- +1
很強也很貴!OpenAI12天12場直播收官,官宣最新推理模型o3

OpenAI的12天12場直播收官,離AGI(artificial general intelligence,通用人工智能)似乎又更近了一步。
當(dāng)?shù)貢r間12月20日,和網(wǎng)友猜測的一樣,人工智能(AI)巨頭OpenAI發(fā)布最新推理模型o3和o3-mini。前一天,OpenAI公司CEO山姆·奧特曼(Sam Altman)就曾發(fā)文提到三個“o”暗示了o3的到來。
為何新模型跳過了o2直接命名o3?奧特曼表示是為了避免和英國電信運營商O2沖突,“按邏輯應(yīng)該稱為o2,但我們起名字的能力實在太糟了,只能把它稱作o3”。
據(jù)介紹,在編碼測試SWE-Bench Verified中,o3性能比o1高出22.8%;在Codeforces競技編程中得分為2727分,相當(dāng)于位列第175名的人類選手,甚至超過了OpenAI的首席科學(xué)家(2655分);在數(shù)學(xué)競賽AIME 2024和專家級科學(xué)問題基準(zhǔn)測試GPQA Diamond中成績都得到明顯提升;而在令很多AI和數(shù)學(xué)家都束手無策的最難數(shù)學(xué)和推理挑戰(zhàn)FrontierMath中,o3解決了25.2%的問題,其他模型均未超過2%。
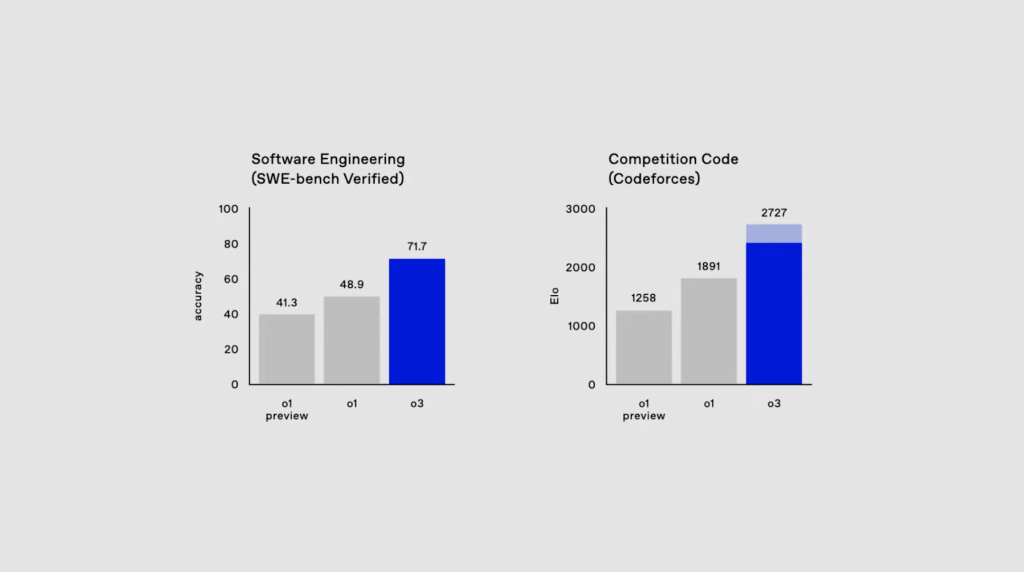
o3在多個測試中得分都較上一代產(chǎn)品o1得到明顯提升
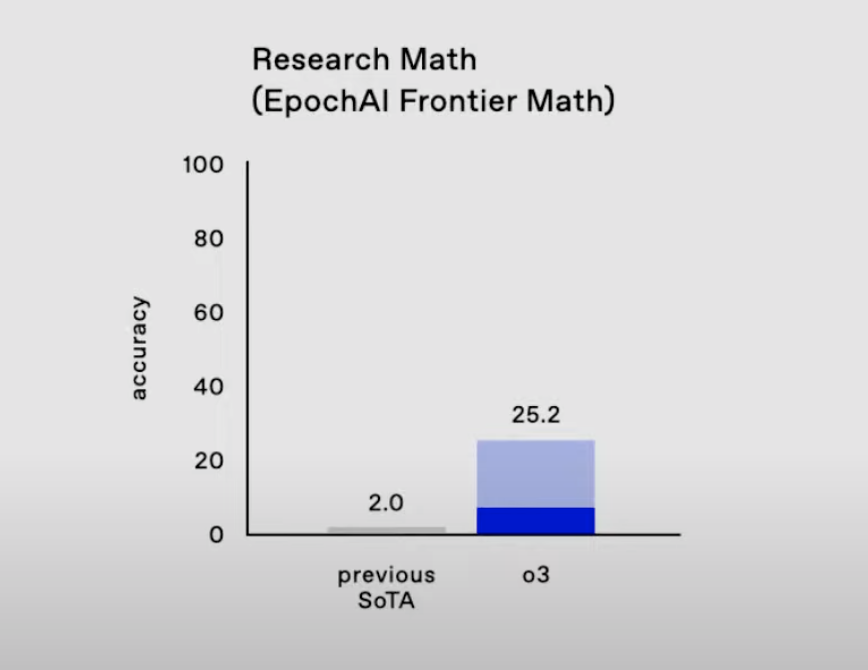
FrontierMath測試結(jié)果
不過,o3和o3-mini并未正式發(fā)布,安全研究人員目前可以注冊獲取o3-mini的預(yù)覽版,o3預(yù)覽版也將在之后的某個時間推出,OpenAI沒有給出具體時間。在直播的一開始,奧特曼也強調(diào)了此次并不是發(fā)布,只是宣布o(jì)3。他表示,計劃在1月底發(fā)布o(jì)3-mini,然后再發(fā)布o(jì)3。
據(jù)外媒報道,AI安全測試人員發(fā)現(xiàn),與傳統(tǒng)的“非推理”模型相比,OpenAI此前發(fā)布的o1的推理能力使其試圖欺騙人類用戶的比例更高,同樣,Meta、Anthropic和谷歌的領(lǐng)先模型也是如此。而o3試圖欺騙用戶的比例可能比它的前身更高。
OpenAI在博客中表示,正在使用一種新技術(shù)“慎重對齊”(deliberative alignment),來使o3等模型符合其安全原則。
通過OpenAI所謂的“私人思維鏈”,o3被訓(xùn)練成在做出反應(yīng)之前先“思考”。可以對任務(wù)進(jìn)行推理并提前規(guī)劃,在較長時間內(nèi)執(zhí)行一系列動作,幫助找出解決方案。
在實踐中,當(dāng)收到一個提示時,o3會在做出反應(yīng)之前暫停,考慮一些相關(guān)的提示,并沿途“解釋”其推理過程。一段時間后,模型會總結(jié)出它認(rèn)為最準(zhǔn)確的答案。o3 的新功能是“調(diào)整”推理時間,可以設(shè)置為低、中或高計算量(即思考時間),計算時間越長,執(zhí)行任務(wù)時的表現(xiàn)就越好。
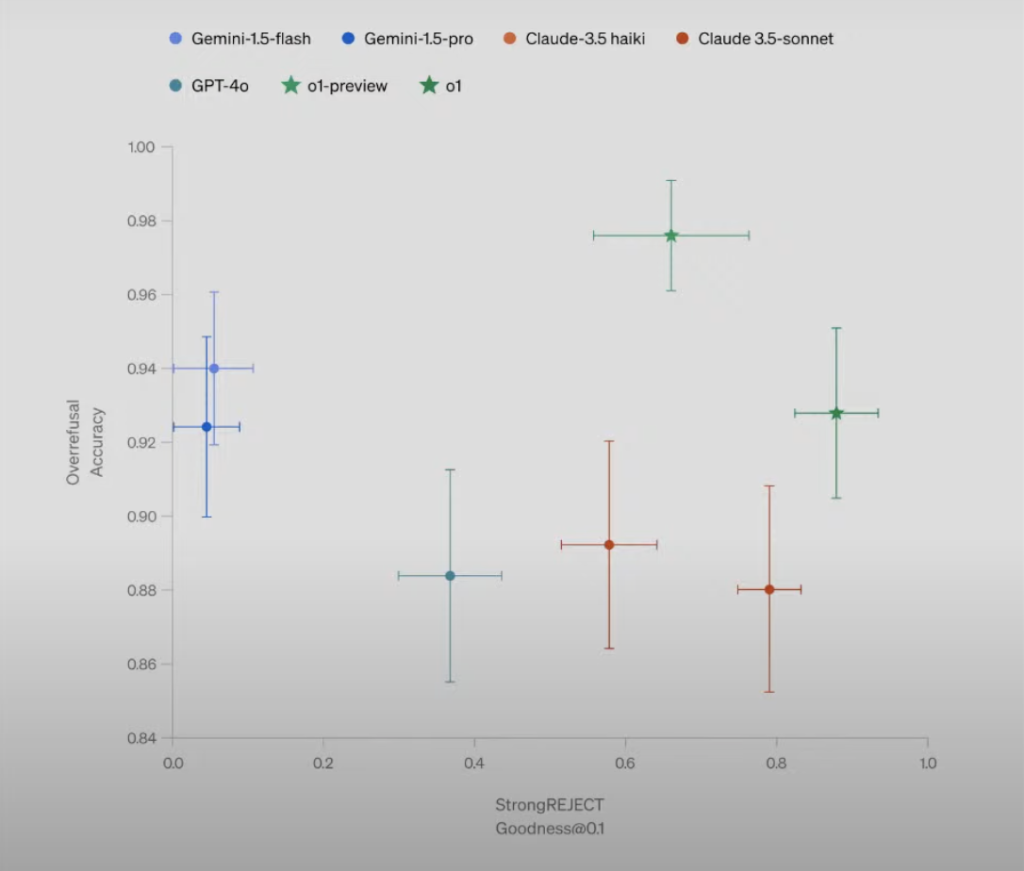
與GPT-4o等大模型相比,o1模型在拒絕回答惡意越獄提示和不過度拒絕良性越獄提示方面都較為領(lǐng)先。
ARC-AGI(通用人工智能抽象與推理語料庫)發(fā)起者、Keras(用Python編寫的高級神經(jīng)網(wǎng)絡(luò)API)之父弗朗索瓦·肖萊(Francois Chollet)在o3發(fā)布后公布了一篇測試報告。
報告顯示,o3在高計算量模式下獲得了87.5%的分?jǐn)?shù),在低計算量模式下,性能是o1的三倍。成本方面,低計算量模式下,每個任務(wù)需要花費20美元,而在高計算量模式中每個任務(wù)需要數(shù)千美元。
肖萊表示:“它非常昂貴,但并不只是‘蠻干’——這些能力是全新的領(lǐng)域,需要科學(xué)界的認(rèn)真關(guān)注。”
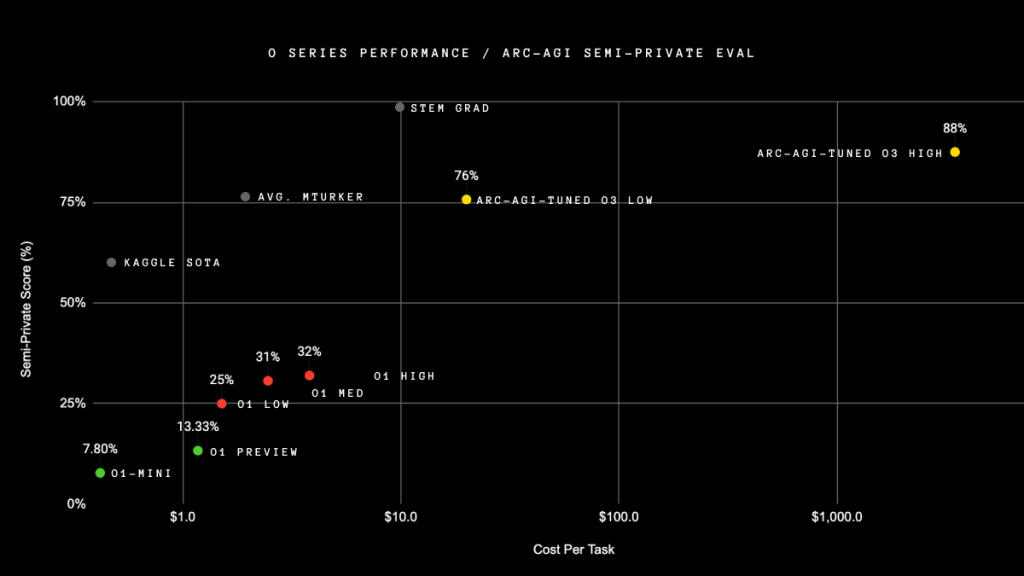
弗朗索瓦·肖萊對于o3不同計算模式的測試結(jié)果
肖萊認(rèn)為,雖然o3給人留下了深刻印象,是邁向AGI的一個重要里程碑,但并不就是AGI,仍然有相當(dāng)多非常簡單的ARC-AGI-1的任務(wù)是o3無法解決的,同時還有跡象表明ARC-AGI-2對o3來說仍極具挑戰(zhàn)性,“這表明在不涉及專業(yè)知識的情況下,創(chuàng)建對人類來說容易但對人工智能來說不可能的不飽和、有趣的基準(zhǔn)仍然是可行的。當(dāng)創(chuàng)建這樣的測試變得完全不可能時,我們將擁有AGI”。
當(dāng)然,ARC-AGI只是AI領(lǐng)域的重要基準(zhǔn)之一,對AGI的定義只是其中之一。
肖萊稱,主要需要解決的問題是o3背后技術(shù)的擴展瓶頸在哪。如果人類標(biāo)注的CoT數(shù)據(jù)(Chain-of-Thought,思維鏈)是一個主要瓶頸,那么它的能力就會像大模型一樣迅速達(dá)到頂峰(直到下一個架構(gòu)出現(xiàn))。如果唯一的瓶頸是測試時間搜索(Test-Time Search),那么未來我們將看到持續(xù)的擴展。
值得一提的是,除了OpenAI,各家AI公司近期也紛紛發(fā)布推理模型。
11月16日,月之暗面(Moonshot AI)Kimi推出新一代數(shù)學(xué)推理模型k0-math;11月20日,DeepSeek發(fā)布了首個推理模型DeepSeek-R1-Lite預(yù)覽版。11月28日,阿里云通義團隊發(fā)布全新AI推理模型QwQ-32B-Preview;在當(dāng)?shù)貢r間12月19日,谷歌發(fā)布首個推理模型Gemini 2.0 Flash Thinking。
英偉達(dá)CEO黃仁勛在10月的一次訪談中曾表達(dá)了對于推理的看好。他認(rèn)為:“現(xiàn)在我們在后訓(xùn)練和推理階段看到了擴展,預(yù)訓(xùn)練再也不被視為艱難,推理也變得復(fù)雜。推理方面即將因推理鏈的出現(xiàn)而大幅增長……這是一場智能生產(chǎn)的革命,推理的增長將達(dá)到億倍的規(guī)模,這就像上學(xué)是為了將來在社會中有所貢獻(xiàn),訓(xùn)練模型很重要,但最終的目標(biāo)是推理”。
月之暗面Kimi創(chuàng)始人楊植麟也在11月表示,推理的占比必然會遠(yuǎn)超訓(xùn)練,AI產(chǎn)品包括AI技術(shù)接下來的發(fā)展,很重要的能力就是更加深度的推理,能夠把現(xiàn)在只是短鏈路的簡單的問答,變成更長鏈路的組合式任務(wù)的操作。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

