- +1
世界環境日|AI升級,算力狂飆,地球能承受嗎?
生成一張圖片,需要多少電力?
本文的封面圖由DeepSeek與豆包聯合生成,僅使用一條文字指令和一次圖像請求。手機電量幾乎未變,但背后的實際能耗,足夠讓它從零充滿一次。
從上游的芯片制造到下游的日常使用,人工智能發展的每個環節都需要消耗大量生態資源。

此外,一家半導體制造廠每小時的用電量足以讓100個人用上一整年;一家芯片企業每年會造成200萬噸的碳排放,相當于30萬輛重型卡車全年的排放量。
GPT-3的誕生同樣代價不菲:它單次訓練耗電1287萬度,產生552噸碳排放——為了讓AI的大腦變得更聰明,人類先付出了能讓一輛特斯拉汽車完整充電10000次的電量和制造325噸粗鋼的碳排放。
這些生態污染與資源消耗雖然發生在不同環節,但最終都離不開一個共同的場所:數據中心。芯片制造出來供誰使用?模型訓練在哪里完成?用戶調用如何響應?事實上,看似輕盈的輸出結果背后,是一座座體量龐大且能耗驚人的數據中心在晝夜不停地運轉。
AI背后的算力“心臟”
AI不是憑空運行,從模型訓練到推理應用,都需要數據中心強大的算力支撐。可以說,數據中心就是AI系統的“心臟”,支撐著其持續運作,因此也成為了能耗和污染最集中的環節。
在各類數據中心中,企業和互聯網數據中心與AI的關系較為密切。它們集中部署了成千上萬塊高性能GPU(圖形處理器),專為深度學習模型的訓練而設計,是ChatGPT、Deepseek等生成式AI服務得以落地的算力底座。
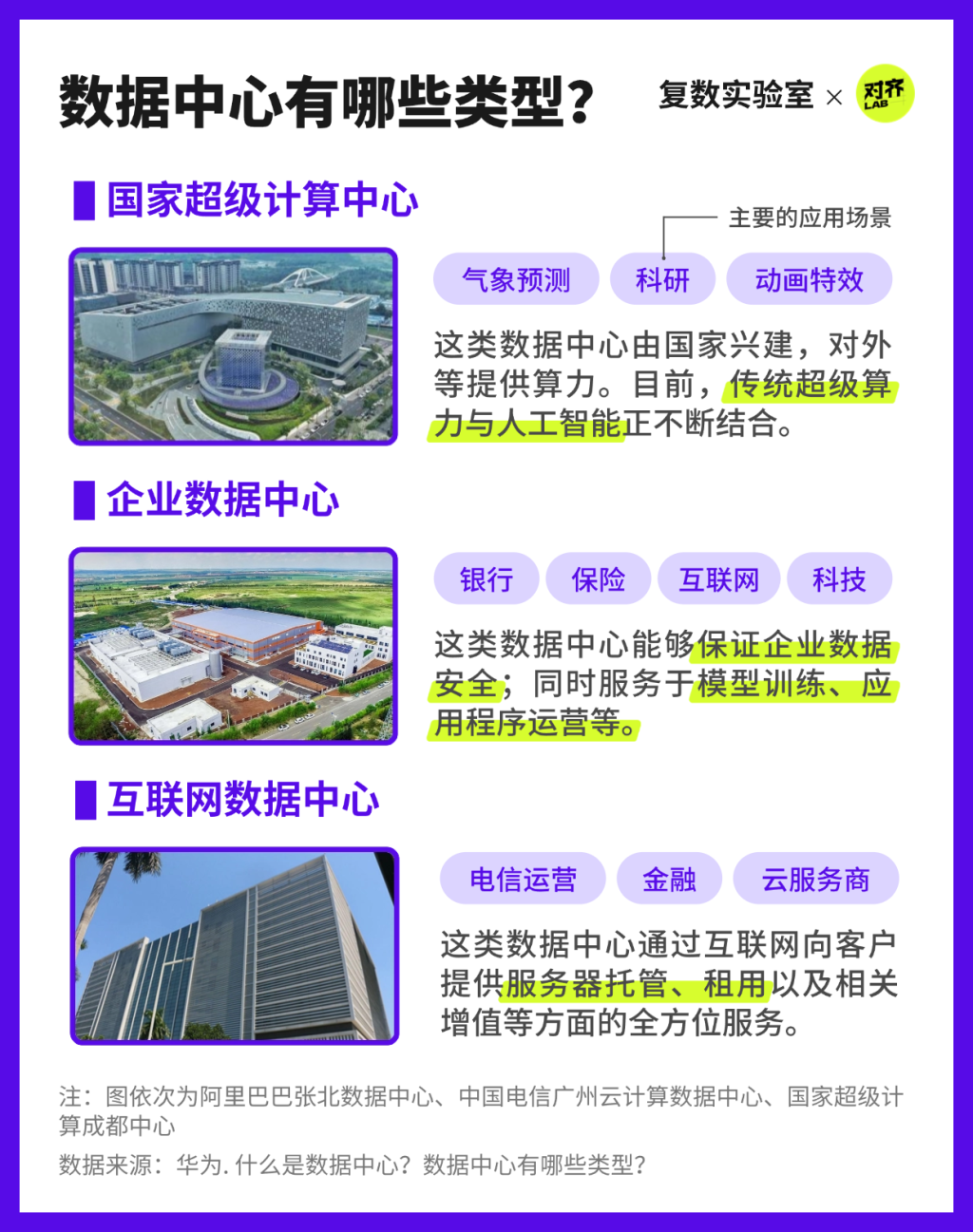
隨著技術的迭代,AI對算力的需求水漲船高,直接推動了數據中心數量的增長。AI工具的快速進化,離不開高性能的計算基礎設施的支撐,推動著數據中心的全球擴張。

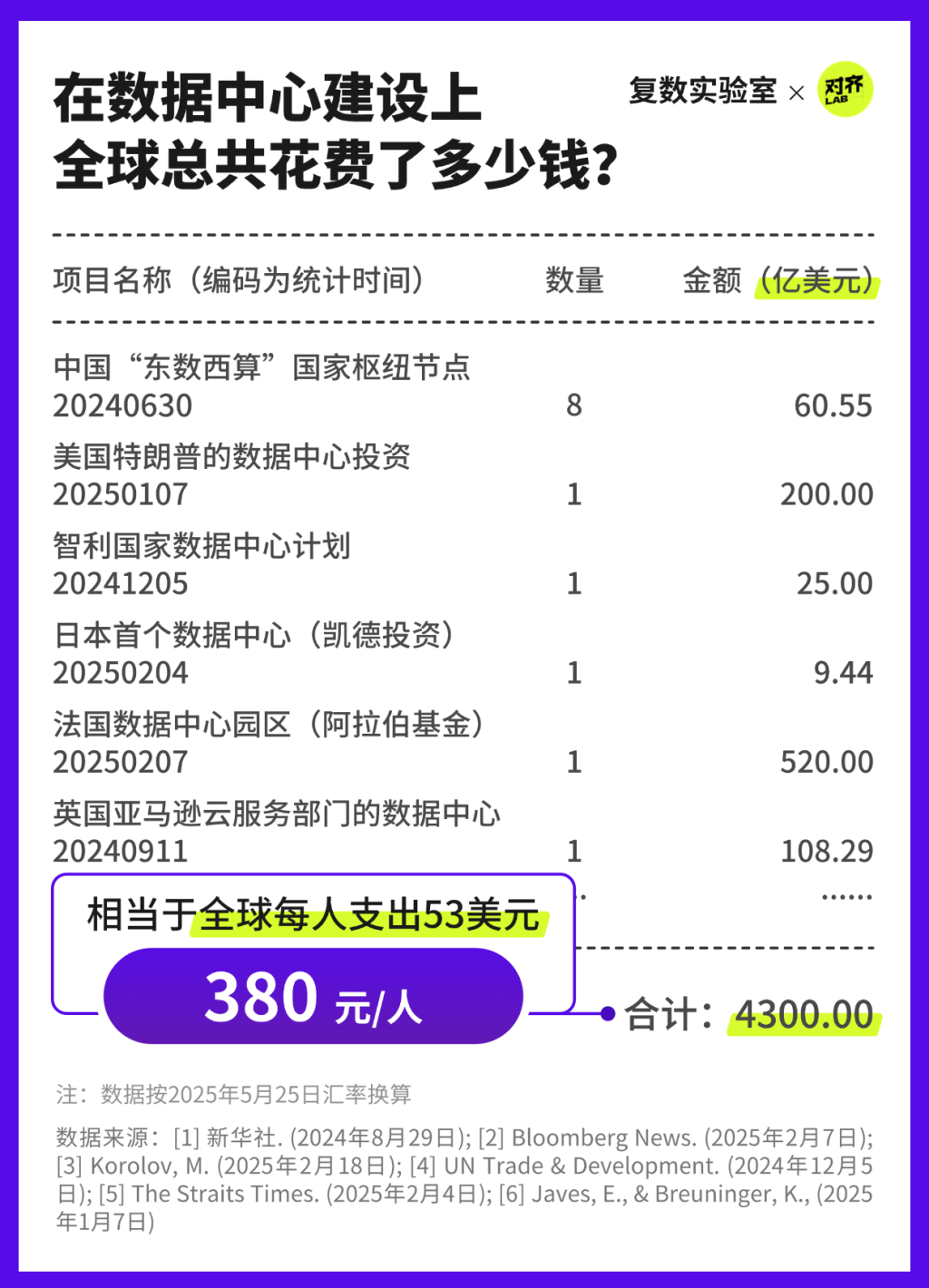
可以預見,數據中心將在未來數年內保持高速擴張的態勢。截至2024年,全球數據中心的資本支出據估計已高達4300億美元,而這場圍繞算力的投資熱潮仍在升溫。未來,數據中心發展的經濟賬單將繼續攀升。
悄然積累的生態賬單
這筆數據中心產業的投資大約相當于全球每人支出了人民幣380元。以這樣的價格來享受人工智能前沿技術,似乎也是一筆劃算的投入。
然而,這筆交易的附加項中打包了大量的環境代價——一份正在不斷積累、總量龐大的“生態賬單”,至今既沒有出現在產業成本的賬面上,并將隨著數據中心的持續擴張不斷增長。
根據國際能源署的最新預測,到2030年,全球數據中心的年耗電量預計將達到945太瓦時(TWh)左右——這個數字,已經略高于日本目前一整年的總用電量。
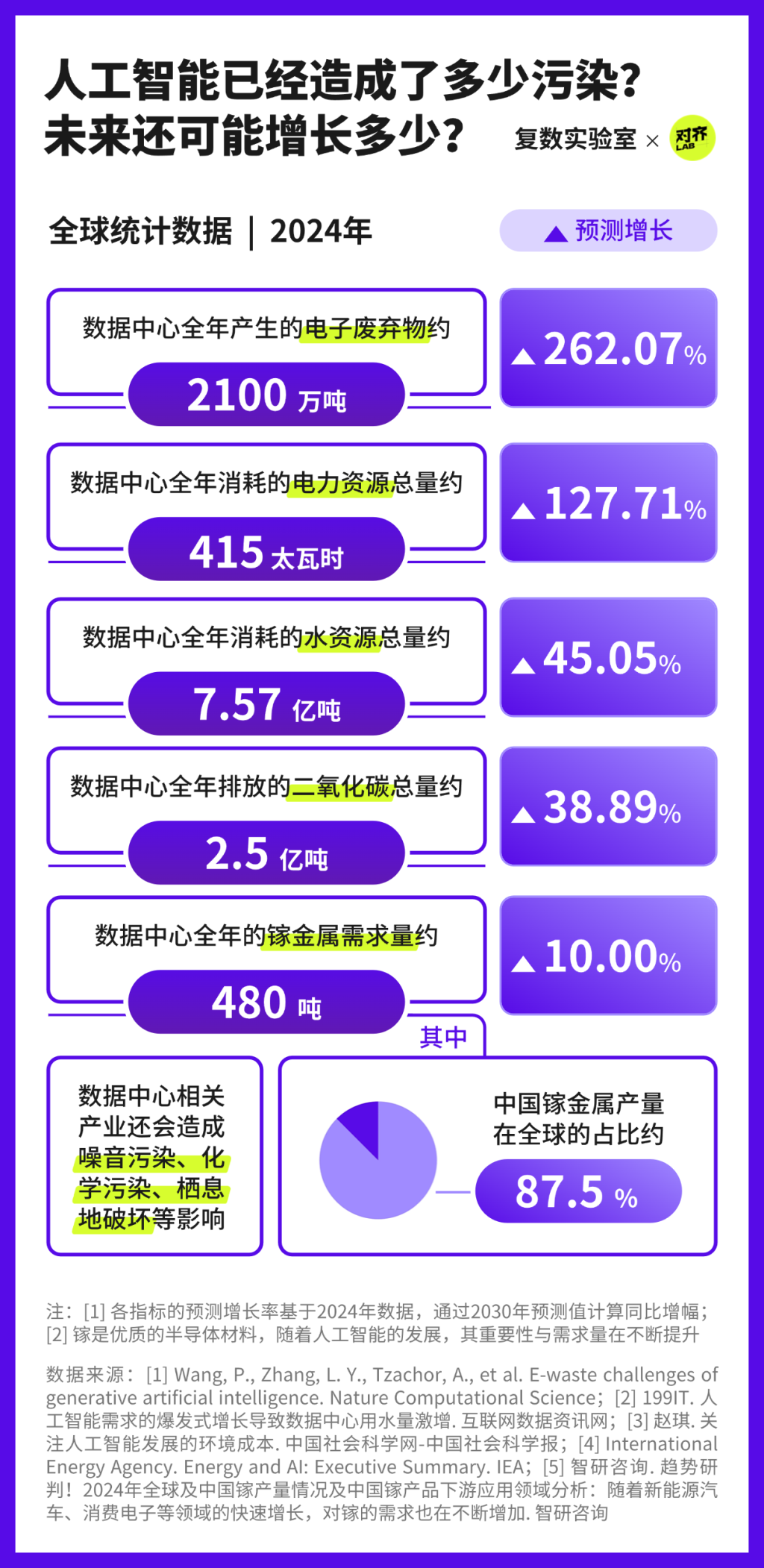
除可量化的資源消耗和污染排放外,更隱蔽的還有:開采稀有金屬帶來的化學污染、電子廢棄物中重金屬的泄漏、自然土地被數據中心侵占后動物失去棲息地……目前,這些影響尚未形成系統的監測數據。
誰來“還賬”?
這份被技術紅利掩蓋的“生態賬單”,誰來結算、如何治理?
在全球環境治理的復雜體系中,多個主體各自承擔著不同層級的責任。企業作為直接運營數據中心的主體,距離污染源最近,也最具實施變革的能力。國際組織可以制定標準,政府可以出臺政策,但能源結構的選擇與運行方式的調整,最終仍需由企業落地執行。
當前,碳排放控制成為多數企業環境治理策略的核心目標,其中在能源端的應對最為突出。大多數企業將可再生能源或清潔能源的使用作為主要減排措施。這類路徑在能源結構調整上相對可行,也易于量化評估。
整體來看,當前企業“還賬”的重點主要集中于減少碳排放,生態賬單上的其他欄目尚缺乏具體信息與解決方案。

不平等的治理地圖
即使是可持續實踐的領軍企業,也會存在這一治理重心的偏移。谷歌在其《2024環境報告》中重點對減碳路徑進行了最詳盡的披露。
其中,谷歌表示2023年其全球辦公及數據中心已實現每小時64%無碳能源使用率,44個電網區域中有10個達成90%以上清潔供電——這看似是一份不錯的成績單。
但從國家維度來看,這份優秀的成績單背后暗藏著明顯的斷層趨勢:加拿大魁北克的數據中心憑借豐富水電實現100%零碳運營,而沙特阿拉伯與卡塔爾的數據中心仍在完全依賴石油發電。在歐洲地區,波蘭以31%墊底;而在亞洲地區,表現最佳的韓國也僅達35%,遠低于全球平均水平。
隨著AI技術迭代加速,訓練新一代AI大模型的能耗量級持續增長。支撐AI發展的全球數據中心集群,或許正在重塑一張新的環境治理“不平等地圖”。
但谷歌并不是這張“不平等地圖”的唯一制作者。在全球前五大云服務企業中,除阿里巴巴外,其余四家在他國布局的數據中心數量普遍超過本土,呈現出明顯的跨國企業全球布局傾向。而在環保透明度上,谷歌是其中唯一按照數據中心集群所在地公布實時環境指標的廠商。
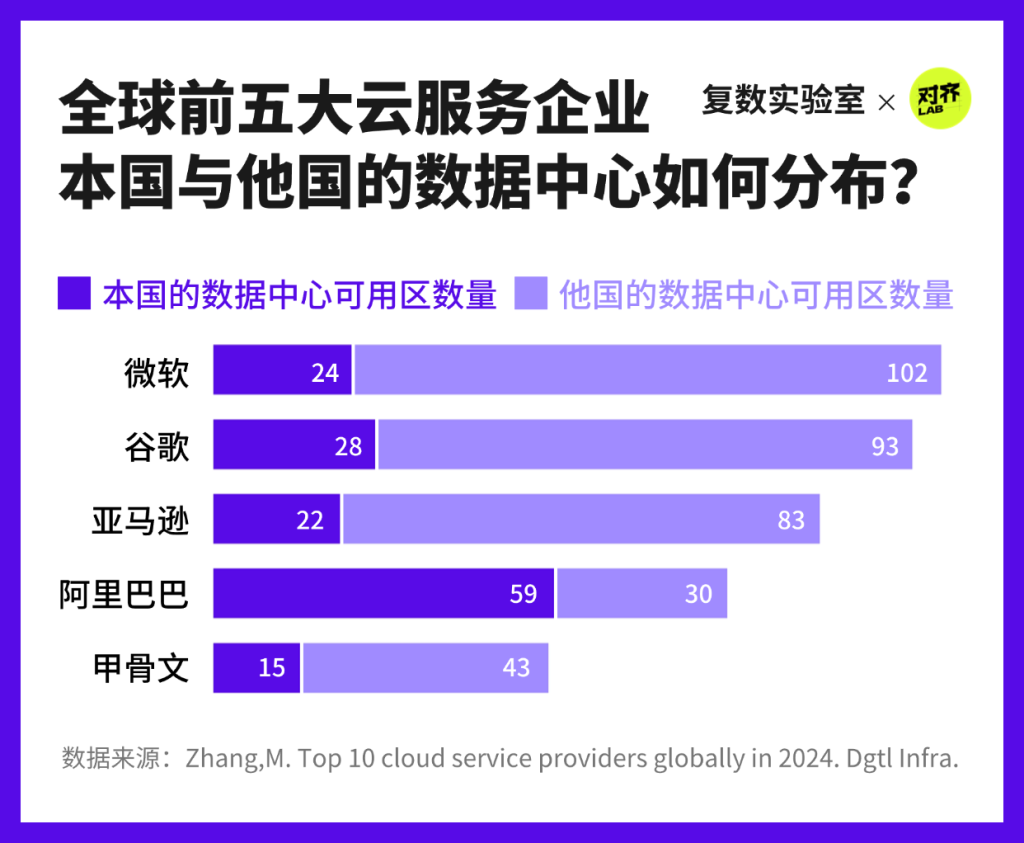
隨著AI的飛速發展,科技巨頭企業仍將持續擴建數據中心以應對日益增長的數據存儲和處理需求,在選址上集中于南美洲、歐洲、北美洲。然而,由于造成了環境問題,數據中心擴建計劃在這些地區卻引起了廣泛的反對聲潮。
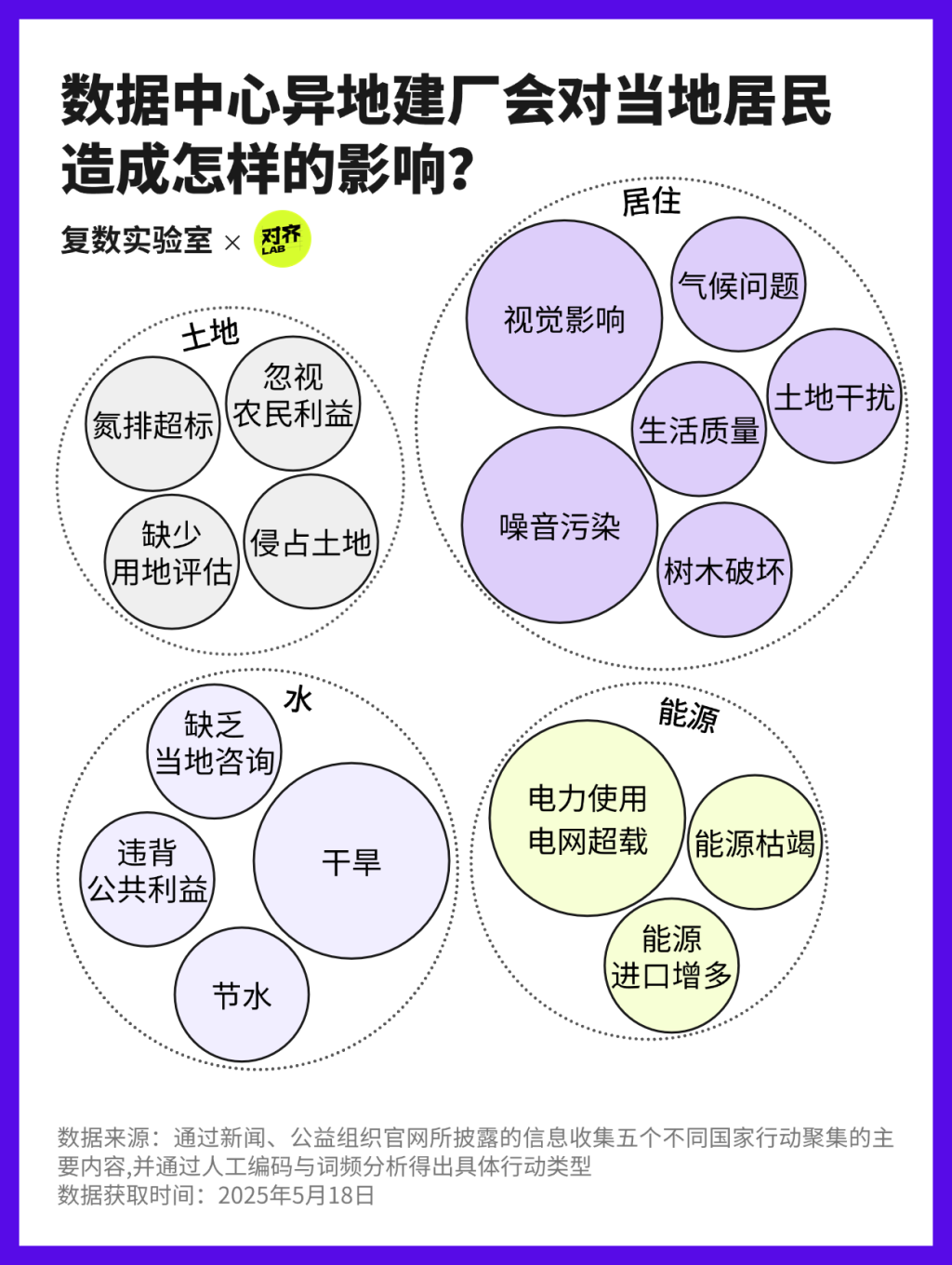
中國方案的新解法
數據中心的快速擴張實際上屬于“算力驅動型”的AI發展路徑。如今,一種新的技術趨勢正在浮現——AI正朝著高性能、低功耗方向演進。
中國團隊推出的開源大模型DeepSeek正展現著這種可能性。據DeepSeek披露,在不包含前期試錯成本的情況下,大模型DeepSeek-v3的訓練成本大約在558 萬美元。按照相似方法估算,GPT4的訓練成本約為4800萬美元。這不僅代表著經濟層面的高性價比,也意味著在同等的AI產出下,數據中心所承擔的計算壓力和能耗均有望減少。
此外,DeepSeek-v3采用了“MoE(Mixture of Experts)”模型。每次用戶提問,系統只激活一小部分參數進行處理,而不是全員上陣。這樣使得每次推理時實際被激活的參數只占總量的 5.5%,顯著減少了計算量,也降低了模型運行時對數據中心資源的消耗。
與此同時,中國也正從政策層面積極回應數據中心擴張所帶來的環境壓力,推動其綠色轉型,力圖在技術發展與環境可持續之間尋求平衡。
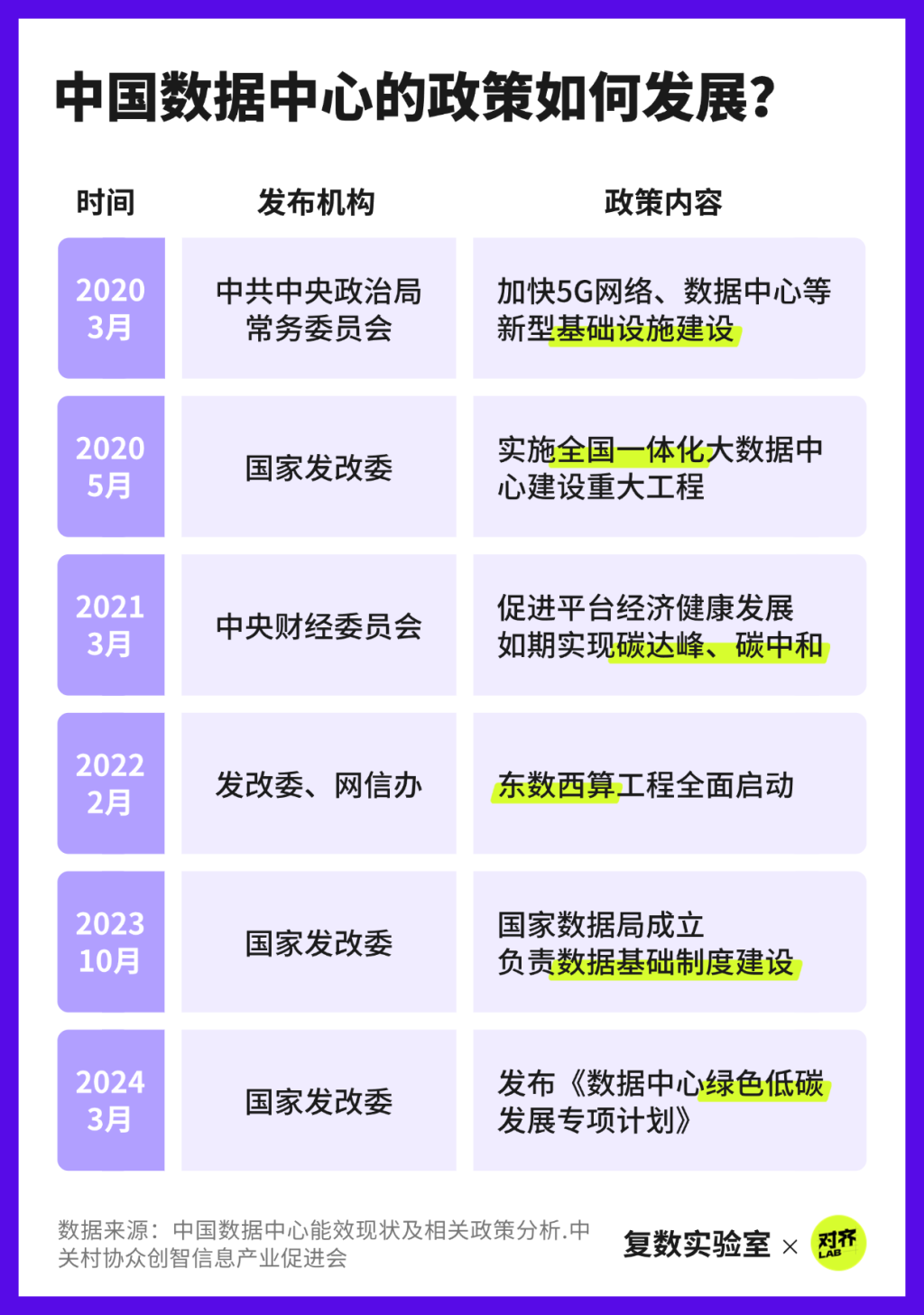
目前,電能利用效率(PUE)已經成為衡量綠色治理成效的重要風向標。以2030年為目標,我國各地數據中心的PUE水平將持續優化,向“1”穩步靠近。

在政策引導與技術進步的共同作用下,綠色轉型正在成為中國數據中心行業發展的主線。
可持續的未來?
OpenAI首席執行官Sam Altman曾表示,AI的成本正在以每年降低10倍的速度演進,這一現象被稱為“AI規模定律”(scaling law)。未來,AI的硬件更高效、算法更聰明,是否能夠真正實現低耗又智能的良性循環?
一些研究者對此持樂觀態度,加州大學伯克利分校名譽教授、谷歌研究員戴夫·帕特森(Dave Patterson)的分析預測,由于人工智能軟件和硬件能源使用效率的提高,人工智能的碳足跡將很快達到穩定水平,然后開始減少。
但樂觀之外,還有一盆冷水:“杰文斯悖論”認為效率提高會帶來使用激增,結果反而更耗能。華為創始人任正非曾這樣比喻這條悖論:“把高速公路拓寬,車流速度快了,油耗本應減少。但更多的車輛能上路,整體油耗反而增加了。”后續,當AI真正滲透進教育、辦公、娛樂等日常場景,其總體能耗可能在無形中不斷累積,超出原本“節能”的設想。
在這種不確定性下,個人用戶的選擇不應被忽視。雖然用戶無法直接決定一項AI技術的底層設計或訓練規模,但可以在使用中取舍——比如關注平臺的能源披露與可持續承諾,避免無意義的頻繁調用,理解每一次點擊背后都存在一次計算的事實。
所有改變的前提,是先看見問題本身。當更多人開始意識到這些“看不見”的能源消耗和環境代價,技術將向著更可持續的目標前進。更長遠來看,公眾的使用偏好和輿論導向,也將在某種程度上塑造AI生態的未來方向。
作者丨楊智博、沈馨、田益銘、韓旻格、傅冰清
指導老師|崔迪、徐笛、周葆華
封面圖|DeepSeek、豆包共同繪制
動圖內嵌視頻 | 即夢生成
本文為復旦大學新聞學院《數據分析與信息可視化》課程作品



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

