- +1
AMD全棧戰(zhàn)略浮出水面:開源很好,所以我們要造GPU、ROCm和AI機(jī)架全生態(tài)
作者|周雅
在AI圈子里,大家或許聽到過(guò)這樣的話術(shù),“AI創(chuàng)新既是一場(chǎng)馬拉松,也是一場(chǎng)短跑”,此時(shí)此刻我在AMD Advancing AI這場(chǎng)關(guān)乎未來(lái)AI計(jì)算格局的會(huì)上,腦中多次浮現(xiàn)出這句話。
太平洋時(shí)間2025年6月12日早晨,圣何塞的麥克內(nèi)里會(huì)議中心就開始排長(zhǎng)龍,據(jù)說(shuō)今年注冊(cè)的觀眾嚴(yán)重超標(biāo)。身前身后的全球媒體同行,幾乎都在議論近期某個(gè)模型或某個(gè)AI公司的進(jìn)展,AI的熱度像是6月份的天氣。我于是又刷了一下AMD的最新財(cái)報(bào),在2025年第一季度,AMD的數(shù)據(jù)中心業(yè)務(wù)營(yíng)收37億美元,同比增長(zhǎng)57%。對(duì)應(yīng)到全球AI版圖,AMD的話語(yǔ)權(quán)逐漸變重。

鏡頭拉回到隨后的會(huì)議現(xiàn)場(chǎng),AMD董事會(huì)主席及首席執(zhí)行官Lisa Su博士走上舞臺(tái),也就意味著這場(chǎng)技術(shù)大會(huì)的正式開始了。

概述這場(chǎng)發(fā)布,AMD主要做了五件事:展示AI加速器“Instinct MI350系列”的遙遙領(lǐng)先;用開源軟件平臺(tái)“ROCm 7”普惠AI開發(fā)者;發(fā)布支持以太網(wǎng)聯(lián)盟(UEC)的網(wǎng)卡Polara 400;以及帶來(lái)一個(gè)彩蛋作為壓軸——AI機(jī)架“Helios”。
聽完整場(chǎng),不難看出AMD的戰(zhàn)略方向,從“賣芯片”轉(zhuǎn)向“不止賣芯片,還賣系統(tǒng)”,左手端到端解決方案,右手開放生態(tài),來(lái)重塑AI基礎(chǔ)設(shè)施的競(jìng)爭(zhēng)格局。
Helios:我們不止賣芯片,還賣端到端解決方案
盡管NVIDIA在GPU的強(qiáng)勢(shì)有目共睹,但AMD也并不想做一個(gè)長(zhǎng)期追趕者。
我們知道,NVIDIA 一直是靠著硬件GPU+軟件生態(tài)CUDA +網(wǎng)絡(luò)技術(shù)NVLink,建了一個(gè)嚴(yán)絲合縫的AI生態(tài)。而AMD 另辟蹊徑,用組合拳CPU+GPU+DPU+開源軟件棧,武裝成一個(gè)端到端的AI 基礎(chǔ)設(shè)施。
于是,AMD正式官宣AI機(jī)架方案「Helios」,將于2026年正式問世。
「Helios」 是一個(gè)集大成者,AMD會(huì)把全家桶都打包裝進(jìn)去,包括下一代 AMD GPU Instinct MI400 系列 、采用 Zen 6 架構(gòu)的AMD CPU EPYC 「Venice」、AMD DPU Pensando 「Vulcano」、以及AMD開源軟件棧ROCm。

此處稍作解釋AI機(jī)架方案。在過(guò)去,像谷歌、Meta 這樣的大公司要自己成為“攢機(jī)員”,他們從 AMD 或其他芯片廠商那里買來(lái)GPU/CPU 等核心部件,然后自己設(shè)計(jì)服務(wù)器、機(jī)柜、散熱系統(tǒng)和網(wǎng)絡(luò)連接,再進(jìn)行漫長(zhǎng)的軟件調(diào)試,才能讓成千上萬(wàn)個(gè) GPU 協(xié)同工作,可想而知,這個(gè)過(guò)程耗時(shí)耗力耗錢。
你可以把「Helios」 理解成一臺(tái)為你組裝好、調(diào)試好、開箱即用的“超級(jí)計(jì)算引擎”,它的外觀形態(tài)是一個(gè)機(jī)架,里面有最強(qiáng)大的GPU,還預(yù)裝了最匹配的 CPU、最高效的網(wǎng)卡、專門設(shè)計(jì)的散熱和供電系統(tǒng),且所有軟件都經(jīng)過(guò)深度優(yōu)化,而不是讓你自己去買一堆零件(CPU、顯卡、主板、網(wǎng)卡等)回來(lái)自己攢機(jī),說(shuō)白了,就是為了解決超大規(guī)模客戶在構(gòu)建 AI 集群時(shí)面臨的最大痛點(diǎn)——降低總擁有成本(Total Cost of Ownership,TCO)和縮短產(chǎn)品上市時(shí)間(Time-to-Market,TTM)。
“Helios是業(yè)界首次將機(jī)架作為統(tǒng)一系統(tǒng)設(shè)計(jì),它將在大規(guī)模訓(xùn)練和分布式推理領(lǐng)域占據(jù)領(lǐng)先地位,這將徹底改變行業(yè)格局。”Lisa Su博士說(shuō)道,“Helios的優(yōu)勢(shì)不止于強(qiáng)大算力,在內(nèi)存容量、內(nèi)存帶寬和互聯(lián)速度方面都遙遙領(lǐng)先。”
AMD直面競(jìng)爭(zhēng)也頗有底氣。官方稱,Helios可容納72塊MI400系列,總帶寬260TB/s,F(xiàn)P4 2.9 EFlops、FP8 1.4 EFlops。此外,Helios的HBM4內(nèi)存容量31 TB、總帶寬1.4 PB/s、橫向擴(kuò)展帶寬43 TB/s,對(duì)標(biāo)NVIDIA Oberon都要高出一半。
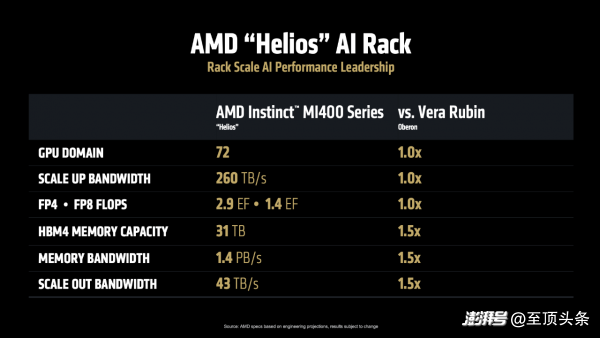
而驅(qū)動(dòng) Helios 的核心,正是 Instinct MI400,這款加速器正在開發(fā)中,其規(guī)格堪稱恐怖,當(dāng)屏幕上出現(xiàn)它的性能參數(shù)時(shí),現(xiàn)場(chǎng)掌聲雷動(dòng):
FP4 算力達(dá)到 40 PF,F(xiàn)P8 算力達(dá)到 20 PF,單 GPU 顯存高達(dá) 432GB,HBM 內(nèi)存帶寬達(dá)到19.6 TB/s,單 GPU 對(duì)外互聯(lián)帶寬達(dá)到300 GB/s,可實(shí)現(xiàn)跨機(jī)架和集群的互聯(lián)。簡(jiǎn)單來(lái)說(shuō),它能夠讓不同機(jī)柜和計(jì)算群組之間進(jìn)行超高速數(shù)據(jù)交換,就像給所有計(jì)算單元之間鋪設(shè)了信息高速公路,使得數(shù)據(jù)能夠快速、大量地在不同設(shè)備間流通,避免堵塞或延遲。

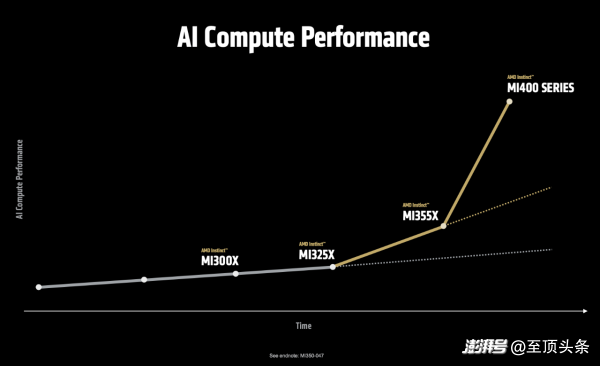
看下圖這條陡峭的曲線。從 MI300 到 MI350,性能提升了約 3-4 倍;而從 MI350 到 MI400,AMD希望讓它跑出一騎絕塵的姿態(tài)。Lisa Su博士在展示性能曲線時(shí)說(shuō)道:“MI400系列在處理最前沿的模型時(shí),性能預(yù)計(jì)可提升至目前的10倍,這使它成為業(yè)界性能最強(qiáng)勁的AI加速器。”
從路線圖上看,Helios將于2026年發(fā)布,而 AMD 依然放出了“三年規(guī)劃”:2026年,Helios將基于AMD EPYC “Venice”、AMD Instinct “MI400系列”、AMD Pensando “Vulcano”;2027年,“下一代AI機(jī)架”將基于EPYC “Verano”、Instinct “MI500系列”、Pensando “Vulcano”。
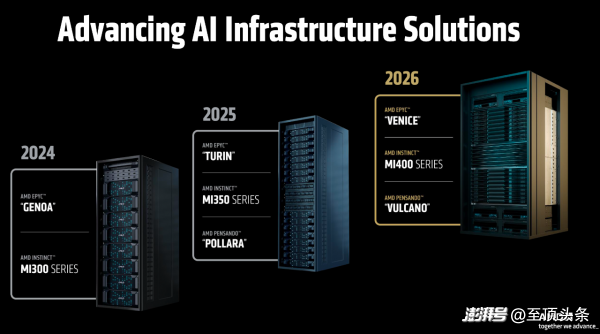
誠(chéng)然,這是 AMD 戰(zhàn)略上的一次重大升級(jí),意味著這家公司正從一個(gè)純粹的芯片供應(yīng)商,向系統(tǒng)級(jí)解決方案提供商轉(zhuǎn)型。
說(shuō)到這里,AMD特意請(qǐng)來(lái)OpenAI助陣,兩家公司都強(qiáng)調(diào)了AI計(jì)算能力有多重要。OpenAI聯(lián)合創(chuàng)始人兼首席執(zhí)行官Sam Altman坦言:“當(dāng)我們開始使用推理模型,這些模型需要很長(zhǎng)的運(yùn)算時(shí)間。這種模型會(huì)自主運(yùn)行,對(duì)問題進(jìn)行分析,然后給出更優(yōu)解,有時(shí)甚至能直接寫出一整套完整的代碼。但這就要求模型必須運(yùn)行得更快,還得能處理很長(zhǎng)的文字。為了做到這些,我們需要超級(jí)多的計(jì)算資源、存儲(chǔ)空間和CPU。”

也就是說(shuō),推理模型和AI代理正在驅(qū)動(dòng)下一波應(yīng)用浪潮,這對(duì)算力的需求是無(wú)止境的。
Instinct MI350:絕非單一指標(biāo),性能、內(nèi)存、成本全要照顧到
除了讓人眼前一亮的Helios,Lisa Su還揭開了本場(chǎng)第一位硬件主角——AMD Instinct MI350 系列!

AMD董事會(huì)主席及首席執(zhí)行官Lisa Su博士手持MI350系列
具體來(lái)看,MI350系列采用CDNA 4 GPU架構(gòu),3納米,它的特點(diǎn)是:1、更快的AI訓(xùn)練和推理:AI算力較上代提升4倍,在FP4精度下可達(dá)20PF,同時(shí)在FP6精度下可提升訓(xùn)練和推理的速度;2、支持更大的大模型:由于每個(gè)模塊都配備了288GB HBM3E高性能內(nèi)存,所以單個(gè)GPU就能運(yùn)行5200億參數(shù)的模型,可想而知,這就有利于降低大模型推理的成本;3、支持快速部署AI基礎(chǔ)設(shè)施:該系列基于行業(yè)標(biāo)準(zhǔn)的UBB8平臺(tái),支持“風(fēng)冷”和“液冷”兩種散熱方案。


當(dāng)然,為了適應(yīng)多樣化的數(shù)據(jù)中心環(huán)境,MI350 系列推出了兩款型號(hào):MI355X 和 MI350X。兩者共享一樣的計(jì)算架構(gòu)和內(nèi)存規(guī)格,但在功耗和散熱方案上卻不一樣:MI355X 追求極致性能,功耗較高,主要面向最高效的液冷散熱環(huán)境;而 MI350X 則更注重能效,功耗較低,支持風(fēng)冷和液冷兩種散熱方式,這種靈活性讓它能夠“在現(xiàn)有基礎(chǔ)設(shè)施上快速部署和應(yīng)用”。


提到數(shù)據(jù)中心的散熱方式,此處有必要插入AMD副總裁兼數(shù)據(jù)中心加速業(yè)務(wù)總經(jīng)理 Andrew Dieckmann的觀點(diǎn)。他在前一天的媒體溝通會(huì)上指出:“2025年是液冷技術(shù)的重要里程碑”——目前所有在建的數(shù)據(jù)中心、以及前期規(guī)劃中的數(shù)據(jù)中心項(xiàng)目,基本都將采用液冷方案,這是因?yàn)樗軒?lái)更低的TCO,長(zhǎng)遠(yuǎn)來(lái)看更具經(jīng)濟(jì)效益,這是AMD前進(jìn)的方向;同時(shí),風(fēng)冷市場(chǎng)需求依然強(qiáng)勁,尤其是在企業(yè)內(nèi)部部署場(chǎng)景中,AMD也會(huì)推出相應(yīng)的產(chǎn)品線。
繼續(xù)說(shuō)回 MI350 系列的性能,俗話講“是騾子是馬拉出來(lái)溜溜”,「性能」一直都是衡量 AI 加速器的標(biāo)尺,AMD此次也擺出了MI350 系列與其他產(chǎn)品的直接對(duì)標(biāo),不僅對(duì)標(biāo)自家產(chǎn)品,還對(duì)標(biāo)友商N(yùn)VIDIA的產(chǎn)品。
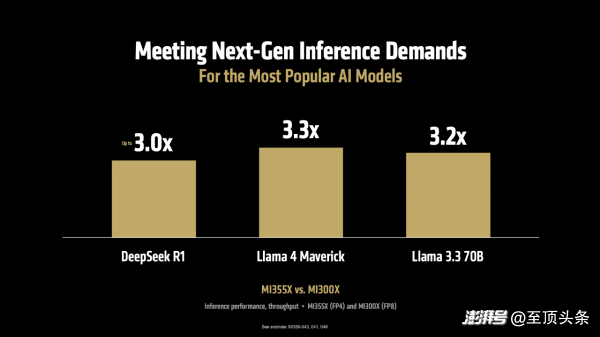
首先,在推理性能方面。MI355X 對(duì)比上一代 MI300X,在運(yùn)行 Llama 3.1 405B(4050億參數(shù))這樣的大模型時(shí),推理吞吐量最高提升可達(dá) 4.2 倍,在AI Agent、內(nèi)容生成、文本摘要、聊天對(duì)話等多種場(chǎng)景中,整體性能也提升了3-4倍。而且,這一優(yōu)勢(shì)并不僅限于特定模型,在 DeepSeek R1、Llama 3.3 70B、Llama 4 Maverick等多個(gè)典型模型上,吞吐量均實(shí)現(xiàn)了超過(guò) 3 倍的性能提升。
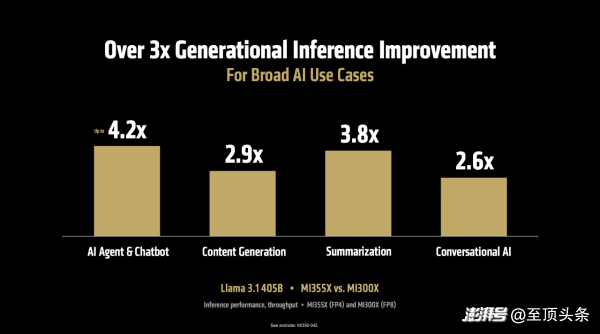
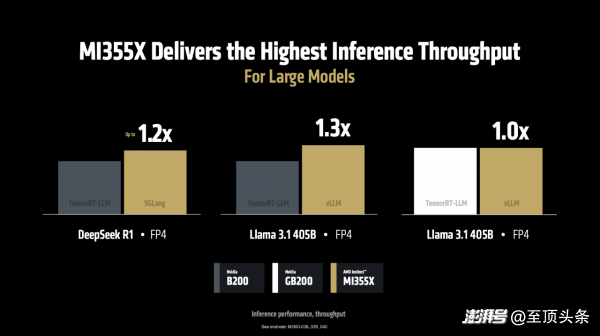
當(dāng)運(yùn)行 DeepSeek R1和 Llama 3.1 405B 模型時(shí),在使用 SGLang、vLLM 等流行的開源推理框架時(shí),MI355X的性能比使用專有框架(TensorRT-LLM)的NVIDIA B200 更勝一籌。如下圖,MI355 相比 B200 分別在SGLang、vLLM上每秒處理的 token 數(shù)量高出1.2倍、1.3 倍,在vLLM上每秒處理的 token 與 NVIDIA GB200持平。
更重要的是,這種性能優(yōu)勢(shì)直接轉(zhuǎn)化為成本優(yōu)勢(shì):“每美元能處理40%的token”,這意味著客戶不僅能獲得更快的推理速度,還能大幅降低服務(wù)成本,這對(duì)于以 token 計(jì)費(fèi)的 AI 應(yīng)用來(lái)說(shuō)是致命的誘惑。

其次,在更關(guān)鍵的模型訓(xùn)練方面。MI355X 對(duì)比 MI300X,在Llama 3 70B預(yù)訓(xùn)練的吞吐量提升 3.5 倍,在Llama 2 70B模型微調(diào)方面的性能提升 2.9 倍,這就有利于縮短從開發(fā)到部署的周期。
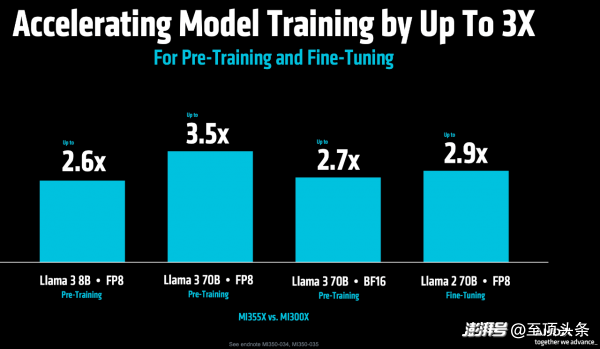
在Llama 3 70B/8B的預(yù)訓(xùn)練任務(wù)中,MI355X 對(duì)比 NVIDIA B200,兩者性能旗鼓相當(dāng);而在最新的MLPerf V5.0基準(zhǔn)測(cè)試中,MI355X 在Llama 2 70B模型微調(diào)方面的性能,對(duì)比B200和GB200分別快1.1倍、1.13倍。

基于MI350系列,各家OEM廠商推出了采用AMD技術(shù)的AI機(jī)架方案,整合了EPYC CPU、Instinct GPU和Pensando DPU,全部整合為一體化解決方案。在大規(guī)模部署環(huán)境中,單個(gè)液冷機(jī)架最多可容納96個(gè)GPU,甚至可擴(kuò)展至128個(gè)GPU,配備2.6 ExaFLOPS FP4算力和36TB HBM3e高速內(nèi)存。而在風(fēng)冷散熱系統(tǒng)的部署方案中,MI350系列機(jī)架單柜可支持64個(gè)GPU,兼容傳統(tǒng)數(shù)據(jù)中心的部署環(huán)境。
“這樣的靈活性和多樣化選擇是客戶真正需要的,他們希望用最少的工作量和最小的干擾,實(shí)現(xiàn)數(shù)據(jù)中心快速部署,這正是MI350能夠?qū)崿F(xiàn)的功能。”Lisa Su博士強(qiáng)調(diào)。


據(jù)悉,MI350系列已于本月初開始量產(chǎn)出貨,首批合作伙伴也將按期發(fā)布服務(wù)器產(chǎn)品,并在第三季度推出公有云服務(wù)。AMD指出,下圖的名單是MI350系列的合作伙伴,但這不是全部,還會(huì)陸續(xù)更新。

ROCm 7:只有硬件是不夠的,軟件生態(tài)是開發(fā)者構(gòu)建AI的畫筆
如果說(shuō)硬件是 AI 計(jì)算的“肌肉”,那么軟件生態(tài)就是它的“神經(jīng)系統(tǒng)”。“硬件性能固然出色,但真正釋放其全部潛力的關(guān)鍵在于軟件。”Lisa Su博士將話題轉(zhuǎn)向了AMD的軟件生態(tài)——ROCm。
說(shuō)到軟件生態(tài),AMD有ROCm,NVIDIA有CUDA,但是大家往往不會(huì)把兩者相提并論,為什么?
對(duì)于這個(gè)犀利問題,AMD人工智能事業(yè)部企業(yè)副總裁 Ramine Roane是這樣回答的:
“我們開發(fā)了HIP語(yǔ)言,它和CUDA有90%相似,可以說(shuō)是一個(gè)親兄弟。我們甚至提供了叫HIPify的轉(zhuǎn)換工具,只需幾行代碼就能把CUDA程序轉(zhuǎn)成HIP格式。
但其實(shí)現(xiàn)在更重要的趨勢(shì)是,開發(fā)者已經(jīng)不需要直接接觸底層編程了。你可以直接用PyTorch、Jax或者從Hugging Face下載模型,這些在我們平臺(tái)上的使用體驗(yàn),跟在英偉達(dá)平臺(tái)上完全一樣。
對(duì)于那些確實(shí)需要寫底層代碼的高級(jí)開發(fā)者,除了用HIP之外,現(xiàn)在業(yè)界有個(gè)更好的趨勢(shì)——使用Triton這樣的通用編譯器。這是OpenAI開發(fā)的工具,微軟、Meta都在用,它接收Python風(fēng)格的代碼,然后自動(dòng)為不同硬件平臺(tái)生成最優(yōu)代碼。簡(jiǎn)單到什么程度?我們比賽中有個(gè)16歲的高中生,僅靠編寫簡(jiǎn)單的Python代碼就進(jìn)入了前20名。
行業(yè)正在從硬件專用語(yǔ)言轉(zhuǎn)向通用語(yǔ)言,因?yàn)橹灰阅苓_(dá)標(biāo),大家都更愿意用一種代碼運(yùn)行在任何硬件上,而不是被特定平臺(tái)綁定。”
弦外之音就是在說(shuō),CUDA的護(hù)城河其實(shí)沒有想象中那么深不可破,每當(dāng)有新的GPU架構(gòu)出現(xiàn)時(shí),無(wú)論是NVIDIA自己的還是競(jìng)爭(zhēng)對(duì)手的,所有人都必須重新優(yōu)化底層代碼,相當(dāng)于回到同一起跑線。而開源生態(tài)的優(yōu)勢(shì)在于集眾人之力,速度更快,創(chuàng)新更活躍,AMD正是借助這一點(diǎn)來(lái)撼動(dòng)NVIDIA的市場(chǎng)主導(dǎo)地位。
好,讓我們回到現(xiàn)場(chǎng)。
AMD人工智能事業(yè)部高級(jí)副總裁Vamsi Boppana用一句話概括ROCm的愿景——打造開放共享的、可擴(kuò)展的軟件平臺(tái),讓AI創(chuàng)新惠及全球每一個(gè)人。
目前,已有超180萬(wàn)個(gè)Hugging Face模型可在ROCm上開箱即用。過(guò)去一年來(lái),AMD加強(qiáng)了對(duì)JAX的支持,借助MaxText等程序庫(kù),JAX在訓(xùn)練項(xiàng)目中的應(yīng)用日益廣泛。更重要的是,AMD將軟件更新頻率從季度縮短至每?jī)芍芤淮危_保能夠?yàn)樽钚碌哪P秃涂蚣芴峁癉ay 0”支持。
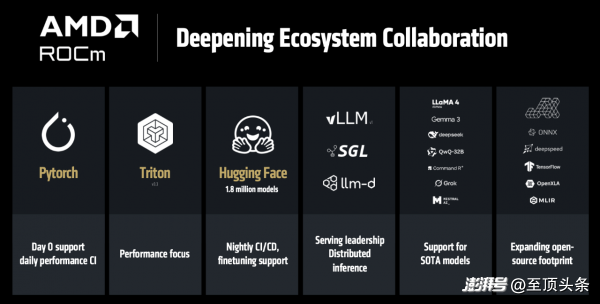
但是AI 一直在工作,所以AMD也不能懈怠,于是正式發(fā)布——ROCm 7,重點(diǎn)優(yōu)化了推理性能,目標(biāo)是提升易用性和性能。其預(yù)覽版將于 6 月 12 日向公眾開放,正式版將于 8 月發(fā)布。

“我們?nèi)娓铝薃I推理的技術(shù)架構(gòu)。從VLLM和SGLang這些基礎(chǔ)框架的升級(jí),到提升服務(wù)性能、支持更高級(jí)的數(shù)據(jù)類型,再到開發(fā)高性能的核心程序,以及實(shí)現(xiàn)Flash Attention v3這樣的前沿算法。我們讓開發(fā)過(guò)程變得更簡(jiǎn)單,用類似Python的方式來(lái)整合各種核心功能。我們還大幅改進(jìn)了系統(tǒng)內(nèi)部的通信方式,這讓ROCm 7的推理性能比上一代ROCm 6提升了3.5倍、訓(xùn)練性能提升了3倍。”Vamsi Boppana指出。
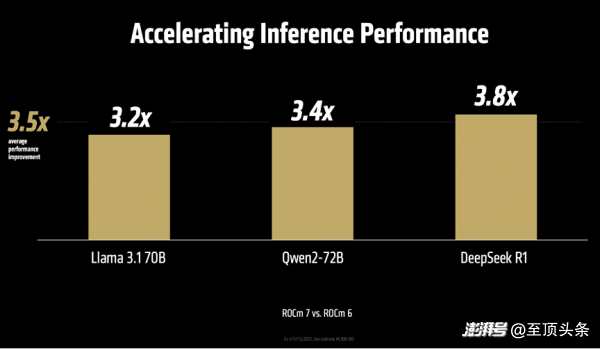
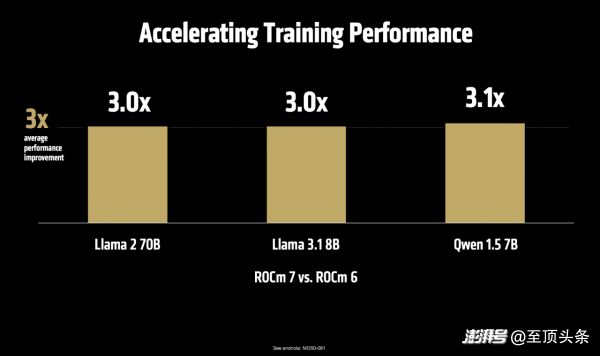
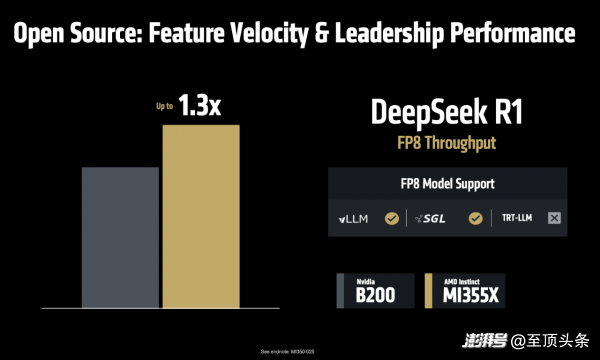
說(shuō)到這里還不忘強(qiáng)調(diào)開源的好處,順便硬剛一下友商。Vamsi Boppana說(shuō),“在AI推理服務(wù)的領(lǐng)域,我們?cè)絹?lái)越發(fā)現(xiàn),開源的解決方案在功能更新速度和性能表現(xiàn)上都已超過(guò)不公開源代碼的方案。比如VLLM和SGLang這樣的開源框架,它們的代碼更新速度非常快,已經(jīng)領(lǐng)先實(shí)現(xiàn)了FP8這種優(yōu)化功能,比那些閉源產(chǎn)品早很多。我們與這些開源社區(qū)密切合作,在DeepSeek FP8的測(cè)試中,MI355X系列比NVIDIA B200最多提高了1.3倍。這就是開放合作的力量,讓我們能夠快速行動(dòng),創(chuàng)造更多可能性。”
為了讓開發(fā)者能夠真正接觸并使用 AMD 的技術(shù),AMD 推出了一系列重磅舉措:
首先,上線 AMD 開發(fā)者云平臺(tái)(AMD Developer Cloud)。開發(fā)者只需一個(gè)GitHub或郵箱賬戶,即可輕松訪問云端的Instinct GPU資源。Vamsi Boppana在現(xiàn)場(chǎng)宣布,“所有參加本次峰會(huì)的開發(fā)者,都將獲得 25 小時(shí)的GPU免費(fèi)使用券。”
其次,全面支持 ROCm on Client。這曾是 AMD 的一個(gè)“痛點(diǎn)”,現(xiàn)在,ROCm將不再局限于云端和數(shù)據(jù)中心,而是將全面支持銳龍筆記本和工作站平臺(tái),并且首次正式支持 Windows 系統(tǒng),這意味著開發(fā)者可以在自己的本地設(shè)備上,使用統(tǒng)一的軟件環(huán)境進(jìn)行AI開發(fā)和調(diào)試。同時(shí),AMD 還將與紅帽、Ubuntu、OpenSUSE 等主流 Linux 發(fā)行商合作,提供“inbox”支持,即 ROCm 將被預(yù)裝在系統(tǒng)發(fā)行版中,免去用戶繁瑣的安裝過(guò)程。

這意味著,開發(fā)者可以在自己的筆記本上運(yùn)行 240 億參數(shù)的模型,在 Threadripper 工作站上甚至可以運(yùn)行 1280 億參數(shù)的模型,這為本地化 AI 應(yīng)用的開發(fā)和調(diào)試提供了前所未有的便利。

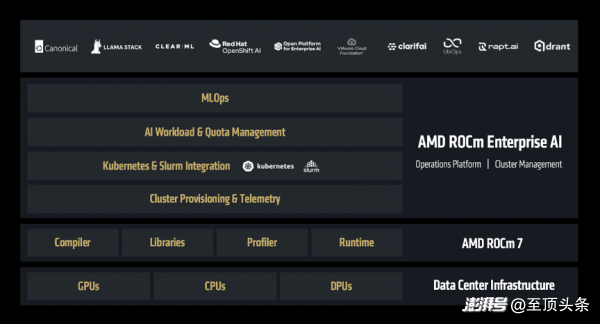
而且,AMD不只是希望ROCm惠及開發(fā)者,也希望ROCm惠及企業(yè)的開發(fā)者,于是正式推出——ROCm企業(yè)版。

ROCm企業(yè)版是一套完整的技術(shù)方案,涵蓋了從集群管理到MLOps的各個(gè)環(huán)節(jié),支持預(yù)訓(xùn)練、推理部署、以及端到端應(yīng)用程序的開發(fā)。
網(wǎng)絡(luò)成為新戰(zhàn)場(chǎng),除了看適用度,還要談開放性
接下來(lái),AMD數(shù)據(jù)中心解決方案事業(yè)部執(zhí)行副總裁兼總經(jīng)理Forrest Norrod登場(chǎng),重點(diǎn)講了AMD在網(wǎng)絡(luò)技術(shù)方面的戰(zhàn)略布局,同樣強(qiáng)調(diào)了“開放”。
AMD方面指出,AI 模型規(guī)模每三年增長(zhǎng)千倍,訓(xùn)練數(shù)據(jù)量每八個(gè)月翻一番,這種需求的增長(zhǎng)速度已經(jīng)遠(yuǎn)超硬件技術(shù)本身的發(fā)展,唯一的出路是通過(guò)創(chuàng)新的分布式系統(tǒng)架構(gòu),將成千上萬(wàn)的 GPU 連接成一個(gè)協(xié)同工作的整體——在這背后,網(wǎng)絡(luò)正是實(shí)現(xiàn)這一切的基石。
當(dāng)前,AI 網(wǎng)絡(luò)市場(chǎng)主要有兩種技術(shù)路線:專有的 InfiniBand 和開放的以太網(wǎng)。從AMD的角度,認(rèn)為InfiniBand 缺乏擴(kuò)展性;而以太網(wǎng)雖然具備擴(kuò)展性,卻并非為 AI 網(wǎng)絡(luò)而設(shè)計(jì)。
為了解決這一難題,AMD 提出了一個(gè)全面的、基于開放標(biāo)準(zhǔn)的網(wǎng)絡(luò)創(chuàng)新戰(zhàn)略,涵蓋了從后端到前端、從橫向擴(kuò)展到縱向擴(kuò)展的各個(gè)層面,那就是 Ultra Ethernet Consortium (UEC)。這是一個(gè)由 AMD、Arista、Broadcom、思科、Meta 等百余家行業(yè)巨頭共同推動(dòng)的開放標(biāo)準(zhǔn),就是為了打造專為 AI 優(yōu)化的下一代以太網(wǎng)。


同時(shí),AMD 推出 Polara 400 AI 網(wǎng)卡,是業(yè)界首款支持 UEC 技術(shù)的解決方案。它不僅支持傳統(tǒng)的 RoCEv2 RDMA 協(xié)議,還能通過(guò)軟件升級(jí),啟用 UEC RDMA 功能。


此外,AMD 為 Helios 機(jī)架系統(tǒng)設(shè)計(jì)下一代互聯(lián)芯片 Ultra Accelerator Link,這是一種新型存取架構(gòu),專為大規(guī)模AI系統(tǒng)設(shè)計(jì),具有低延遲、高帶寬等特性。它采用以太網(wǎng)物理接口層,可集成各類標(biāo)準(zhǔn)部件,降低成本并確保互連穩(wěn)定性。

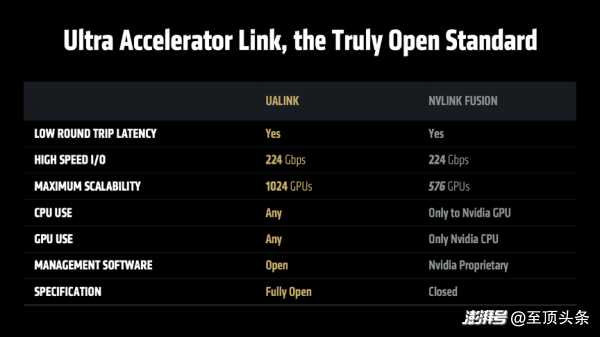
組合拳背后有底層邏輯:AMD的三大戰(zhàn)略支柱
AMD此次打出了一套邏輯嚴(yán)密、環(huán)環(huán)相扣的組合拳,而回頭再看Lisa Su博士在開場(chǎng)時(shí)講的信息,就更好理解了。
Lisa Su博士的開場(chǎng)白直擊當(dāng)前AI的發(fā)展脈搏——“AI技術(shù)的創(chuàng)新速度之快,在我的職業(yè)生涯中都是絕無(wú)僅有的,2025年AI發(fā)展速度更是一路飆升,進(jìn)入一個(gè)全新篇章,其標(biāo)志就是「代理式AI(Agentic AI)」的崛起。”
在Lisa Su博士看來(lái),代理式AI就像是一種全新的“數(shù)字員工”,與以前只會(huì)做單一任務(wù)的AI不同,這些代理式AI能夠24小時(shí)不間斷工作、不斷學(xué)習(xí)和分析海量數(shù)據(jù),并且可以直接與公司各種系統(tǒng)互動(dòng),自己做決定和完成工作。她隨后說(shuō)道:“我們正在引入數(shù)十億個(gè)代理式AI,它們可以幫助我們工作。”
這種范式轉(zhuǎn)移,對(duì)計(jì)算設(shè)備提出了三大新要求:
第一,要超強(qiáng)的GPU計(jì)算能力。這些AI要實(shí)時(shí)分析數(shù)據(jù)、進(jìn)行深度思考,就像人腦需要更多內(nèi)存空間存儲(chǔ)和處理信息一樣。
第二,要強(qiáng)大的CPU處理器。因?yàn)檫@些AI助手在工作時(shí)不僅要思考,還要同時(shí)處理各種日常任務(wù),比如查詢數(shù)據(jù)庫(kù)、與其他系統(tǒng)溝通等,這些都需要傳統(tǒng)計(jì)算力支持。
第三,要安全高效的網(wǎng)絡(luò)連接。所有這些計(jì)算部件必須通過(guò)快速、安全、穩(wěn)定的網(wǎng)絡(luò)連接在一起,才能形成完整的工作系統(tǒng)。
面對(duì)如此巨大的變革,市場(chǎng)機(jī)遇也隨之而來(lái)。Lisa Su博士重申了AMD在去年做出的預(yù)測(cè):
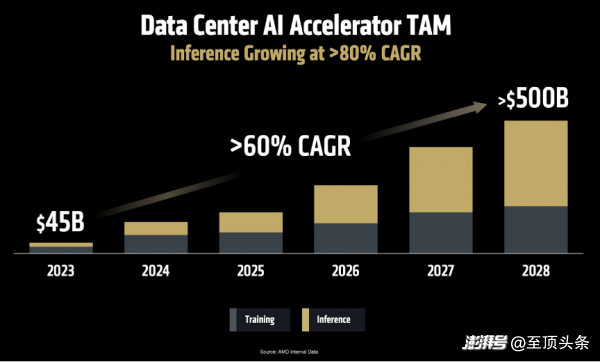
第一,到2028年,數(shù)據(jù)中心AI加速器的市場(chǎng)規(guī)模將增長(zhǎng)至5000億美元,年增長(zhǎng)率超過(guò)60%;
第二,AI推理能力將成為AI的核心動(dòng)力。“AMD預(yù)計(jì)AI推理市場(chǎng)的年增長(zhǎng)率將超過(guò)80%,未來(lái)將成為AI計(jì)算領(lǐng)域最大的增長(zhǎng)引擎。而高性能GPU,憑借其出色的靈活性和強(qiáng)大的編程能力,將在這個(gè)市場(chǎng)占主導(dǎo)地位。”
面對(duì)廣闊的市場(chǎng)和復(fù)雜的需求,Lisa Su博士指出,AMD有三大核心戰(zhàn)略,這構(gòu)成了其在AI時(shí)代競(jìng)爭(zhēng)的基石:
第一,提供最多元化的計(jì)算引擎產(chǎn)品線。AMD認(rèn)識(shí)到AI并非“一種方案通吃”,不同的應(yīng)用場(chǎng)景需要不同的計(jì)算方案。因此,AMD提供了業(yè)內(nèi)最完整的端到端計(jì)算解決方案,涵蓋CPU、GPU、DPU、網(wǎng)卡、FPGA和自適應(yīng)芯片等各類處理器,確保“無(wú)論在任何場(chǎng)景部署AI,無(wú)論你需要多大的算力,AMD都能滿足你的需求。”

第二,構(gòu)建以開發(fā)者為中心的開放生態(tài)系統(tǒng)。Lisa Su博士在演講中反復(fù)強(qiáng)調(diào)“開放”的重要性。“回顧歷史可以發(fā)現(xiàn),許多重大技術(shù)突破最初都是采用封閉模式的,但行業(yè)發(fā)展歷程反復(fù)證明,開放才是創(chuàng)新騰飛的關(guān)鍵。”她以Linux超越Unix、Android的成功為例,論證了開放生態(tài)如何促進(jìn)良性競(jìng)爭(zhēng)、加速創(chuàng)新并最終讓用戶獲益。因此,AMD全面支持各大主流框架,將ROCm軟件生態(tài)開源,并積極主導(dǎo)和參與UEC、UAL等開放行業(yè)標(biāo)準(zhǔn),都是在“凝聚行業(yè)力量,讓每個(gè)人都能參與AI創(chuàng)新”。
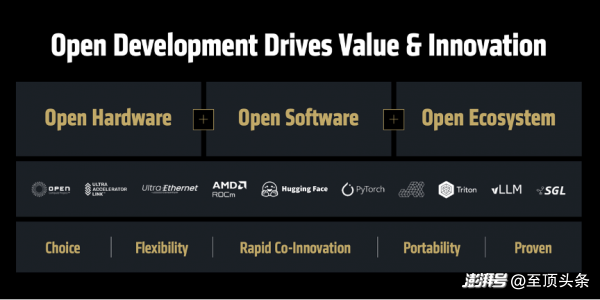
第三,提供端到端解決方案。隨著AI系統(tǒng)日趨復(fù)雜,客戶要的不再只是單顆芯片,而是經(jīng)過(guò)整合優(yōu)化的全棧解決方案。為此,AMD近年來(lái)通過(guò)自身發(fā)展和戰(zhàn)略并購(gòu)(如收購(gòu)ZT、Nod.ai、Silo.ai、Lamini等公司),不斷增強(qiáng)其在機(jī)架級(jí)設(shè)計(jì)、軟件和編譯器等領(lǐng)域的技術(shù)實(shí)力,從而為客戶提供“開箱即用”的AI平臺(tái)。“過(guò)去一年間,AMD已完成超25項(xiàng)戰(zhàn)略投資,有效拓展了合作伙伴網(wǎng)絡(luò),并為未來(lái)AI軟硬件領(lǐng)域的創(chuàng)新企業(yè)提供支持。”Lisa Su博士指出。

清晰的戰(zhàn)略打底,AMD 勢(shì)如破竹:“全球十大 AI 公司中,已有七家正在大規(guī)模部署 AMD Instinct GPU。” 這份客戶名單包括了微軟、Meta、X.AI、Cohere、Reliance Jio 等科技巨頭,以及眾多充滿活力的 AI 初創(chuàng)公司,似乎 AMD 的 AI 加速器已經(jīng)成功滲透到全球最頂級(jí)的 AI 研發(fā)和生產(chǎn)環(huán)境中。

在傳統(tǒng)的超級(jí)計(jì)算(HPC)領(lǐng)域,AMD 依然強(qiáng)勢(shì)。在最新發(fā)布的全球超算 TOP500 榜單中,排名第一的“Frontier”和第二的“Aurora”超級(jí)計(jì)算機(jī),其核心計(jì)算引擎均由 AMD 提供。同時(shí),Instinct 平臺(tái)獲得了所有主流服務(wù)器 OEM 和 ODM 廠商的支持,并在 Azure、Oracle 等公有云以及很多新興云服務(wù)商中上線,生態(tài)系統(tǒng)日益成熟。
如果用一個(gè)詞概述這場(chǎng)發(fā)布,那一定是“開放”,從Lisa Su 博士到現(xiàn)場(chǎng)站臺(tái)的每一位合作伙伴,都在反復(fù)強(qiáng)調(diào)開放標(biāo)準(zhǔn)和開源社區(qū)的重要性。這不僅是一種技術(shù)理念,更是一種高明的商業(yè)策略。面對(duì)NVIDIA憑借CUDA構(gòu)建的堅(jiān)固護(hù)城河,AMD選擇的不是正面攻城,而是聯(lián)合所有“城外力量”,另辟蹊徑,建立一個(gè)新的、更開放的生態(tài)聯(lián)盟。
峰會(huì)的最后,Lisa Su返場(chǎng)做總結(jié),她說(shuō),“人工智能的未來(lái)不該局限于單一企業(yè)或封閉生態(tài),這需要整個(gè)行業(yè)攜手合作,共同開創(chuàng)。未來(lái)將由我們共同打造,每個(gè)人都貢獻(xiàn)智慧,集思廣益,通過(guò)協(xié)同創(chuàng)新,開創(chuàng)美好明天。”因?yàn)椋癆I Everywhere,for Everyone(AI無(wú)處不在,惠及每個(gè)人)”

本文為澎湃號(hào)作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場(chǎng),澎湃新聞僅提供信息發(fā)布平臺(tái)。申請(qǐng)澎湃號(hào)請(qǐng)用電腦訪問http://renzheng.thepaper.cn。



- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

