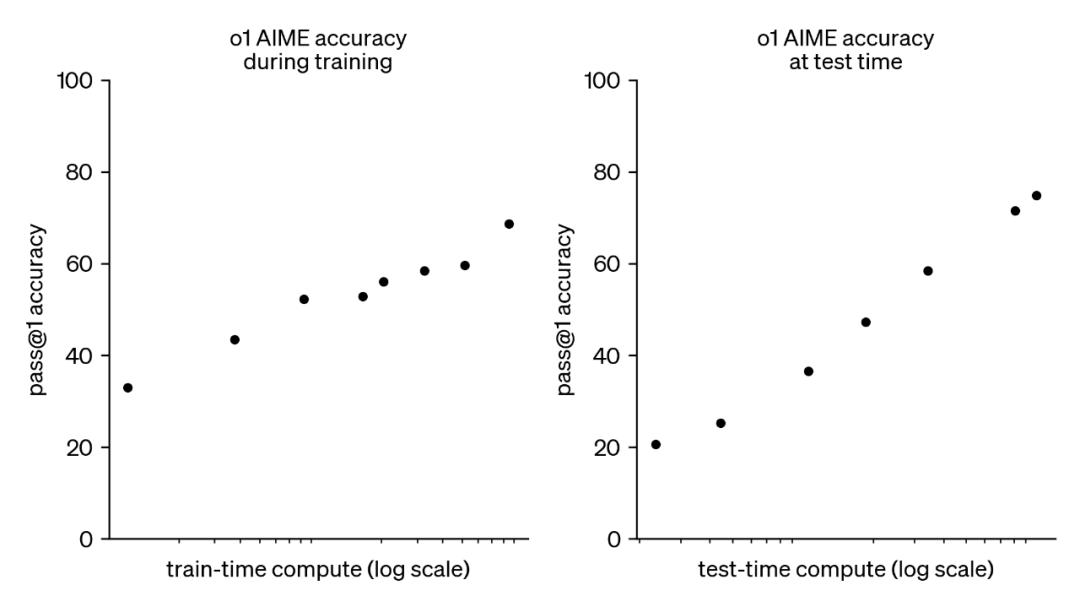
圖|在o1博客文章中,OpenAI介紹了一系列“推理模型”,這些模型通過RLVR進(jìn)行學(xué)習(xí)
觀察上方的美麗圖表(注意對數(shù)x軸!),我們可以看到o1的確隨著思考時間的增加而表現(xiàn)更好。但請注意標(biāo)題:這是在AIME數(shù)據(jù)集上的結(jié)果——AIME是一組極為困難、答案為整數(shù)的數(shù)學(xué)題。換言之,這不是開放式任務(wù),而是可驗證的任務(wù),因為我們可以檢查LLM是否生成正確答案,并據(jù)此獎勵模型。
事實證明,當(dāng)前的LLM在預(yù)訓(xùn)練后能夠很好地處理任意任務(wù),它們可以對AIME問題做出合理的猜測,而我們可以利用RL來訓(xùn)練它們,使其隨著時間的推移做出越來越好的猜測。(最酷的部分,我們在此不做展開,是它們在這一過程中會生成越來越多的“思考token”,從而為我們提供如上文o1博客文章中所示的測試時計算圖。)
5.RLVR是通向超級智能的路徑?
顯然,OpenAI、谷歌和其他AI實驗室對這種基于LLM的RL非常興奮,并認(rèn)為這可能為他們帶來超級智能。我認(rèn)為,這種范式正是Altman在文章最前面模糊推文中提到的內(nèi)容。超級智能的“工程問題”在于構(gòu)建大量適用于不同任務(wù)的RL環(huán)境,并訓(xùn)練LLM同時處理所有這些任務(wù)。
讓我們來分析一下這種樂觀的設(shè)想。我們已知的可驗證任務(wù)包括編程(可以通過運行代碼來驗證其正確性)以及數(shù)學(xué)(不是證明,而是有數(shù)值解的問題)。如果我們能夠收集世界上所有可驗證的事物,并同時對它們進(jìn)行訓(xùn)練(或分別訓(xùn)練,然后進(jìn)行模型合并)——這真的會產(chǎn)生通用超級智能嗎?
這里存在幾個邏輯跳躍。最重要的是,我們并不清楚RL在可驗證任務(wù)上的遷移能力是否能夠有效擴展到其他領(lǐng)域。訓(xùn)練模型解決數(shù)學(xué)問題是否能夠自然地教會它如何預(yù)訂機票?或者,在可驗證環(huán)境中訓(xùn)練模型提升編程能力,是否能使其成為更優(yōu)秀的軟件工程師?
假設(shè)這種情況確實成立,且RL能夠完美遷移到各種任務(wù)上。這將產(chǎn)生巨大影響。人工智能公司將展開軍備競賽,爭奪訓(xùn)練LLM的最豐富、實用且工程設(shè)計精良的任務(wù)集。很可能,有多家公司以這種方式推出“超級智能LLM”。
但這種結(jié)果在我看來似乎不太可能。我猜如果RL確實能夠極好地遷移到其他領(lǐng)域,那我們現(xiàn)在應(yīng)該已經(jīng)知道了。我謙卑的預(yù)測是:LLM將繼續(xù)在訓(xùn)練分布內(nèi)的任務(wù)上變得更好。隨著我們收集更多類型的任務(wù)并進(jìn)行訓(xùn)練,這將產(chǎn)生在廣泛任務(wù)上越來越有用的LLM。但它不會成為一個單一的超級智能模型。
整理:小羊 編審:學(xué)術(shù)君
原標(biāo)題:《OpenAI路線遭質(zhì)疑!Meta研究員:根本無法構(gòu)建超級智能》
本文為澎湃號作者或機構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機構(gòu)觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發(fā)布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

