- +1
我把DeepSeek裝進了電腦里:生成能力一般,但確實很好玩
這個春節假期,要說“紅得發紫”的科技產品,DeepSeek應該當之無愧。
甚至平時對科技新聞毫不在意的長輩們,也走過來問小雷有沒有聽說過DeepSeek。在我的印象中,上一次AI大模型如此深入人心的,還是OpenAI的ChatGPT。
大紅大紫的背后,是DeepSeek遭受連續且高強度的網絡攻擊,大部分時候官網都沒辦法正常生成內容,即便關閉聯網搜索,具備深度推理能力的DeepSeek-R1在線模型還是無法正常使用。好在,在華為等眾多科技公司的支持下,第三方平臺紛紛接入DeepSeek的API,讓穩定在線使用成為了可能。
不過這些渠道本質上還是線上訪問,春節期間休息的小雷,還想玩一把更大的,比如把DeepSeek大模型部署到本地。
于是,在春節期間,小雷動起手來實踐了一下。
下載慢還得敲代碼,打造“AI電腦”不容易
事實上,無論是不是DeepSeek,想要在自己電腦部署一個本地大模型,執行的步驟并不多,難點在于尋找到對應的資源和命令。但需要注意的一點是,本地大模型雖說是已經訓練好的成品,但也需要有一定的硬件基礎,體驗才算得上好。

(圖片來自Ollama)
首先,我們可以到Ollama官網下載一個桌面端應用,這個應用相當于一個承載本地大模型的“盒子”,除了DeepSeek之外,你可以在Ollama官網的模型庫中找到許多開源大模型。
Ollama桌面端并不提供任何控制界面,想要將大模型下載到本地,需要在Ollama官網的模型庫當中找到對應模型的代碼,復制到PowerShell(Win+R輸入PowerShell回車打開)當中,就可以執行模型數據的拉取和安裝。
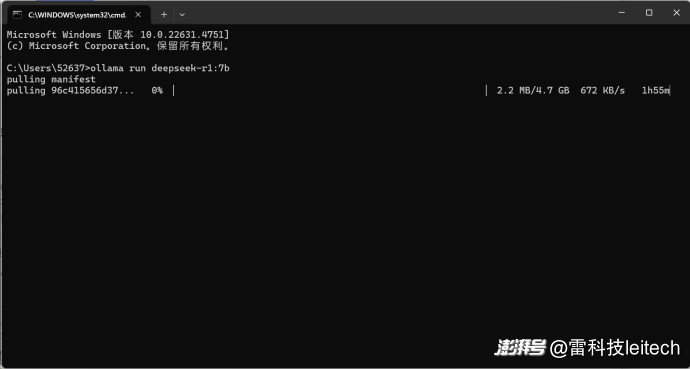
(圖片來自雷科技)
小雷選的是DeepSeek-R1模型當中的7b版本,也就是帶有70億參數的DeepSeek-R1模型,占用4.7GB。本地大模型參數量越大自然是越好,可以提供更精準的語言理解和更高質量的文本生成能力,具備更強的邏輯推理和學習能力,同時知識儲備和泛化能力。但本地大模型依賴電腦計算能力,每個人對大模型的需求不同,不應該“硬來”。
一般來說,運行1.5B參數的模型最低需要4GB顯存的GPU以及16GB的內存,如果達不到要求,則會強行使用CPU進行計算,硬件負擔更大,且推理的時間會更長。而滿血版的DeepSeek-R1參數量為671b,體積達到404GB,需要更高規格的計算硬件才能負擔得起,對于個人部署需求,小雷建議1.5b-8b參數最為適合。

(圖片來自雷科技)
模型數據拉取完畢,系統則會自動執行安裝,完成之后就可以直接在PowerShell窗口當中直接調取剛下載的DeepSeek-R1模型,輸入框填寫問題發送,本地大模型就會推理并生成。
到這里,DeepSeek-R1本地大模型的部署就完成了,理論上大家也可以根據這樣的方法去部署其它大模型上電腦。
但每次開啟電腦都要打開PowerShell界面才能激活大模型,對于普通用戶而言并不方便,這個時候我們需要給DeepSeek-R1安裝一套更直觀的交互界面。小雷選擇了在Docker應用(圖標是一個藍色海豚)上添加一個Open-WebUI組件,讓DeepSeek-R1可以通過瀏覽器界面交互,并賦予它聯系上下文的能力。
具體來看,需要先下載Docker桌面端,按照默認的引導完成安裝之后(可跳過賬號注冊等步驟),再次打開PowerShell界面復制并執行以下這條指令,小雷幫大家省下去Github查找的時間了:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
如果是使用NVIDIA GPU的小伙伴,則需要使用以下這條指令:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
拉取大模型文件和Open WebUI組件需要一個比較漫長的過程,尤其是網絡不太理想(或者沒有科學上網)的環境,下載器會不斷重試/切換線路,出現下載進度丟失的問題。
安裝完成之后,Docker應用中就會出現一個Open-WebUI的相關組件,把它勾選啟動,再點擊“3000:8080”字樣的鏈接,系統就會跳轉到網頁。
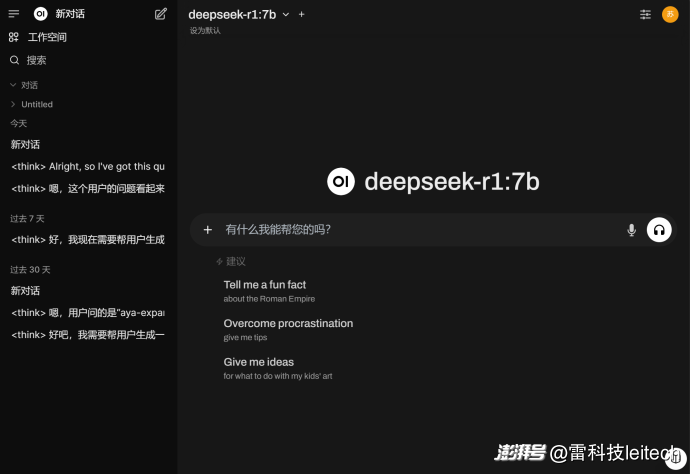
(圖片來自雷科技)
這個時候,你就獲得了一臺帶有AI本地大模型的真正的“AI電腦”了。
小雷體驗了整個部署過程,步驟并不算復雜,系統的數據拉取和安裝都是自動化的,主要還是在搜索命令行和安裝資源,以及拉取和安裝組件時花了比較多的時間,Ollama和Docker都可以通過百度搜索到,小雷也在上面提供了對應的跳轉鏈接,動手能力且有興趣的各位可以嘗試嘗試。
當然了,本地部署大模型的方法并不只有這一個,像華為剛推出的ModelEngine等,具備一站式訓練優化和一鍵部署的能力,應該是面向企業端的開發工具。
離線使用是好事,但生成能力不如云端版
國內的AI大模型應用選擇很多,而且網頁端服務很齊全,那么本地部署的意義在哪里?
前面鋪墊了這么多工作準備本地大模型,關鍵有兩點:第一,本地大模型的所有模型數據和對話記錄都是完全離線,存儲在本地,本地推理響應時間更快,也避免了敏感內容泄露。同時在飛機等無網環境之下,也可以正常使用大模型;第二,本地部署支持各種開源模型,個人用戶可以靈活擴展和切換,也可以根據自身需求進行優化和工具集成,總之操作空間會比線上大模型更多。
不過小雷部署的時間還不長,許多功能還沒摸清楚,這次就簡單討論一下本地大模型的體驗如何。
小雷安裝DeepSeek-R1 7b模型的電腦是機械革命無界14X,輕薄本定位,運行內存為24GB,并沒有配備獨立顯卡這種硬件,不在本地部署大模型的推薦配置范圍內,算是一個“反面教材”。換句話說,DeepSeek-R1 7b模型在這款電腦上,需要更多的推理時間和資源占用才能夠正常生成內容。
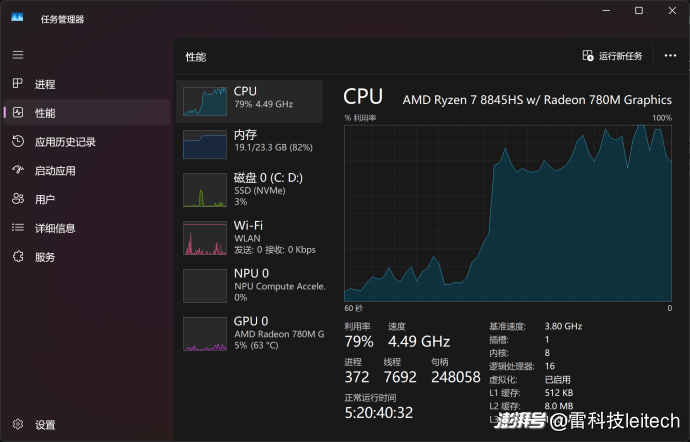
(圖片來自雷科技)
像“飯后脹氣”等問題的討論和答案,大模型需要思考30秒-1分鐘才到答案生成階段,期間電腦的負載會達到高峰,CPU和內存幾乎被占滿,可以想象沒有獨立顯卡的電腦帶動本地大模型會比較吃力,小雷認為給出的答案的確有一定的正向參考的作用。

(圖片來自雷科技)
相比于答案,小雷更感興趣的還是DeepSeek擬人化的思考過程,很少有AI助手把思考的過程做到如此擬人化,不管生成的答案是否準確,它的擬人化推理過程似乎也能激起許多普通用戶的興趣。
如果把同樣的問題放在網頁端的DeepSeek大模型,并啟用R1深度思考,直接生成了一個“服務器繁忙”的回饋,密集的訪問的確給DeepSeek造成了不少困擾,這個時候想要正常地和它交談,本地部署能力不一定很強,至少能夠訪問得到。
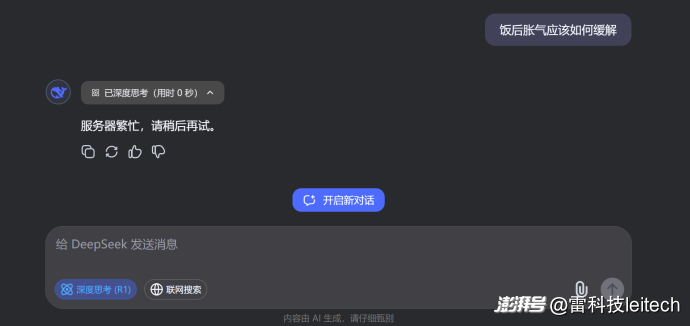
(圖片來自DeepSeek)
再換一個問題,小雷用了一道經典的概率題目向本地DeepSeek-R1 7b發起提問。網頁端DeepSeek-R1持續繁忙中,本地DeepSeek可能也有一些手足無措,列舉了多種情況后又自行駁回,最后還混入了之前提問的“飯后脹氣”的內容,畫面顯得相當滑稽。

(圖片來自雷科技)
本地DeepSeek在連續輸出十多分鐘后也沒有提供答案,考慮到時間有限,小雷還是停止了生成。
只能說數學題目對于70億參數的DeepSeek-R1 7b還是過于復雜,在線大模型都不一定能夠輸出準確答案,本地就更成問題了,同時高參數的本地大模型推理的過程中,電腦的負載壓力也會拉滿。
從開源的角度去分析,本地大模型的擴張性和可玩性會比傳統的線上大模型更好玩。但本地大模型的部署大家也很清楚,操作起來并不是很容易,想要挖掘更多玩法,還是要靠動手能力強的用戶。
本地部署DeepSeek,只是圖個新鮮好玩?
那么,本地大模型值得人手一個嗎?小雷的答案是否定的。
就現階段的生成能力來說,本地大模型很難跟線上大模型媲美,參數規模和計算能力擺在那,肯定沒法跟正規大模型公司背后的算力集群對比。本地大模型適合動手能力強的電腦用戶折騰,深度發掘的確能帶來一些功能上的便利,畢竟本地大模型在系統底層中運行,能夠更好地與硬件結合。
但作為普通用戶,部署本身也算不上是一件多容易的事情,大模型的周邊配套并沒有想象中成熟,Ollama官網全是英文,Docker應用也不提供中文支持,本身在部署上就有較高的門檻。小雷部署一個本地DeepSeek大模型,只是圖個新鮮,平均生成用時20秒起步,除了可以離線隨處用,普通的生成需求,體驗還是不如在線大模型。
像讀取文件分析、聯網收集數據分析這些能力,還需要用戶自己來折騰,小雷目前部署的DeepSeek還只是個開始。另外如果你有一天不用了想要刪掉大模型數據,還需要學習步驟來清除,否則它就會一直占用系統盤的存儲空間。

(圖片來自mockup)
在小雷看來,DeepSeek走開源道路,最主要的原因還是為了打響市場影響力,先行占據市場地位,吸引行業圍繞它來建立完善的服務體系。拋開Ollama這些不說,國內眾多大模型平臺率先接入DeepSeek的API,就是開源帶來的直接結果。
可以想象,攜帶超高熱度的DeepSeek完成各行業的應用和滲透,個人本地部署的需求也會變得遠比現在簡單,調起PowerShell界面、敲代碼這些事情甚至都不需要用戶來做。
至于DeepSeek會發展成什么樣,小雷還無法預測,被行業高度關注利大于弊,不穩定的服務只是短痛,能夠提高市場占比走到普通用戶身邊,滲透到各個設備,到那個時候,本地部署這件事情或許本身就沒有必要了。

本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

