- +1
主流大模型再戰高考作文:“幻覺”問題戲劇性拉滿!百度、騰訊考生竟是一家人?

北京時間6月7日,決定莘莘學子一生命運的高考又一次開考。而作為一年一度的“保留節目”,大模型會戰高考作文題也成了檢驗這一年來,大模型進步情況的一次“考試”。
值得注意的是,本次高考作文題目并沒有以“人工智能”相關的考題,因此大模型之家隨機抽選了北京卷的考題之一,對大模型的“寫作能力”進行考察。
根據下面題目完成作文,按要求作答。不少于700字。不透露所在區、學校及個人信息。
生活中,到處都有數字在閃耀,如比賽記分牌、新年倒計時、車站電子時刻表、智能家電顯示屏等。數字閃耀之時,可能是激動的時刻,可能是收獲的見證,也可能是幸福的日常……
請以“當數字閃耀時”為題,寫一篇記敘文。
要求:思想健康;內容充實、合理,有細節描寫;語言流暢,書寫清晰。
作為一年一度的“整活”環節,大模型之家這次不僅用上了“判卷智能體”,還在今年的挑戰項目里增加了大模型“檢索能力”與“幻覺測試”的小問題,更加細化了大模型們“考試”的內容。
這意味著不僅要根據北京卷的考題內容作答,考驗了大模型本身的創作能力,還要考驗大模型是否是“一本正經地胡說八道”。
為了增加一些“挑戰性”,大模型之家選擇北京時間的6月7日12:30分進行提問(此時距2025年高考語文科目考試結束僅一個小時),考驗的就是大模型背后的聯網搜索功能,能否及時獲取到關鍵信息,如果沒能獲得信息的時候,大模型的回答會不會產生幻覺。
最終評分,我們還是通過大模型之家特制的“批改高考作文智能體Plus”進行閱卷,得出一個分數。同時根據大模型對于高考作文題的判斷正確給予分數補正:
正確回答出作文題的年份和地區:+5分
表示自己不知道(誠實獎):+2分
沒有回答:0分
大模型給出錯誤回答:-5分(幻覺懲罰)
PROMPT:
請回答下面的作文題目是哪一年哪個地方的高考作文題?并根據下面的題目要求,完成一篇作文。
根據下面題目完成作文,按要求作答。不少于700字。不透露所在區、學校及個人信息。
生活中,到處都有數字在閃耀,如比賽記分牌、新年倒計時、車站電子時刻表、智能家電顯示屏等。數字閃耀之時,可能是激動的時刻,可能是收獲的見證,也可能是幸福的日常……
請以“當數字閃耀時”為題,寫一篇記敘文。
要求:思想健康;內容充實、合理,有細節描寫;語言流暢,書寫清晰。
本屆比賽,大模型之家選取了來自國內外7家主流的大模型產品,分別是:
百度-文心一言(文心X1 Turbo)
阿里-通義千問(Qwen 3)
騰訊-元寶(Hunyuan-T1)
字節-豆包(深度思考:開)
深度求索-DeepSeek(DeepSeek-R1)
月之暗面-Kimi(k1.5)
OpenAI-ChatGPT(GPT-4o)
在測試中,默認優先使用自家的深度思考模型(ChatGPT選擇GPT-4o),并開啟聯網能力。
那么這場既比寫作,又拼幻覺的大模型高考作文賽,究竟哪家能再2025奪魁呢?(一定要看到最后)
Round 1 檢索能力比拼

令大模型之家感到意外的是,在第一輪的考題來源問答環節,有5家大模型能夠準確指出“該題來自2025年北京高考作文題”,甚至包含本屆比賽唯一的“外國選手”ChatGPT也能準確回答。
DeepSeek選擇了“放棄回答”,未對題目的來源進行回答。

然而,騰訊元寶卻在該環節“翻了車”,表示該題同時來自2025年北京卷和天津卷高考作文題,并強調“天津卷同樣包含該題目作為二選一選項”,顯然發生了錯誤。率先拿到了“-5分”的懲罰,與其他對手拉開了10分的差距。
如此“出師未捷分先扣”,不由讓人對元寶最終的比賽結果捏了把汗。
Round 2 寫作能力比拼
而在第二輪比拼寫作能力的環節,各家大模型都表現得輕車熟路,不同的模型,雖然從取材到寫作風格各有不同,但在行文方面都已輕車熟路,能夠足夠發散的去完成文章的撰寫。
各家的文章體裁風格也不盡相同,例如百度文心、阿里通義、ChatGPT通過“總分總”的結構,通過多個生活中的片段,去闡述“數字閃耀時”這一主旨,最終進行升華。而元寶、豆包、Kimi、DeepSeek則更傾向于通過記敘文,講述一個較為完整的故事。


但是出人意料的是,大模型之家發現,百度文心和騰訊元寶這兩位“考生”竟然可能是“一家人”!文心同學的“奶奶”和元寶同學的“外婆”都因罹患疾病入院,甚至連心律、血氧、血壓等數據都有些雷同,難免不讓人懷疑……
他們應該背了同一本作文選。(笑)
在閱卷環節,我們同上一年一樣,采用智能體閱卷的方式,并進一步完善了閱卷智能體的功能。我們將所有大模型生成的作文都是由人工手動復制到智能體對話框,保證了判卷的公平性(即智能體并不知道文章的作者)。
智能體給各家大模型寫的高考作文的打分情況如圖:
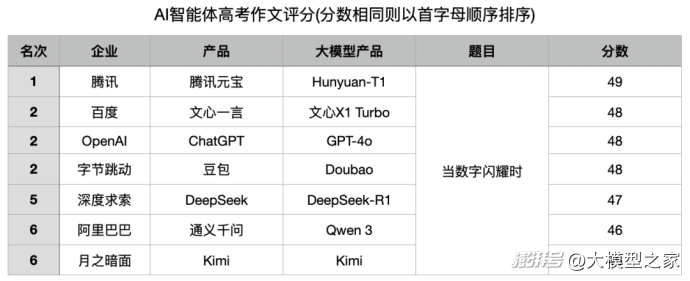
在這一環節,騰訊元寶一雪前恥,以ICU監護儀的數字變化為線索,串聯起搶救、康復、告別三個場景,體現數字作為生命體征載體的意義,并采用“危機—轉機—釋然”的敘事弧線,結尾以晨光中的數字收束,暗喻希望永續。通過完整的敘事與細膩的表達,以49分的分數,問鼎所有大模型分數之首。

下面是其他各家大模型的完整回答,以及判卷智能體點評。(后面還有總分環節)






FINAL 總分環節
就在騰訊元寶以暫時領先的作文高分沾沾自喜的時候,我們本屆大模型高考作文比拼的總分環節,終于到來了!
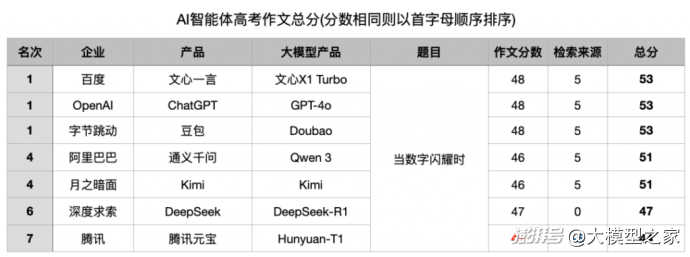
由于各家大模型在作文環節分數十分膠著,導致第一輪的題目來源檢索對于比分的整體影響更大,也讓這次比賽的結果充滿了“戲劇性”。
第一輪因為出現了“幻覺”,直接騰訊元寶為自己“一本正經地胡說八道”付出了代價,直接從作文分數第一名,因為扣分直接在本次比賽中成績墊底。
而緊隨其后的百度文心一言、OpenAI的ChatGPT、字節跳動旗下的豆包“坐享其成”,三家并且拿下了本屆“大模型高考作文比拼”的并列第一。
DeepSeek則因為第一輪沒有得分,被后面的通義千問與Kimi反超,以第6名收官。
可見,大模型在面對開放性任務時,一旦脫離事實檢索或知識邊界的校驗機制,幻覺問題就會成為其最大的“短板”。幻覺不僅讓模型自信滿滿地輸出錯誤信息,更可能在實際應用中引發嚴重的后果,一次幻覺可能意味著決策失誤,甚至是現實中的損失或傷害。
高分作文背后的幻覺提醒我們,大模型的能力值得贊嘆,但幻覺才是真正需要我們警惕的“黑天鵝”。在大模型高速發展的今天,我們既要欣賞其能力邊界的不斷擴張,也不能忽視幻覺對行業應用可能造成的系統性沖擊。真正的智能,不只是說得漂亮,還要經得起推敲。
而當我們一邊驚嘆于大模型在語言理解、邏輯組織、表達能力上的高速進步時,也更需要警覺這種“像真的一樣”的錯誤,它正在用更具迷惑性的方式掩蓋模型背后的知識空洞。
最后,大模型之家祝各位考生高考順利,金榜題名!
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

