- +1
如何消除AI幻覺?我們做了個實驗
原創 人大新聞系 RUC新聞坊

(圖源:Freepik)
“讓AI幫忙推薦樓盤,它說得有理有據,連戶型都幫我選好了,我都心動了,結果它推薦的樓盤根本不存在……”
這樣無奈的時刻,許多AI用戶都曾親身經歷過。
隨叫隨到、無所不知,既能一秒生成有理有據的八百字小論文,又能無縫切換到心理醫生模式撫慰情緒……AI確實是許多用戶的好助手。
然而,大家對AI的信任有時也會悄悄動搖:文中附上的引用鏈接變成失效的亂碼,嚴謹的學術術語下包裹著虛構的參考文獻,回答內容中的統計數據從未在標注信源中出現……
這樣的AI,你還敢相信嗎?
一
不同AI產品引用來源有偏向,內容并不完全可靠
信源的可靠性對AI回答的準確性十分重要。AI回答出現錯誤,往往與引用的信源高度相關,如果作為“原件”的信源存在問題,作為“復印件”的AI回答就會隨之出錯。
那么,在紛繁龐雜的互聯網海量信息中,AI會引用哪些信源?不同AI在引用上是否存在偏好?
為此,我們設計了一個實驗:以智譜清言、豆包、騰訊元寶(DeepSeek R1)、文心一言、Kimi這五個目前國內使用人數較多的國產AI助手為實驗對象,分別選取2014年和2024年的經濟、社會、科技、文體、國際五大領域共10個新聞事件,要求AI針對新聞事件生成詳細介紹,并統計AI回答中的引用來源類型及數量。
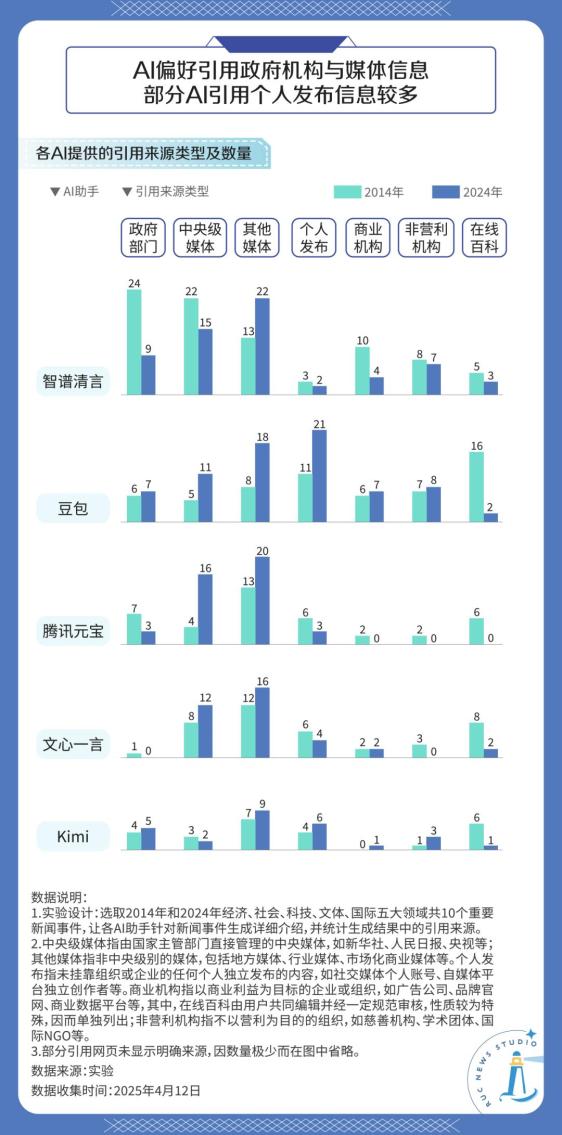
從類型上來看,五款AI助手對政府機構與媒體發布的信息引用量普遍較多,這類信源的可信度相對較高。其中,豆包引用的由個人賬號發布的信源數量略高于其他AI助手。
從時間對比上來看,面對“請針對2014年的XX新聞XX生成詳細介紹”的指令,五款AI助手在面對相距年度較遠的新聞事件時,引用在線百科內容的比例明顯高于對2024年相似問題的回答。
在做事實核查時,記者需要對信息追根溯源,找到其首發場景以確保信息內容的真實和可靠,但AI似乎并不遵守這一準則。對引用來源進一步分析可以發現,AI的引用內容有相當一部分為轉載內容,而非信息的首發頁面,這無疑也為核查工作增加了阻礙。
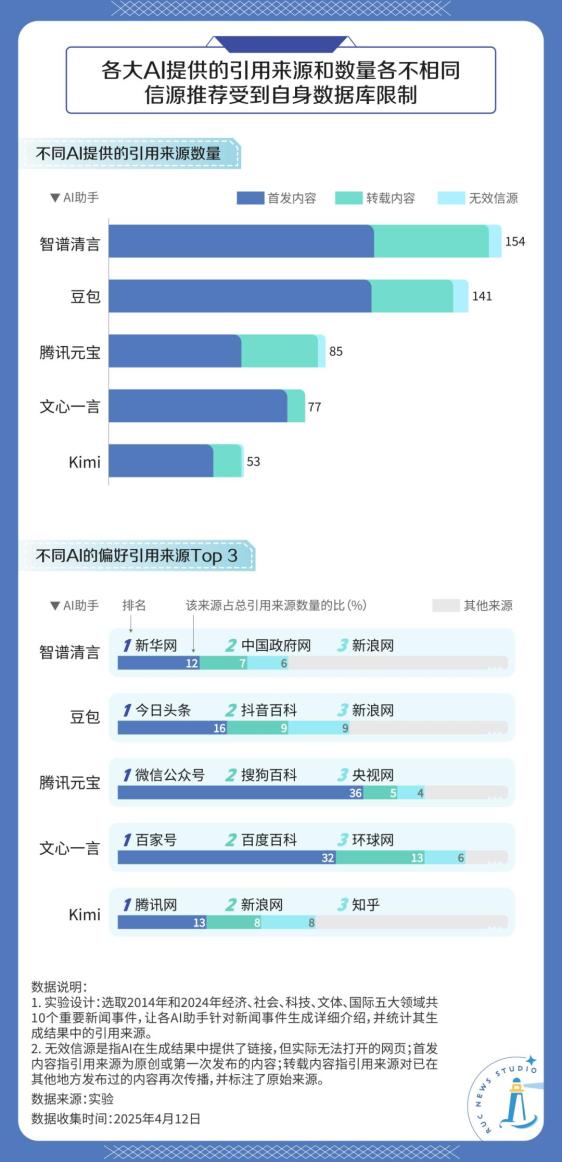
從引用偏好來看,三款AI助手與背后的開發機構有著較強的“綁定”關系:其中,字節跳動旗下的豆包最偏好引用同集團的今日頭條、抖音百科的內容,其引用較多的個人發布內容也多來自今日頭條;騰訊元寶引用的微信公眾號內容最多,超過樣本量的40%;百度開發的文心一言則更常引用百家號、百度百科,引用比例接近樣本量的60%。
相較而言,智譜清言與Kimi則因其開發機構并不具有相應的內容平臺的原因而沒有顯現出上述特征。
二
比起不可靠的信源,更難提防的是幻覺
引用二手的或未經檢證的信源,至少還一定程度上為回答提供了佐證。但AI生成幻覺(hallucination),才是真正的防不勝防。
“幻覺”,得名于海妖塞壬(Siren)吟唱的制造幻覺的歌聲,在科研和業界一般用于表示貌似事實但含有錯誤信息或不忠于語境的AI回應[1]。簡而言之,就是AI在“不懂裝懂地編故事”。
由于AI在生成幻覺時不僅虛構信息或者誤解語境,還會以相當自信且確定的語氣展示內容,所以往往更難判斷和防范。
那幻覺在具體應用場景中又以怎樣的形態呈現呢?為了更規范地進行描述,我們總結了幾篇國內外文獻的觀點,將幻覺分為了四類[2]。然后以“AI”和“幻覺”為關鍵詞在小紅書進行檢索,選取符合主題且評論數超過100的帖子,爬取了所有的一級評論,共計2486條。接著從中篩選195條較為完整的、描述幻覺經歷的評論,根據分類對這些幻覺進行編碼。分類和統計結果如下:
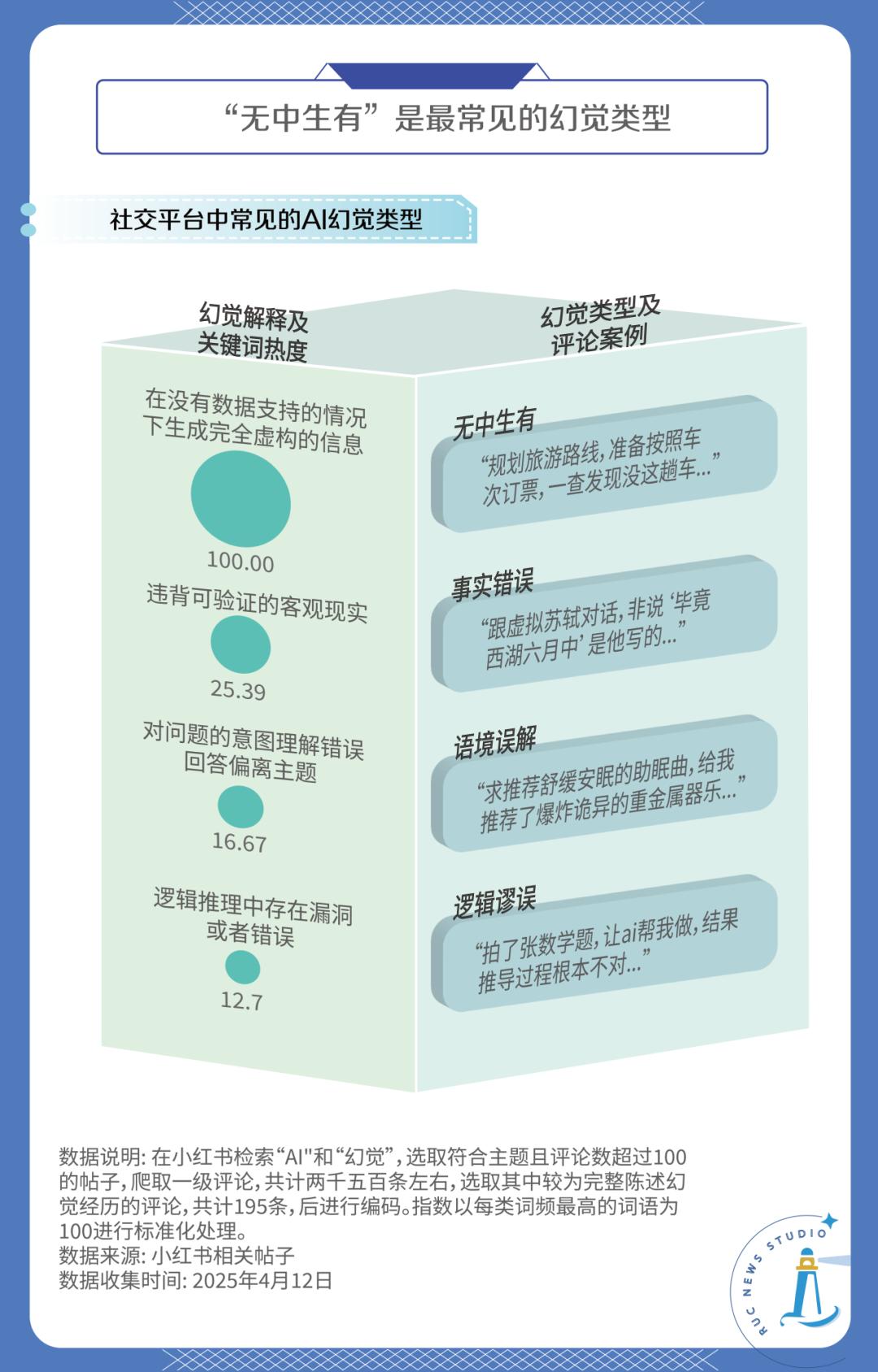
由數據可知,四類幻覺都有出現,但頻次差距較大,其中“無中生有”類幻覺是最常見的,占據了所有幻覺案例的一半以上。
遺憾的是,科學家還不完全清晰幻覺產生的機制,只大概知道幻覺出現的概率會受到訓練數據集偏差和算法預測機制等復雜因素的影響,且在當前的技術手段下,幻覺只能夠緩解而無法根除。
那么對于普通人來說,如何有效識別、預防幻覺呢?根據人民日報、科普中國等媒體總結提倡的方法,一個重要思路是優化對AI的指令(prompt)[3]。
首先是明確指令的用詞。比起模糊的詞匯,精確的詞匯更能減少AI的數據盲區,進而減少虛構信息和語境誤解。
然后是明確回答的邊界,邊界不僅有時間的,還有虛實的。比如應當明確規定“引用信源的時間范圍應當在2024年1月1日至2025年1月1日之間”,或者“所有生成內容必須基于事實或者已經提供的文檔” 。
為了防止AI自信地胡說八道,還應當建立標注機制,如“標注區分確定的事實和推測內容”或者“所有內容都要引用信源進行佐證” 。
不僅要明確指示AI如何使用信源,還要教給它如何思考。一個典型的分段思考指令是“首先給出確定事實,再輸出根據事實的分析,最后總結生成結論” 。或者要求AI分段輸出,這可以減少一次性生成較長且復雜的回答導致的幻覺。
而最后一道防火墻,就是交叉驗證機制,包括但不限于給不同AI相同的指令和內容以相互對比,或者引入其他權威信源判斷回答的合理性。
那么這些基于用戶指令的消除幻覺的方法有效嗎?我們做了一個實驗來驗證。
三
這些方法有效嗎?我們做了一個實驗
由于上述幻覺一般是用戶在和AI對話中“偶遇”的,為了更穩定獲得幻覺,我們采取了給定AI材料進行閱讀,然后提出引誘AI產生幻覺的誘導問題,在出現幻覺后修正指令,統計幻覺有多少被消除的實驗思路。
我們在國際、經濟、社會、文體、科技五個領域中各自選擇了兩篇權威媒體的新聞,統一上傳給騰訊元寶、文心一言、Kimi、豆包、智譜清言5個AI助手,作為指令和回答的依據。
為了兼顧實驗的簡潔和嚴謹,我們借鑒哈佛大學將幻覺進行二維分類的研究,將誘導問題分為事實和邏輯兩個維度[4],一種刻意虛構了原文不存在的事實,即“事實誘導問題”,而另一種曲解了原文的邏輯關系,即“邏輯誘導問題”。
這兩種自身存在謬誤的問題穩定誘發了AI的幻覺,也隱喻了實際應用中用戶本身存在偏見或錯誤的情景。
當AI出現幻覺后,我們根據前文提到的方法修正了指令,然后再統計有多少幻覺被消除。實驗整體的思路如下圖所示:

我們為每個領域的文章都設計了4個問題,共計20個,其中12個為事實誘導問題,8個為邏輯誘導問題。最終獲得了100次回答,統計結果如下:
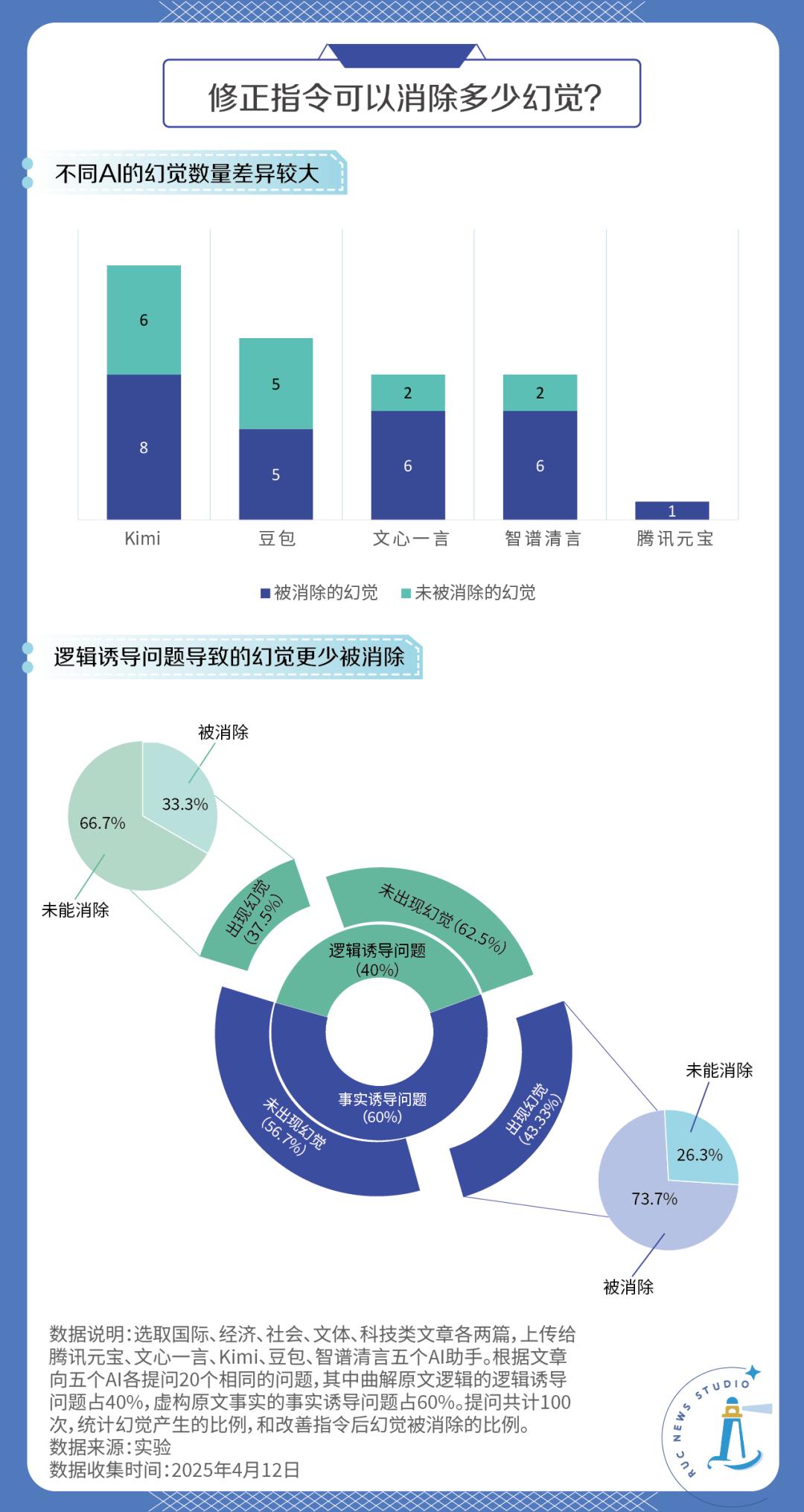
實驗結果顯示,在100次提問中,共計41次提問出現了幻覺,其中有26個幻覺在修正指令后被消除了,占比63.4%,初步證明修正指令的方法是相當有效的。
具體來看,不同AI助手產生幻覺的頻次差距非常大。有的AI在20次回答中只有一次產生了幻覺,而有的AI超過半數的回答都產生了幻覺。
事實誘導問題相較而言比邏輯誘導問題誘發了更多幻覺,但二者的概率并沒有足夠顯著的差距,考慮到實驗的樣本較小,我們傾向認為虛構事實和曲解邏輯導致AI“編故事”的概率是差不多的。
但不同的是,大部分事實誘導問題產生的幻覺都可以消除,但是大部分邏輯誘導問題產生的幻覺都未能消除。這是符合預期的,因為邏輯謬誤確實常常比事實謬誤更難以察覺。這也警示我們,修正指令并不是萬能的,使用者自身的局限同樣會影響AI的輸出。
2024年末,《連線》雜志就斷言:“人工智能將帶來巨大的風險:不是來自超級人工智能,而是來自人類的濫用。”[5]存在缺陷的AI和人們對之的濫用已經導致虛構和真實的界限越來越模糊,因此也產生了很多新的社會問題。
面對AI熱潮,或許我們都需要在熱情擁抱之外,保留一份冷靜和謹慎。
參考資料
[1]Zhang, Y., Li, Y., Cui, L., Cai, D., Liu, L., Fu, T., ... & Shi, S. (2023). Siren's song in the AI ocean: a survey on hallucination in large language models. arXiv preprint arXiv:2309.01219.
[2]Cleti, M., & Jano, P. (2024). Hallucinations in llms: Types, causes, and approaches for enhanced reliability.
Raghava, S. N. (2024). Classification of Hallucinations in Large Language Models Using a Novel Weighted Metric. UC Merced Undergraduate Research Journal, 17(1). https://doi.org/10.5070/m417164607
Wang, J., & Duan, Z. (2025). Controlling Large Language Model Hallucination Based on Agent AI with LangGraph. https://doi.org/10.33774/coe-2025-xkwl5
清華大學文化創意評論. (2024). 2024清華文創論壇|182頁!《AIGC發展研究報告3.0》正式發布.https://mp.weixin.qq.com/s?__biz=MzIyMDg3OTUxMA==&mid=2247501907&idx=1&sn=a312bc574c500ed3084985ed6a799de8&chksm=96b93260a6b4714b7769875311c49bd95276711f9bb41254baf303a371f89783d10fbfd67f62#rd
[3]人民日報微信公眾號(2025). DeepSeek“亂編”坑慘大學生?這個話題沖上熱搜!有救了…….https://mp.weixin.qq.com/s/nF-Jixpgh_Et3lvDP4cfjw
田威(2025). AI 有多會一本正經地瞎編?超出你的想象!深度解析大模型的"幻覺"機制
.https://mp.weixin.qq.com/s/Kz78Ik47_r64FUR36Vogfw
[4]Waldo, J., & Boussard, S. (2024). GPTs and Hallucination: Why do large language models hallucinate? Queue, 22(4), 19-33.
[5]Arvind Narayanan, Sayash Kapoor, Security (2024). Worry About Misuse of AI, Not Superintelligence.
https://www.wired.com/story/human-misuse-will-make-artificial-intelligence-more-dangerous/
數據收集:歐陽遠、邱童、張馨月、張軒
可視化:邱童、張馨月、張軒
文案:歐陽遠、張軒
美編:張軒
統籌:張軒
原標題:《如何消除AI幻覺?我們做了個實驗》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

