- +1
多模態搶占C位,成為AI企業的“應許之地”?
須知參差多態,乃是幸福本源。——羅素
人工智能占領世界,多模態統治人工智能。
從OpenAI發布GPT-4o、谷歌亮出Project Astra到馬斯克新一代大模型Gork-3,再到智譜AI自主智能體AutoGLM、DeepSeek開源模型Janus-Pro,以及智元機器人的啟元大模型GO-1,這些模型背后,無論科技巨頭還是科技新星,都瞄準了同一個方向:多模態AI。
谷歌研究報告顯示,預計至2025年,全球多模態AI市場規模將飆升至24億美元,而到2037年底,這一數字更是預計將達到驚人的989億美元。
資本也用真金白銀對多模態投下了“信任票”。根據全球金融追蹤機構PitchBook發布數據顯示,2024年,生成式AI領域的融資活動異常火爆,全年融資總額高達560億美元,同比增長192%。其中OpenAI融資總額81億美元,Anthropic完成75億美元融資,xAI共募集120億美元資金。這些投資主要聚焦于多模態生成技術突破、大語言模型優化、計算效率提升等方向。
為什么全球AI企業選擇集體押注多模態?多模態又將如何塑造未來十年的AI格局?

多模態重塑AI進行時
隨著AI越來越多地與現實世界發生交互,增強多模態能力、提升推理效率、降低訓練成本以及加強領域專業性,正成為大模型新一輪演化的重要方向。
如果把大語言模型(LLM)比作“關在籠子里的AI”,那么它和世界交互的方式就是通過“遞文字紙條”。
文字是人類對世界的表示,存在著信息提煉、損失、冗余、甚至錯誤。而多模態就像是讓AI繞開了人類的中間表示,直接接觸世界,從最原始的視覺、聲音、空間等開始理解世界、改變世界。
“模態”一詞最早是生物學概念,人類的“五感”——觸覺、聽覺、視覺、嗅覺、味覺,都是一種模態。從技術角度來說,模態就是感官數據,不僅包括最常見的圖像、文本、視頻、音頻數據,還包括傳感器等更為豐富的數據類型。
大模型經歷了從傳統單模態模型,到通用單模態,再到通用多模態的演進。
單模態AI的輝煌已經實現,如語言模型(如GPT)、視覺模型(如ResNet)以及語音模型(如Wav2Vec)雖取得了耀眼成就,但現實世界的復雜性無法僅靠單一模態理解。
這是由于單模態AI只能處理某一種類型的信息,通過讓AI學習互聯網上的海量文本、圖片等不同模態的數據,尋找其內在規律,但在算力、數據資源的限制下,僅依賴互聯網的數據學習會很快達到瓶頸,難以全面理解和應對現實世界中多樣化的信息輸入。只有像人類一樣多種感官信息相互補充,才能準確感知和理解世界。

為了讓AI更接近人類的認知和交互水平,多模態技術應運而生。1971年,美國心理學家艾伯特·梅拉賓(Albert Mehrabian)在著作《無聲的信息》一書中提出,人類交流中僅有7%的信息通過語言傳遞,其余93%通過語調(38%)和面部表情、肢體動作(55%)完成。這一發現被稱為“梅拉賓法則”,又稱7-38-55規則,成為多模態理論早期的重要基礎。
隨著OpenAI的DALL-E/GPT-4o/o1/o3、DeepMind的Flamingo等多模態系統的問世,讓AI打破模態邊界,不僅開始理解世界,還能生成跨模態的內容,這些進步標志著智能系統進入了一個全新維度。

簡單理解,多模態AI=多種數據類型+多種智能處理算法。
這一系統整合了多種不同模態的數據,通過復雜的算法模型進行融合處理,從而使AI系統能夠像人類一樣,綜合運用多種信息進行決策和交互。正是這種跨越不同模態理解和創建信息的能力,超越此前側重于集成和處理特定數據源的單模態AI,贏得了各大科技巨頭的青睞。
多模態AI的核心在于多源數據的整合與對齊。通過將視覺、語言和聲音轉化為統一的潛在表示,讓模型可以實現跨模態學習。例如,OpenAI的CLIP模型通過大規模圖文對比學習,掌握了語言描述與視覺特征之間的映射關系。
在更復雜的場景中,數據融合不只是簡單疊加,還需解決模態對齊的難題。比如,語言中的抽象概念如何匹配圖像中的具象特征?Transformer架構的引入為這一挑戰提供了技術支撐,其自注意力機制能夠在多模態間捕捉深層關聯,使模型具有更強的泛化能力。
從BERT到Vision Transformer,再到多模態預訓練模型(如BEiT-3),Transformer重新定義了AI的應用范圍。以DeepMind的Perceiver為例,其通用架構適配了語言、視覺和聲音數據,展示了強大的模態遷移能力。
對比學習和遷移學習技術同樣推動了多模態AI的快速發展。例如,通過對比學習,模型可以更高效地在模態間捕捉相關性,即使在小樣本數據下依然保持卓越性能。
而多模態AI的想象力,遠不止于此。
激發真實世界理解力
從生成式AI、自動駕駛、具身智能到智能體,多模態已經成為推動AI從“單一感知”邁向“全局理解”的核心。行業分析指出,多模態技術的突破正推動AI從工具向生產力轉化,并進一步拓展商業邊界。
2022年及之前,大模型處于單模態預訓練大模型階段,主要探索文本模式的輸入輸出。
2017年,谷歌提出Transformer架構,奠定了當前大模型的主流算法結構。2018年,基于Transformer架構訓練的BERT模型問世,參數規模首次突破3億。2020年6月GPT3.0的發布,標志著AI已經能夠高水平地生成文字和代碼。隨后,2022年7月,文生圖領域的標志性產品Stable Fusion問世。
2023年,是大模型發展進程中一道重要的“分水嶺”,其從文本、圖像等單模態任務逐漸發展為支持多模態的多任務,更為符合人類感知世界的方式。大模型公司的比拼重點轉移為多模態信息整合和數據挖掘,精細化捕捉不同模態信息的關聯。
例如,2023年9月,OpenAI推出最新多模態大模型GPT-4V,增強了視覺提示功能,在處理任意交錯的多模態方面表現突出。
2024年,OpenAI推出了首個文本生成視頻模型——Sora。相比Runway、Pika等主流視頻生成工具,Sora不僅能準確呈現細節,還能理解物體在物理世界中的存在,并生成具有豐富情感的角色,同時根據提示、靜止圖像甚至填補現有視頻中的缺失幀來生成視頻,堪稱多模態AI領域的一大里程碑。它展現了一個“會預測未來”的AI系統的雛形,讓人們對通用人工智能的到來充滿期待。
在提升對現實世界的理解方面,深度學習為多模態技術提供了強大支持。神經網絡架構的不斷創新,如卷積神經網絡(CNN)在圖像識別中的成功應用、循環神經網絡(RNN)在自然語言處理中的出色表現,為多模態數據的特征提取和處理奠定了基礎。在此基礎上,研究人員進一步探索如何將不同模態的數據進行融合,開發出了一系列多模態融合算法。
例如,早期的多模態融合方法主要是簡單的特征拼接,即將不同模態提取的特征向量直接連接在一起,然后輸入到后續的分類或回歸模型中。這種方法雖然簡單直觀,但未能充分挖掘不同模態之間的內在關聯。
隨著技術發展,出現了更復雜的融合策略,如跨模態注意力機制、模態間交互等。基于注意力機制的融合,能夠讓模型自動關注不同模態數據中重要的部分,并根據任務需求進行動態融合,充分提高了多模態融合的效果。這些方法使得模型能夠更好地利用不同模態之間的互補信息,從而提高任務的性能。
隨著深度學習的不斷發展,尤其是預訓練模型的興起,也為多模態技術帶來了新的突破。預訓練模型通過在大量無標簽數據上進行預訓練,學習到了豐富的知識表示,使得模型在下游任務上具備更強的泛化能力。
在這一階段,研究者們提出了多種多模態預訓練模型,如BERT-Vision、ViLBERT、LXMERT等,這些模型在圖像標注、視覺問答等任務上取得了顯著的性能提升。之后,研究人員開始嘗試將預訓練思想應用于多模態領域。
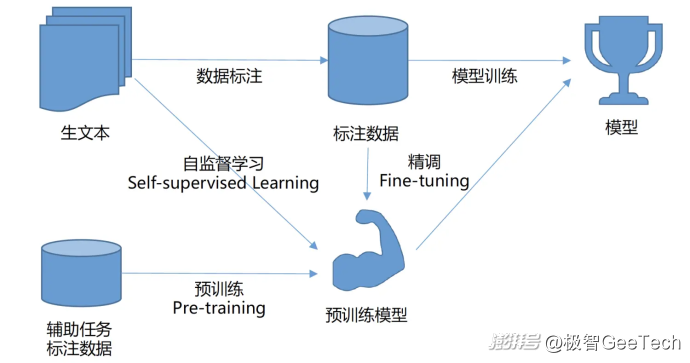
通過在大規模多模態數據上進行無監督預訓練,模型可以學習到不同模態之間的通用特征表示,然后在具體的下游任務中進行微調,這種方式顯著提升了多模態模型的性能和泛化能力。
可以看到,多模態技術的發展是AI技術不斷演進的必然結果,它在融合多種模態數據方面取得的重要進展,為解決復雜現實問題提供了更有效的途徑,這也是AI企業紛紛押注多模態技術的關鍵原因。
多模態到底解鎖了什么?
“跨模態任務需求+跨模態數據融合+對人類認知能力的模擬”是AI必然走向多模態的三大因素,我們正見證著AI從“工具理性”向“認知主體”跨越的拐點。
關于多模態模型的意義和價值,一個言論在業界廣為流傳:每多一種模態的解鎖,意味著用戶滲透率的進一步提升。
這句話背后的意義是:只有文字的人機交互是單一的,是被限制的。人機交互的未來必然是多模態的,AI需要多模態理解真實世界和真實的人,人也需要AI提供文字以外的輸出。
最典型的就是語音交互之于ChatBot這個今天使用最廣泛的AI場景。今天越來越多ChatBot類的產品都已經加入語音交互功能,而在一些特定的使用場景下(比如用豆包等AI應用練習英語),語音交互就能極大地提升用戶的使用體驗。
從商業模式來看,多模態AI主要分為兩種方式。
一種是向企業用戶提供API接口,以模型即服務(Model-as-a-Service)的形式,企業可以根據自身需求調用相應的多模態AI模型進行處理。
另一種是將多模態AI模型嵌入到自身的產品和服務中,提供具體的解決方案。這兩種方式都有著巨大的市場潛力,可以應用于各個領域,如機器人、智能交通、智能制造、智能家居等。
當前,人形機器人作為 AI 技術與高端制造業的結合體,不僅具有高通用性,能適應人類社會基礎設施,還因其性價比和廣泛應用前景而備受矚目。大模型等技術進步正推動人形機器人的泛化能力和自然語言交互能力快速發展。
據高工產業研究院(GGII)預測,2026 年全球人形機器人在服務機器人中的滲透率有望達到 3.5%,市場規模超 20 億美元,到 2030 年,全球市場規模有望突破 200 億美元。
在交通領域,隨著多模態大模型在多種場景中的適用性日益增強,市場對統一管理座艙功能的智能體需求日益增長。2024 年,“蔚小理”、吉利等主機廠相繼推出了Agent框架,以語音助手為切入點,實現座艙內功能應用的統一管理。Agent 服務框架的推出,不僅統一了座艙功能,還根據客戶需求和喜好提供了豐富的場景模式,尤其是支持用戶定制化場景,加速了座艙個性化時代的到來。
雖然現階段已上車的Agent大部分還停留在助手、陪伴以及具體場景功能列舉層面,但相比于大模型,Agent擁有更大潛力,具備可激發的自主性和突出的工具使用能力,更加貼合“主動智能”標簽,甚至能夠彌補大模型在實際應用中的限制。
智能家居是目前少數保持高速增長的產業之一。根據 Statista 數據預測,到2028年,全球智能家居市場規模將有望達到1544億美元,并且在2024年至2028年期間,該市場還將維持67%的高復合年增長率,這一增長趨勢得益于多模態大模型與家居產品的逐步融合和應用。
交互型多模態大模型的嵌入使智能家電具備更高級的語音交互能力,這能夠更準確地識別消費者需求,通過語音、手勢和面部表情的自然交互,控制智能家居設備,甚至提供情感陪護和輔導孩子作業的功能,使家庭生活更便捷、更富有互動性。
未來,多模態大模型有望集成于端側設備,在手機端與操作系統和各類App深度融合,可以接收用戶的自然語言指令或根據用戶所處環境即時調取合適的服務。例如,駕車時主動開啟免提通話并打開導航。多模態大模型甚至可以作為中心樞紐,連接各種生態服務,如支付、健康監測、交通導航和在線購物,形成一個完整的智能消費生活圈。
當與 PC 端結合后,多模態大模型有望大幅提升企業的生產力和創造力,甚至可能創造全新的工作和創作方式。多模態大模型綜合處理視覺、聽覺以及文本信息,形成了全方位的認知系統,它作為 AI 助手,能夠實時觀察屏幕上顯示的內容,無論是文檔、圖像還是視頻,并且可以迅速捕捉并解析其中的信息。
這種能力使得它能夠和用戶進行更為自然和流暢的溝通,不再局限于簡單的問答形式,而是能夠參與到更復雜的對話中,理解用戶的意圖,提供更具針對性的建議,甚至還可以預測下一步的需求。
這場技術進化正以不可逆轉的趨勢,將AI推向智能涌現的臨界點。未來5~10年,結合復雜多模態方案的大模型有望具備更加完備的與世界交互的能力,到那時,一切都將無比新鮮和令人驚嘆。這不僅讓未來的圖景更加清晰且真實,也預示著人機共生時代正全面到來。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

