- +1
逐鹿大模型|評分一般成本高,OpenAI的GPT-4.1有何戰略意義

OpenAI最新版本的大模型GPT-4.1正式上線。
目前,GPT4.1只在API上供開發者使用,未引入聊天機器人ChatGPT。它共有三個版本,標準版的GPT-4.1, 和兩個小一點的版本GPT-4.1 mini、GPT-4.1 nano。
在當地時間4月14日發布的直播上,OpenAI表示,GPT-4.1擁有比GPT-4o更大的上下文窗口,在“每一個維度”都比4o更好,尤其在寫代碼和遵循指示方面有了長足提升。
其中,GPT-4.1的上下文窗口高達100萬token,相當于能一次性輸入75萬個單詞(比《戰爭與和平》還要長)。這遠高于4o的12.8萬token限制。OpenAI表示,“我們對其進行了訓練,使其在定位相關文本和忽略不同語境中的干擾時,比GPT-4o更可靠。”

雖然OpenAI的新模型總是被寄予厚望,但隨后的評測結果顯示,GPT-4.1只是對GPT-4o的一版小升級,它在一眾指標中都落后于谷歌旗下的Gemini 2.5,并且成本是Deepseek V3的8倍。
文/承天蒙
/01/
上線計劃一改再改
不久前,OpenAI剛宣布,已經發布了兩年的GPT-4將于4月30日起從ChatGPT中退役,被GPT-4o完全取代。GPT-4o正式成為了ChatGPT的默認模型。
GPT-4于2023年3月推出,用于ChatGPT和微軟Copilot聊天機器人。它是OpenAI推出的第一個多模態大模型,可以同時理解圖像和文本,具有劃時代的重要意義。當時,GPT-4的數據規模還很大,訓練成本超過一億美元。在GPT-4這一先行者的引領下,后續一眾多模態大模型也如雨后春筍般冒了出來,開啟了AI大模型百花齊放的新時代。
GPT-4o是GPT-4的后繼版,在寫作、寫代碼、STEM等方面優于GPT-4。不久前,GPT-4o新上線的圖像生成功能大受歡迎,它能提供包括吉卜力工作室風格在內的20余種圖像風格。最近的升級也進一步提高了GPT-4o在遵循指令、解決問題和對話流程上的表現。現在的ChatGPT已經能記住用戶和它說過的每一句話,并參考過去的聊天記錄,提供更加個性化的回復。
此次GPT-4.1全面超越了GPT-4o,與此同時,它還全面超越了OpenAI兩個月前剛剛發布的GPT-4.5。是的,小數點后面的數字已經不重要了,目前的現狀是,OpenAI在GPT-4.5之后推出了性能更優異的GPT-4.1。而更重要的大更新版本GPT-5,宣布難產。

一周前的4月4日,OpenAI的CEO山姆·奧特曼宣布公司旗下發布大模型的計劃有變,將會推出其推理模型o3和一個o4 mini的完整版,GPT-5的發布時間將會推遲。原定5月發布,現在應該會在“幾個月內”發布。奧特曼表示,推遲的部分原因是“順利整合一切比我們想象的更難”。
推出了更先進的小版本更新4.1后,OpenAI也將從7月14日起,下線API中的GPT-4.5,因為“GPT-4.1已經證明可以用更低價格、更少延遲,在眾多關鍵指標上提供類似或更佳的表現。”
GPT大模型從未停止研發和進化。但是在現在行業競爭加劇、眾敵環伺的情況下,OpenAI無疑更新地更頻繁了,推出的大模型版本也更多。能看出來,OpenAI始終希望讓自己與競爭對手保持一定的領先地位,但至少4.1沒有做到這一點。GPT-4.1被評價為“首次在谷歌之后推出了一個遠遠落后于谷歌的版本”。
/02/
強敵環伺
當下,無疑是全世界各大廠商開足馬力逐鹿大模型的時代。谷歌近期發布了Gemini 2.5 Pro,同樣擁有100萬token的上下文窗口,并且在行業評分中名列前茅。Anthropic旗下Cloude 3.7 Sonnet和中國的Deepseek V3升級版同樣也是強勁的競爭對手,在很多指標上都超越了GPT-4.1。
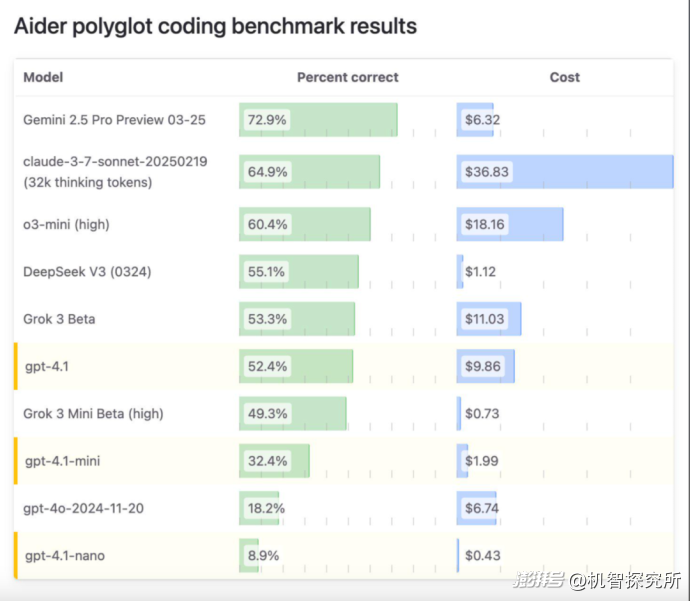
▲知名大模型的代碼的能力和成本比較,GPT4.1在里面排名第6,其中第三名的o3 mini(high)是OpenAI的推理模型
根據OpenAI的內部測試,GPT-4.1 一次可生成token數為32768,多于GPT-4o的16384,在 SWE-bench Verified上的得分介于52%和54.6%之間。但這些數字略低于谷歌Gemini 2.5 Pro的63.8%和Anthropic旗下Claude 3.7 Sonnet的62.3%。
OpenAI也承認,GPT-4.1需要處理的token越多,就越容易出錯。在該公司自己的一項測試中,GPT-4.1的準確率在8000個token時是84%左右,100萬個token時便下降到50%。OpenAI還表示,GPT-4.1比GPT-4o更 “直白”,有時需要更具體、更明確的提示。
更多實測證明,GPT-4.1的編碼能力極強,但總體看來很多情況下打不過Gemini 2.5 pro和Claude 3.7 Sonnet,并且它的價格是Deepseek V3的8倍。在最新Livebench基準評估中,也同樣印證了GPT-4.1推理、編碼、數學實力比Gemini 2.5差。

▲各家廠商每一百萬token成本比較
還有一個需要關注的問題是,分數差這么多,不單純是因為Gemini 2.5 pro比GPT-4.1更高效。谷歌是在自己的ASIC(TPU)上運行的模型,ASIC(TPU)是比GPU專業的芯片,這讓谷歌運行模型的成本比競爭對手低得多,這是谷歌在AI領域軟硬件全面發展的實力。
/03/
大模型往何處去
執行復雜的軟件工程任務,一直是AI大模型訓練的目標。OpenAI首席財務官Sarah Friar此前在一個技術峰會上曾表示,OpenAI的宏偉目標是創建一個“軟件工程師助手”,公司認為,其未來的模型將能夠對整個應用app進行端到端編程,處理包括質量檢測、bug測試和文檔寫作等方面的工作。

▲OpenAI旗下不同GPT模型的跑分比較
GPT 4.1就是朝這個方向邁出的一步。
OpenAI表示,完整的GPT-4.1模型優于GPT-4o和GPT-4o mini模型。GPT-4.1 mini和nano更高效、更快速,但犧牲了一些準確性,OpenAI還表示,GPT-4.1 nano是其有史以來最快速、最便宜的模型。根據網絡評測,GPT-4.1 nano的成本不到Deepseek V3的一半。
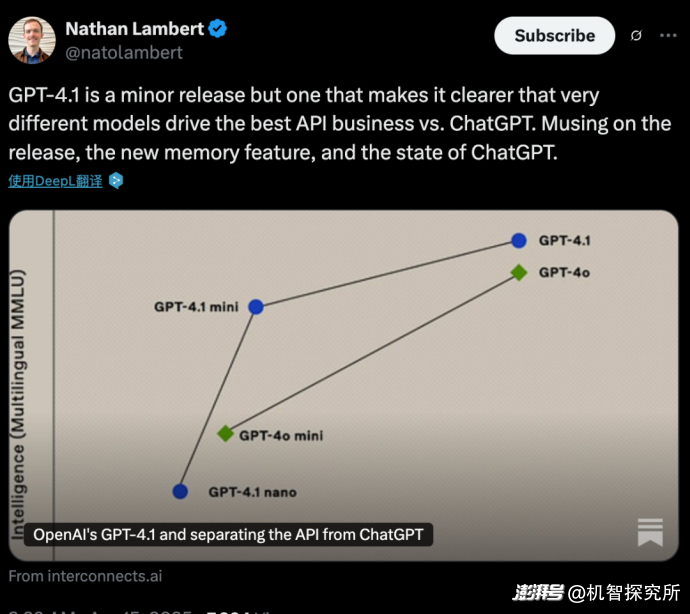
GPT-4.1發布后,AI研究機構Ai2的工程師Nathan Lambert表示,雖然GPT-4.1是一個小版本的更新,但這讓人們更清楚地認識到,推動 API 業務和 ChatGPT 最佳體驗的是兩個截然不同的模型。
在通用大模型的基礎上,區分API業務和ChatGPT,推出多版適合不同場景、不同版本、各有長處的模型,可以起到降低成本、提高效率的作用,這同樣成為了OpenAI未來大模型的發展方向。照此看來,GPT-4.1也許是未來OpenAI發展不同大模型產品線的重要一步。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

