- +1
DeepSeek爆發致“AI六小強”邊緣化?活下去才是硬道理

誰也沒有想到,DeepSeek-R1的影響居然這么大。
騰訊、百度、360、華為、OPPO等科技巨頭紛紛點贊DeepSeek,并為旗下的部分AI工具接入了R1模型。曾公開反對開源模型且一直收費的百度,則宣布文心大模型將于4月1日起免費服務,6月30日起開源模型。
就連全球AI大模型領導者OpenAI也在反思一直踐行的閉源策略,走向開源,其CEO山姆·奧特曼宣布,將開發一款非常小,但仍需在GPU上運行的開源小模型。
然而一家歡喜幾家愁。在我們熱議DeepSeek時,曾經紅極一時的AI大模型六小強(亦稱“AI六小龍”或“AI六小虎”)零一萬物、百川智能、階躍星辰、智譜華章、月之暗面、MiniMax卻似乎漸漸被大眾遺忘。
AI六小強的進步,沒人在意了?
在DeepSeek憑借R1模型攪動AI行業風云的同時,六小強也動作頻頻,如零一萬物與阿里云聯合成立“產業大模型聯合實驗室”,基地落戶蘇州高新區;百川智能于1月25日發布同時具備語言、視覺、搜索三種推理能力的全場景模型Baichuan-M1-preview,并在2月13日正式上線了基于Baichuan-M1底座打造的AI兒科醫生。
1月20日DeepSeek-R1模型發布當天,六小強中有三家也發布了新品,其中MiniMax推出了T2A-01系列語音模型和海螺語音產品,支持17種語言和上百種預設音色,可以提供更自然的AI配音。
階躍星辰則于當天發布了輕量級、高性價比的Step-2-mini和主打文字創作的Step-2模型,后續兩天又接連發布了Step-1o Audio升級版、多模態理解大模型 Step-1o Vision、視頻生成模型Step-Video V2。
在AI大模型六小強中,月之暗面未必實力最強,但熱度一定最高。月之暗面開發的Kimi一度登上素材買量榜第一,曾是小雷使用頻率最高的AI大模型。1月20日,月之暗面發布了Kimi k1.5多模態思考模型,上下文窗口擴展至128k,加入了視覺模態識別能力。


(圖源:Kimi截圖)
擁有清華大學背景的智譜華章,前段時間與三星合作,攜手三星為國內用戶提供AI服務,也小小地火了一把。只可惜,三星手機國內銷量已淪為others,未能帶給智譜華章更多流量。前段時間,智譜華章也推出了清影2.0大模型,視頻生成速度和效果均顯著提升。
六小強努力嗎?很努力,各類型AI大模型一個接著一個發布。六小強有實力嗎?有,階躍星辰去年發布了8款多模態相關大模型,并斬獲多個權威榜單第一,剛發布不久的Step-1o模型,又在大模型測試平臺OpenCompass的測試中再次拿下多模態模型評測實時榜第一。
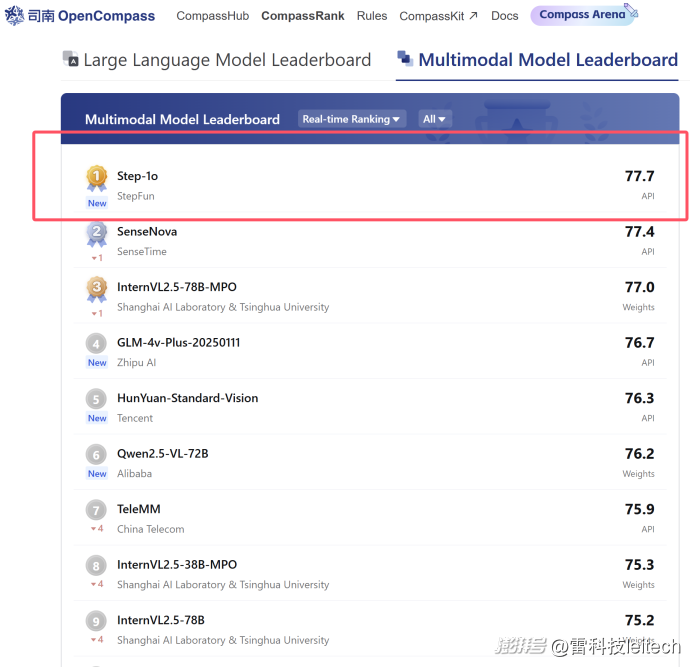
(圖源:OpenCompass截圖)
OpenAI在取得國際信息學奧林匹克競賽(IOI 2024)金牌的報告中,還特地指出的DeepSeek-R1和Kimi k1.5分別通過CoT(思維鏈)提升了模型的數學推理和編程能力。
問題是,這一切都不重要,互聯網時代酒香也怕巷子深,他們的人氣太低了。百度指數顯示(注明:百度指數未收錄“零一萬物”詞條),最近30天,AI大模型六小強中,只有月之暗面的人氣較高,其他幾家人氣均較為一般,百川智能和階躍星辰的日均搜索指數更是只有三位數。
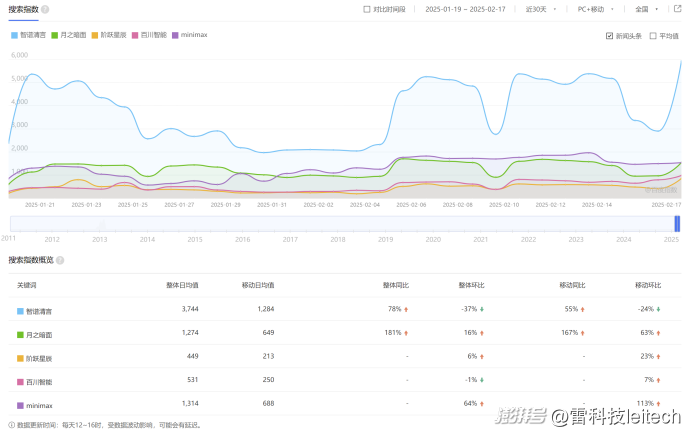
(圖源:百度指數截圖)
若是輸給百度、阿里巴巴、騰訊等互聯網巨頭,AI大模型六小強還能自我安慰,財力和資源落后那么多,輸了倒也正常。可偏偏讓AI六小強尷尬的是,DeepSeek訓練出V3模型只花費了557.6萬美元,又付出了幾十萬美元成本,將其調整至R1模型,花小錢辦成了大事。
C端失守、B端難攻,六小強何去何從?
DeepSeek攪動風波后,國內外各大互聯網巨頭迅速作出了回應。小米 CEO雷軍直言DeepSeek非常了不起,很欽佩他們。
阿里巴巴聯合創始人、董事局主席蔡崇信表示,DeepSeek證明了開源的價值,未來會將更多資源投入AI應用中。騰訊、百度、360將AI應用接入R1模型,更是用實際行動表達了對DeepSeek的認可。
再回過頭來看AI六小強,目前應該沒有任何一家公司站出來點評DeepSeek,只有階躍星辰默默為躍問接入了DeepSeek-R1。零一萬物和MiniMax雖然也接入了DeepSeek-R1,但只有海外版產品才能用,國內用戶無緣。
互聯網巨頭資源豐富,開發的頂級大模型與DeepSeek-R1處于同一梯隊,哪怕部分領域有所落后,大量資源砸下去,追上來也不是難事。正因如此,互聯網巨頭更加坦然,AI工具主動接入R1模型,為用戶提供更好的體驗。
(圖源:騰訊元寶截圖)
AI六小強拼資源比不過互聯網巨頭,又沒能像DeepSeek低成本打造出影響整個行業的R1模型,難免處境會有些尷尬。零一萬物和MiniMax為海外產品接入DeepSeek-R1,國內產品卻暫未接入,原因或許就在于擔心丟了面子。
對于AI六小強而言,唯一的好消息是AI大模型面向C端用戶基本免費提供服務,不會導致因市場丟失造成C端收入下滑,B端市場才是AI六小強的生命線。
但DeepSeek-R1的MIT開源協議允許用戶自由使用、復制、修改、分發,而且無需支付費用即可將其用于商用目的,任何企業都可以輕松部署R1模型,顯然影響到了AI六小強B端市場的根基。企業將DeepSeek-R1稍作修改,用于B端場景,成本可能比與AI公司合作更低。
DeepSeek-R1性能或許并非國內第一,但低成本和開源的特性改變了AI行業。據科技媒體T報道,蘋果都曾考慮過找DeepSeek合作,為中國用戶提供AI服務,最終因DeepSeek沒有為大型客戶服務的能力和經驗而放棄。
(如愿:DeepSeek截圖)
AI大模型商業模式差,企業的變現能力弱,如今AI六小強又遭遇DeepSeek的沖擊,調整方向并增強融資能力已成關鍵。
智譜華章和階躍星辰在2024年底分別收到了北京市國資和上海市國資的認可,完成了一輪融資,短期內沒有資金焦慮。月之暗面和百川智能2024年融資規模均超過50億元,暫時資金充裕。較為危險的是零一萬物和MiniMax,自身融資能力相對較弱,亟需投資者的支持。
不僅如此,AI行業的競爭導致人才戰愈演愈烈,字節跳動前CEO張一鳴被曝親自監督從競爭對手挖人工作。2024年下半年以來,AI六小強人才流失嚴重,零一萬物副總裁黃文灝、百川智能商業化負責人洪濤、MiniMax產品負責人張川等紛紛離職,月之暗面更是因多位負責人離職收縮海外布局。
強如OpenAI與百度也面臨DeepSeek的挑戰,AI六小強面臨的競爭形勢正愈發緊迫。
六小強放棄爭先,找到立足之地才是關鍵
英諾天使基金合伙人、北京市前沿國際人工智能研究院理事長王晟表示,AI的上升曲線已經放緩,預訓練數據幾乎被耗盡,DeepSeek-R1標志著整個行業正在從對標OpenAI的宏大敘事轉向場景優先的實用主義。
AI行業結束拼資源的時代,對于AI六小強這類底蘊不足的企業并非壞事。所有AI企業提升頂級大模型能力會越來越難,通過知識蒸餾、架構優化、改進訓練策略、分布式訓練等技術或方案,以低成本訓練更實用的AI大模型將成為主流。
事實上,零一萬物創始人李開復在DeepSeek-R1發布之前,就認識到了行業的變化,并表示零一萬物不再追求訓練超級大模型,參數適中同時性能優異、推理速度更快、推理成本更低的輕量化模型更適合商用場景。

(圖源:豆包AI生成)
2025年2月18日,月之暗面在推出終極模型Kimi Latest的同時,還被曝將削減廣告投放預算。的確,Kimi一年多時間的廣告投入,只帶來了不足千萬的日活用戶,而DeepSeek憑借R1模型,短短一個月左右時間,就獲得了3500萬日活用戶,導致官方頻頻崩潰,騰訊、360等互聯網巨頭提供的接口反而體驗更好。瘋狂打廣告吸引C端用戶卻難以增加營收,倒不如減少廣告投放,降低支出成本。
好在,AI行業尚未進入贏者通吃的局面,AI六小強仍有機會。承認自己的不足,效仿DeepSeek以低成本訓練大模型,甚至接入R1模型,主動為C端和B端用戶提供更完善的服務體驗,并同步提升自己,或許才是更適合AI六小強的生存之道。AI時代,國內最終能留下多少巨頭企業猶未可知,但一定會有小型企業的生存空間。
財力和資源有限的企業,放棄追求領導行業,如零一萬物一般著重開發低成本輕量化模型,主攻商用場景,或許是更好的選擇。
這一波開源浪潮來襲,也是小型互聯網公司的機會,無需付出大量成本開發AI大模型,僅需在開源模型上調整,也能為B端用戶提供AI服務。實力較弱的AI企業可以考慮轉型成以通義千問、DeepSeek等企業開發的免費可商用開源大模型為基礎,針對B端用戶的需求進行修改和定制AI大模型的模式,降低整體成本,快速實現盈利。

本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

