- +1
百度文心4.5將至,大模型應用賽按下提速鍵

2月28日百度官方宣布將在3月16日發(fā)布文心大模型4.5。
在百度官宣前一天,媒體爆料了百度文心4.5將在3月中旬發(fā)布的消息,28日凌晨,OpenAI發(fā)布了GPT-4.5模型,OpenAI發(fā)布GPT-4.5的時間節(jié)點恰巧是媒體的爆料第二天。于是業(yè)內(nèi)人士分析OpenAI倉促發(fā)布GPT-4.5重要原因可能是來自中國的競爭加劇。

但略顯倉促發(fā)布的GPT-4.5性能被業(yè)內(nèi)評價差強人意。而據(jù)百度方面介紹,文心大模型4.5不僅在基礎模型能力上有大幅提升,且具備原生多模態(tài)、深度思考等能力。此前在DeepSeek大火時,百度也在2月中旬宣布,文心一言將于4月1日0時起,全面免費,所有PC端和APP端用戶均可體驗文心系列最新模型,并在6月30日起開源文心大模型4.5系列。
百度即將在4月和6月對文心一言“免費”和“開源”等一系列大動作,體現(xiàn)了百度的自信,也引發(fā)市場對文心大模型4.5的關注和期待。
文心大模型4.5定檔,百度史上最強模型將至
從2019年3月百度率先開始訓練大模型,并在2023年3月16日正式推出文心一言大模型,目前百度擁有超過5500億條知識的自研知識圖譜融入到文心大模型的預訓練中,結(jié)合深度學習和海量的行業(yè)數(shù)據(jù),如今已應用于百度搜索、信息流、智能駕駛、百度地圖等多款產(chǎn)品。
百度此后每年都會進行模型迭代。百度文心大模型矩陣再添“力作”,全家桶更加豐富。在時隔兩年后,百度再度發(fā)布新款大模型。據(jù)了解,3月16日發(fā)布的文心大模型4.5將具備多模態(tài)和深度思考能力,尤其是深度思考能力成為市場期待的焦點。
文心大模型4.5到底有哪些能力值得期待?
百度創(chuàng)始人、董事長兼首席執(zhí)行官李彥宏在2月18日的財報電話會上透露,文心大模型4.5將是百度有史以來最強大的大模型,“希望客戶和用戶能比之前更方便地體驗這款模型”。

近期文心一言上線了“深度搜索”功能,具備專家級問答能力,RAG能力突出,尤其是專業(yè)領域問答幻覺率低已經(jīng)降至最新水平,以及去年百度發(fā)布自研iRAG技術,這或是李彥宏對“史上最強大模型”的信心源泉。
而OpenAI最新推出的GPT-4.5不具備多模態(tài)推理能力,還是主打?qū)懽鞯任谋旧伞O噍^于OpenAI 的 ChatGPT、谷歌的 Bard ,作為扎根在中國市場下的本土大語言模型是目前市面上最適合中國人使用的語言模型。
研發(fā)投入1700億
大模型火爆至今已有三年,為什么頭部玩家依然只有那些實力雄厚的大公司?根本原因在于大模型非常燒錢,不是一般企業(yè)能夠玩得轉(zhuǎn)。其主要成本包括硬件、電力、數(shù)據(jù)、研發(fā)團隊等多個方面。
大模型的算力需求巨大,訓練大模型需要高性能計算集群,單卡成本可達數(shù)萬美元。以GPT-3為例,訓練需約1萬塊GPU,訓練耗時數(shù)周,僅訓練成本就高達數(shù)千萬美元甚至上億美元。這還不包括高負載運行導致硬件壽命縮短,維護和更新成本。
公開數(shù)據(jù)顯示,GPT-4單次訓練成本約6300萬美元,年運營成本超10億美元。Google PaLM(5400億參數(shù)):訓練成本約2000萬-3000萬美元。即便百億參數(shù)級模型訓練成本通常在數(shù)百萬美元級別。
百度能在大模型上取得讓OpenAI不得不倉促發(fā)布新品的成績根源在于舍得“砸錢”搞研發(fā)。財報顯示,2019年至2024年,百度的研發(fā)費用分別為183.5億元、195.1億元、249.4億元、233.2億元、241.9億元和221.3億元,近4年的研發(fā)費用均超過220億元,研發(fā)費用占總營收的比例一度在全球互聯(lián)網(wǎng)巨頭中坐二望一。2021年,在全球互聯(lián)網(wǎng)巨頭中,百度的研發(fā)占比高于谷歌和亞馬遜,位居全球第二位。
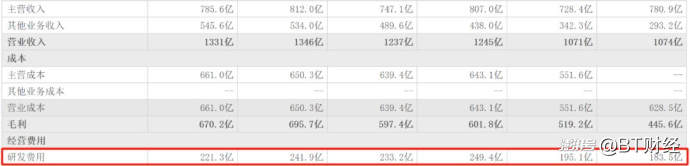
目前百度的研發(fā)占比始終保持在20%左右,而全球互聯(lián)網(wǎng)行業(yè)研發(fā)占比的平均值為3%-6%之間,比如小米研發(fā)占比4%左右,聯(lián)想研發(fā)占比2.5%左右,京東研發(fā)占比1.6%左右,百度和華為成為目前國內(nèi)互聯(lián)網(wǎng)企業(yè)中研發(fā)占比超過10%的唯二兩家。
財報數(shù)據(jù)顯示,百度投入AI十年來累計研發(fā)投入1700億元。在大模型領域的巨大投入,才讓百度成為全球大模型的領跑者。
AI行業(yè)大震動——接連開源、免費,百度更加開放
大模型現(xiàn)在進入到了一個新的階段。通過開源路線普及模型的基礎,進而帶動模型應用的爆發(fā)。
李彥宏在財報電話會上專門對百度即將開源進行了解讀,李彥宏表示,開源4.5系列的決策源自于對技術領先地位的堅定信心,開源將進一步促進文心大模型的廣泛應用,并在更多場景中擴大其影響力,“但我想強調(diào)的是,無論開源閉源,基礎模型只有在大規(guī)模解決現(xiàn)實問題時,才具備真實價值”。未來,百度將加速推動文心大模型的性能升級與成本降低。
開源作為技術領域的核心協(xié)作模式,其價值體現(xiàn)在技術、經(jīng)濟、社會等多個維度,技術驅(qū)動層面,?提升軟件質(zhì)量與安全性,?開源代碼的透明性允許全球開發(fā)者共同審查和修復漏洞,形成持續(xù)優(yōu)化的技術迭代機制。開源打破了技術壟斷,開發(fā)者可基于現(xiàn)有成果快速迭代,?加速了技術創(chuàng)新。最為重要的一點是開源可以降低行業(yè)整體成本,李彥宏在談DeepSeek時表示“歷史上的創(chuàng)新都來自于成本降低,大模型成本每年降低90%以上”,這其中開源占據(jù)絕大部分作用。

互聯(lián)網(wǎng)投資人史保剛對百度開源表示了贊賞,“百度在技術提速的情況下,為推動行業(yè)整體的發(fā)展,推出了免費和開源,從接入DeepSeek也體現(xiàn)了百度兼容和開放,這樣能讓百度占據(jù)大模型競爭的主動權(quán),根源還是源于百度對自身技術的自信。”
史保剛認為百度直接將行業(yè)拉入“免費+開源”的新階段,將大模型的使用門檻拉到極致,無疑將助推大模型應用爆發(fā)。在推動行業(yè)發(fā)展的同時也帶動百度自身大模型的發(fā)展,對百度和對行業(yè)都有極大的推動作用。
使用場景和產(chǎn)品體驗為王的時代
無論是百度文心一言還是ChatGPT-4,大模型的使用場景和產(chǎn)品體驗設計都是決定其技術價值能否轉(zhuǎn)化為實際商業(yè)或社會價值的關鍵。大模型的技術能力是基礎,但產(chǎn)品體驗決定了用戶是否愿意持續(xù)使用,也是決定該大模型能否通過市場檢驗的基礎。現(xiàn)在第一輪百模大戰(zhàn)接近尾聲,接下來是應用大戰(zhàn),如何讓大家都有機會接入最先進的技術,落地使用場景是各大頭部玩家的追求目標。
目前,百度文心大模型技術正經(jīng)歷從?“能力展示”到“價值交付”?的關鍵躍遷。未來三年,具備?場景理解深度?、?交互友好度?、?價值可量化?特征的產(chǎn)品,將在醫(yī)療、金融、制造等領域持續(xù)釋放變革能量?。這一進程中,技術普惠與倫理規(guī)范的雙軌并行,將定義智能時代的新型生產(chǎn)關系。
在使用場景和產(chǎn)品體驗為王的時代,百度文心大模型的眾多場景體驗已經(jīng)通過市場檢驗,實現(xiàn)了“應用落地”,代表著中國大模型領域的最新技術和發(fā)展路線。這次李彥宏攜“百度史上最強大模型”自信而來,在使用場景不斷豐滿以及應用場景真正做到落地的情況下,也讓市場對百度最新力作擁有更多期待。
前有DeepSeek春節(jié)出圈,后有百度接連開源、免費,中國大模型趕超美國提速。中國在以百度為代表的企業(yè)在算法方面的巨大投入產(chǎn)生的強大的基礎大模型是護城河,目前來看,OpenAI被“逼出”GPT-4.5的背后,是中國大模型在不斷提升能力趕超美國的印證。
該文為BT財經(jīng)原創(chuàng)文章,未經(jīng)許可不得擅自使用、復制、傳播或改編該文章,如構(gòu)成侵權(quán)行為將追究法律責任。
作 者 | 夢蕭
本文為澎湃號作者或機構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機構(gòu)觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發(fā)布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務許可證:31120170006
增值電信業(yè)務經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

