- +1
DeepSeek-R1下載量破千萬:這不是AI的斯普特尼克時刻,而是開源的勝利

發布僅僅一個月左右,DeepSeek-R1成為Hugging Face平臺上有史以來最受歡迎的模型,其衍生出的數千個變體模型下載量突破了1000萬次!2月14日,Hugging Face聯合創始人Clément Delangue在推特上激動宣布。

從Delangue分享的圖表中可以明顯看出,DeepSeek-R1(黃線)的下載量增長曲線幾乎呈現出“垂直起飛”的態勢,其他開源大模型,如Llama、Stable Diffusion、Mistral等增速相對緩慢。
這是繼DeepSeek AI智能助手登頂美區App Store免費下載榜之后另一個振奮人心的消息。
我們來看看DeepSeek AI智能助手上架一個月后表現如何?
2月14日,它在生產工具類別下依然高居第三,排行榜的榜首被ChatGPT奪回,Google Gemini排在第四位。
在DeepSeek的評論區里,不少用戶給出了高度評價:
“取消GPT訂閱。我喜歡能夠閱讀它的‘推理’過程......更不用說我在我的MacBook 上運行了14b和32b本地模型。比Apple Intelligence好多了......我認為如果DeepSeek能夠用更少的錢把事情做好,蘋果應該解雇負責蘋果智能研究的人。”
“五星好評!我最近有機會使用DeepSeek,我必須說,它徹底改變了我處理數據分析和決策的方式.....真正讓我印象深刻的是它提供的定制和靈活性......感謝DeepSeek創造了如此強大且用戶友好的解決方案!”
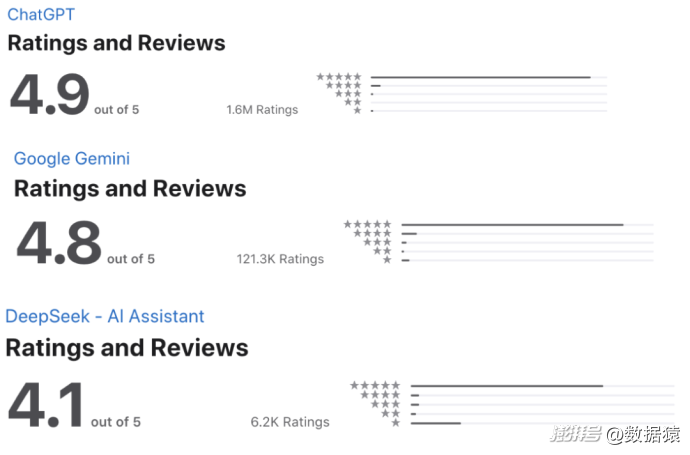
不過整體而言,DeepSeek的評分僅為4.1分,與兩大競爭對手ChatGPT(4.9 分)和Google Gemini(4.8 分)仍有差距。
考慮到ChatGPT和Gemini經過多輪優化,UI/UX設計更為成熟,用戶體驗也更流暢;而DeepSeek雖然在AI模型壓縮和輕量化方面表現出色,但用戶在實際使用中仍可能遇到響應延遲、服務器不穩定、訪問受限等問題。此外,作為一款來自中國的產品,其在美國市場的信任度相對較低。在這樣的背景下,DeepSeek依然能取得當前的口碑和下載量,已相當可觀。
回顧過去一個月,DeepSeek頻頻登上各大媒體的頭版頭條,成為科技公司和風投界熱議的焦點。
憑借推出“平價好用”的大語言模型,這家總部位于杭州的公司更是引發了市場對“燒錢”型AI模式的深刻反思,同時也在一定程度上攪動了美股市場。
1月27日,隨著其AI智能助手登頂美區App Store免費下載榜,納斯達克指數暴跌超3%,一度觸及19204.95點;標普500指數則下跌1.46%,最低降至5962.92點。
隨著FOMO(Fear of Missing Out)情緒的消退,目前兩大指數均已有所修復,在上周五,納指重新站上20000點,標普500指數則回升至6,114.63點。
DeepSeek 為什么“震撼”了美國?
先上結論,主要有四個點對美國產生了極大的“震撼”:
1.極低的訓練成本:DeepSeek團隊聲稱僅花費了600萬美元就訓練出了 R1,而GPT-4的訓練成本預計高達數億美元。
2.中國AI研究實力的證明:美國一直在限制對中國的AI芯片出口(如 Nvidia GPU),但DeepSeek仍能取得突破,說明芯片封鎖并未阻止中國AI的發展。
3.開源且提供極其寬松的許可:DeepSeek-R1采用MIT許可證,比Meta的 Llama 還要開放,任何人都可以免費使用、修改和二次開發,甚至商用化。
4.推理過程(reasoning traces)的公開:這點很重要。以往,OpenAI在發布A1時并沒有公開推理過程,而推理過程的公開可以幫助小模型快速進行知識蒸餾(distillation),讓小模型的訓練成本更低、速度更快。
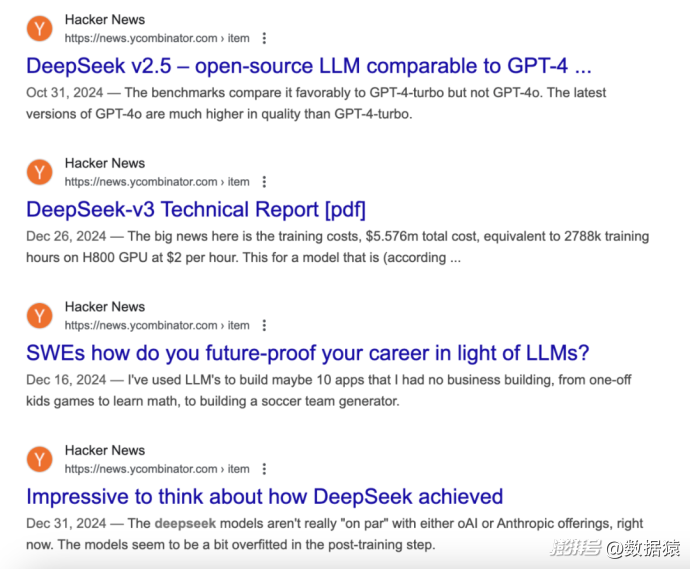
其實,DeepSeek在“爆火”之前,英文技術社區已經對它進行了一段時間的關注了。
在HackerNews上,最早的討論可追溯至 2024 年 9 月,當時一名用戶表示 DeepSeek的性能看起來不錯,但對用戶條款、隱私政策等存疑,而其他用戶則回復道:“這是個開源模型,便宜又好用,不用太擔心。”

2024年10月發布的一篇名為“DeepSeek v2.5 – 一個和GPT-4相當的開源大語言模型,但價格便宜95%” 的帖子也引發了熱烈討論,足見許多開發者都在尋找更經濟實用的大語言模型。但大部分評論者認為,DeepSeek v2.5在功能完整度和性能上并不能完全替代GPT-4,更多是以極具優勢的價格覆蓋了基本需求,幫助開發者大幅降低日常研發和調用成本。

10月到12月之間,我們可以看到依舊有不少討論DeepSeek的帖子。
接下來的劇情就是,1月20日,DeepSeek正式推出了R-1。這是一個在數學、代碼生成和自然語言推理等任務上,可與OpenAI的o1模型相媲美,但對計算資源消耗卻遠低于市面主流大模型的全新大語言模型。隨著DeepSeek的AI智能助手沖上美區蘋果免費應用排行榜第一,美國科技公司的股價受到重創。
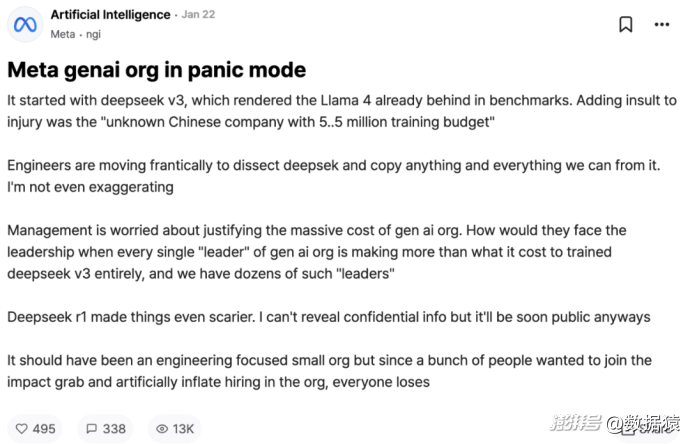
在匿名職場社交平臺Blind上,一位Meta員工爆料,DeepSeek對Meta GenAI業務部門造成了巨大沖擊:
“管理層擔心如何證明GenAI業務部門的巨額成本是合理的。當GenAI業務部門的每一位領導的收入都超過完全培訓DeepSeek v3的成本時,他們將如何面對更高的領導層?何況我們有幾十位這樣的領導。Deepseek-R1讓事情變得更加可怕。我不能透露機密信息,但它很快就會公開。GenAI本應是一個專注于工程的小型組織,但由于一群人想加入影響力爭奪戰并人為地增加組織的招聘人數,每個人都輸了。”
一名谷歌員工在回復中也給出了最受支持的觀點:
“DeepSeek的做法的確瘋狂。但這對整個行業是好事,我們正在實時見證公開競爭如何有效地推動創新。”

盡管不確定Meta GenAI部門是否真如帖子所言那樣焦灼,但可以肯定的是,OpenAI、谷歌、Anthropic等AI巨頭正在切實感受到來自DeepSeek的壓力,并紛紛加快更新產品以鞏固自身優勢。
1月31日,OpenAI宣布推出全新推理模型o3-mini,并首次向免費用戶開放。作為OpenAI推理系列中的最新產品,o3-mini相較o1價格便宜了93%,其中輸入價格為1.10美元/百萬Tokens,輸出價格為4.40美元/百萬Tokens。
2月5日,谷歌高調更新了Gemini 2.0全家桶,包括面向通用場景的Gemini 2.0 Flash、性能更強的Gemini 2.0 Pro,以及性價比最高的Gemini 2.0 Flash-Lite。官方信息顯示,Gemini 2.0 Flash-Lite與1.5 Flash在速度和成本上持平,最大的亮點是“高性價比”,其輸入價格為0.075美元/百萬Tokens,輸出價格為0.30美元/百萬Tokens。
與DeepSeek-R1的輸入/輸出價格(分別為0.14美元和2.19美元/百萬Tokens)相比,o3-mini依然偏貴;而Gemini 2.0 Flash-Lite雖然成本更低,但在需要更強算力或更復雜推理的場景中,表現相對遜色。
面對這樣“便宜大碗”的模型,開發者們怎么能不動心?
Perplexity率先接入了DeepSeek,微軟CEO薩提亞·納德拉也在1月29日的財報電話會議上宣布:DeepSeek-R1可通過Azure AI Foundry和GitHub獲取。隨后,AWS、英偉達、AMD、Intel等云服務及芯片巨頭紛紛快速跟進,爭相搭上DeepSeek的“快車”,希望借其更低成本、更高效的推理能力來增強各自的AI生態,以及更好地滿足開發者需求。
在錯綜復雜的地緣政治環境下,中美在AI領域常因政策與監管產生分歧。然而,DeepSeek采用開源和寬松許可模式發布其模型,讓更多研究者能夠跨越國別和制度鴻溝,進行深度探索與驗證。這種“社區共建”的機制,不僅推動了技術的快速迭代與傳播,也在很大程度上弱化了地緣競爭中的不信任感,為AI創新建立了一個相對開放的公共平臺,給業界帶來了強烈的“震撼”。
這是AI的斯普特尼克時刻?還是一份禮物?
1957 年,蘇聯成功發射人類歷史上的第一顆人造衛星——斯普特尼克(Sputnik),美國人頓覺領先地位被撼動,不得不全力投入到一場空前的太空競賽中。
今天,美國主流媒體也將中國團隊推出的DeepSeek-R1視作一種“AI的斯普特尼克時刻”,因為它同樣觸動了科技界的神經,引發了類似當年的危機感與緊迫感。甚至美國總統唐納德·特朗普也宣稱這是“對我們AI行業的警鐘,我們需要全神貫注于競爭”。
在美國風險投資機構Andreessen Horowitz(a16z)的合伙人Martin Casado看來,這場AI競賽和當年的太空競賽沒什么兩樣,美國必須贏。
他在近期的播客中談到,DeepSeek之所以能在短時間內獲得巨大關注,一是因為它開源程度極高,采用了極其寬松的許可證;二是公開了推理過程,讓小模型能夠快速進行知識蒸餾,進一步降低訓練成本與加快推理速度。與之形成鮮明對比的是,為了鞏固自己在行業里的領先地位,冠著“Open”名號的OpenAI在發布o1時并沒有公開任何推理細節。

(Martin Casado在播客里)
Casado是工程師出身,在a16z專注于企業軟件、網絡安全、云計算和人工智能等領域的投資。
他還坦言,美國近年來的AI政策是失敗的——高密度、高強度的出口管制,試圖在芯片和軟件層面封鎖中國的AI發展,這樣的措施沒有達到預期效果,DeepSeek的崛起就是最好的證明。
“我們需要從一個更廣闊的視角來看待這個問題——中國確實有頂尖的AI研究團隊。DeepSeek其實已經發布過多個業界領先(SOTA)的模型,比如V3,可能比R1更具技術含量。類似于GPT-4,它們也是基于鏈式思維(Chain of Thought, CoT)進行推理的,而DeepSeek早就在這方面有所研究。”Casado說到。
當年的斯普特尼克讓美國重新思考自身科技與教育體系,同時加速了對太空探索的投入。如今,面對DeepSeek的崛起,更值得反思的是,在打著自由市場旗號的美國,OpenAI、谷歌、Anthropic 等 AI 巨頭大多優先考慮專有模型,而中國團隊則通過開源方式實現了突破性進展,進一步降低最前沿 AI 的門檻和成本,構建起蓬勃發展的AI生態系統。
對大公司而言,私有化模型有助于把控知識產權、強化自身在市場中的地位。然而,這種高度封閉的發展方式在高速演進的AI領域里,越來越難以滿足公眾對技術開放和透明度的期待,也可能成為創新與合作的桎梏。
在政府層面,白宮對AI領域實施的算力限制和代碼封鎖等舉措,不但沒有遏制中國的進步,反而在某種程度上束縛了美國自身的領先優勢。
a16z的另一位合伙人Alex Rampell更直截了當地指出,“拜登政府擔心如果美國的AI開源,中國會復制。但DeepSeek反其道而行之——現在是中國發布了開源AI,而美國的公司都想使用它或復刻它,因為它的性能實在太強了。”
開源曾是美國高科技領域里最引以為傲的“殺手锏”,早年的互聯網協議、操作系統、數據庫等關鍵技術,正是在廣泛開放的環境下得以快速迭代,助力美國牢牢把握信息革命的制高點。然而,近幾年由于對知識產權與商業收益的高度關注,再加上對國家安全和經濟制裁層面的考量,一些科技巨頭選擇更加封閉的研發模式,縮減了行業合作與創新的空間。
Rampell并不認為DeepSeek是“新的斯普特尼克時刻”,而是“給美國人民的禮物”:它讓“驕傲”的美國不得不正視全球AI競爭的現狀,加速在技術、人才和資金上的投入。
在這樣的大背景下,越來越多的科技人呼吁,美國的AI政策必須做出深層調整。繼續靠封鎖和管控來保持優勢,只會失去推動全行業整體躍升的機會。正如Meta首席人工智能科學家 Yann LeCun 在LinkedIn上所言:“對于那些看到DeepSeek表現、認為這是中國在人工智能領域超越美國的人來說,你們理解錯了。正確的解讀是開源模型正在超越專有模型。”
隨著AI競爭逐漸從單純追求更大規模、更多參數和更強算力,轉向注重應用與生態的深度整合,誰能讓大模型在不同行業場景中快速落地,并構建強大的協同網絡,誰就能在這場競賽中率先勝出。
英偉達CEO黃仁勛就曾強調,模型規模本身并不代表市場價值,真正能讓技術落地的,取決于能否與現實需求無縫對接;斯坦福大學教授吳恩達(Andrew Ng)也在演講中反復提到:解決實際問題、為用戶創造價值,才是所有大模型發展的根本目標。從醫療、金融到零售,每個行業都有不同的業務痛點和法規要求,促使研發團隊必須進行針對性的模型裁剪與定制。
在這種趨勢下,像DeepSeek這樣依托開放、彈性生態系統的團隊,不僅能為行業提供更低門檻的成長路線,還能不斷吸納開發者與合作伙伴,讓AI技術在更多應用場景釋放潛力,保持可持續發展。
OpenAI CEO Sam Altman也開始反思他的策略。在o3-mini發布會后,這位硅谷天才創業者與幾位高管在Reddit上回答網友提問,在問及是否會公開部分大模型權重時,Altman坦言:“我個人認為,我們在開源策略上可能走錯了方向,需要探索一種全新的開放模式。不過,并非所有OpenAI成員都認同這一觀點,而且目前這也并非我們的最高優先級。”
或許DeepSeek不僅是開源大模型的一次重大勝利,更是一份“送給世界的禮物”,將為整個行業樹立了全新的標桿。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

