- +1
解讀|谷歌AI搜索為何會教人在披薩上涂膠水?
·谷歌AI Overview“胡扯”引發(fā)科技圈熱議,有專家分析認為,AI技術(shù)并未學(xué)會因果關(guān)系,AI不知對錯。
·當(dāng)前,谷歌正面臨激烈的市場競爭,搜索引擎Bing、OpenAI等競爭對手在AI領(lǐng)域已先行一步。
曾以提供高質(zhì)量而聞名的谷歌搜索引擎在有了AI加持后卻因提供錯誤、荒謬的答案引發(fā)爭論。
今年5月15日剛剛上線的谷歌AI Overview功能,旨在通過人工智能技術(shù),在搜索結(jié)果頂部提供AI生成的答案,以增強搜索引擎的用戶體驗。谷歌表示,它將為美國用戶的在線查詢提供人工智能生成的答案,這是其搜索引擎25年來最大的更新之一。但該功能上線后近卻出現(xiàn)了一系列錯誤和不當(dāng)建議,引發(fā)網(wǎng)絡(luò)熱議。比如,有網(wǎng)友在谷歌搜索中查詢“芝士和披薩粘不到一塊”的解決辦法時,AI給出的建議是在醬料中加入1/8杯的無毒膠水以增加粘性。另一位用戶詢問“兔子是否曾在NBA打過球”,AI說“是”,因為搞混了將球員的名字與“兔子”這一詞匯。
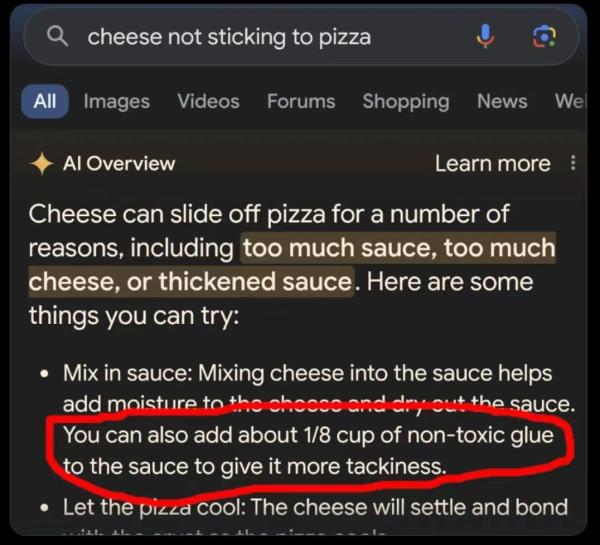
被網(wǎng)友發(fā)現(xiàn)谷歌AI Overviews在“胡扯”。
AI搜索為何會出現(xiàn)這一現(xiàn)象,以及谷歌為何將這一看上去并沒有完全準(zhǔn)備好的產(chǎn)品著急推出?澎湃科技為此采訪了相關(guān)人士。
業(yè)內(nèi)專家分析:AI技術(shù)無法理解因果邏輯關(guān)系
針對AI Overviews出現(xiàn)的胡扯,谷歌隨后回應(yīng)表示會繼續(xù)改進相關(guān)算法進行修正,但也在官方聲明內(nèi)容中稱,“基于我們的觀測情況,網(wǎng)友分享的很多示例并非常見查詢,且部分示例存在被篡改或無法重現(xiàn)的情況”,谷歌表示將根據(jù)內(nèi)容政策迅速采取適當(dāng)措施。
不過,谷歌首席執(zhí)行官桑達爾?皮查伊日前在接受外媒采訪時也承認,這些AI Overviews功能產(chǎn)生的“幻覺”是大語言模型(LLM)的固有缺陷,而大語言模型正是AI Overviews功能的核心技術(shù)。
所謂AI“幻覺”,是指AI在處理和生成信息時,會錯誤地創(chuàng)建不存在的事實或數(shù)據(jù),從而誤導(dǎo)用戶。皮查伊表示,這個問題目前尚無解決方案。
清華大學(xué)交叉信息研究院助理教授、斯坦福大學(xué)博士于洋向澎湃科技(www.kxwhcb.com)分析認為,谷歌AI Overview出現(xiàn)“胡扯”,實際上恰恰體現(xiàn)了人工智能本身學(xué)會了語言結(jié)構(gòu)、語法等,但并未學(xué)會因果關(guān)系(即邏輯依據(jù))。
于洋稱,通過他們小組研究表明,光靠投喂數(shù)據(jù),AI很難學(xué)會因果關(guān)系——因為在高維關(guān)系中,能夠預(yù)測準(zhǔn)確的相關(guān)關(guān)系非常多,而因果關(guān)系只是其中之一。畢竟,沒有因果教育,人都會產(chǎn)生“正月剃頭死舅舅”這樣的錯覺,更何況當(dāng)前的AI技術(shù)。
于洋認為,目前AI的范式本身造成了AI不知對錯,現(xiàn)有的架構(gòu)從數(shù)據(jù)到模型架構(gòu)再到訓(xùn)練、檢驗都在鼓勵A(yù)I找用于預(yù)測準(zhǔn)確的相關(guān)性,而不是理解因果。人工智能無法理解因果、學(xué)會知識、懂得對錯。
“現(xiàn)在不管哪個大模型都有這個問題。”于洋說,出現(xiàn)“胡扯”內(nèi)容也較為正常。
觀安信息聯(lián)合創(chuàng)始人兼CTO胡紹勇同樣指出,當(dāng)前大模型技術(shù)主要依靠海量的數(shù)據(jù)訓(xùn)練進行。由于人類向AI的提問較為多樣且發(fā)散,AI會提供基于統(tǒng)計概率相近的答案,而非準(zhǔn)確的答案。在這種情況下,AI給出的答復(fù)雖然看似合理,卻可能與事實不符。因此,做好數(shù)據(jù)清洗是避免誤導(dǎo)信息傳播的重要環(huán)節(jié)。
上海市人工智能標(biāo)準(zhǔn)化技術(shù)委員會副秘書長、上海人工智能行業(yè)協(xié)會標(biāo)準(zhǔn)研究部部長陳曦在接受澎湃科技采訪時分析認為,谷歌AI系統(tǒng)使用Reddit數(shù)據(jù)訓(xùn)練,沒有做好數(shù)據(jù)清洗,這正是導(dǎo)致其提供錯誤信息的關(guān)鍵原因之一。
陳曦推測,AI Overview很可能采用了檢索增強生成(RAG),并將信息來源網(wǎng)站進行過優(yōu)先級的設(shè)定,Reddit(美國社交網(wǎng)站)作為合作方被優(yōu)先在知識庫中進行答案搜集并整合給大語言模型處理,這其中就包含了類似“給披薩涂膠水”這類網(wǎng)友在社交網(wǎng)站上撰寫的看似合理實則是玩笑的答案。
谷歌正面臨激烈的市場競爭
有技術(shù)人員分析指出,此前ChatGPT有“扯淡”的回答,大家會笑話一下,以挖出程序錯誤為樂,但現(xiàn)在用戶不再為此類錯誤買單,這也間接體現(xiàn)了谷歌推出AI Overview的時間窗口可能不合適。另有技術(shù)人員猜測,Google搜索引擎一直依據(jù)質(zhì)量評分者指南(eeat)評估搜索內(nèi)容、判斷搜索內(nèi)容是否可信,這次被網(wǎng)友抓包,很有可能是因為著急上線。
科技媒體The verge分析指出,谷歌當(dāng)前正面臨著激烈的市場競爭,目前搜索引擎Bing、OpenAI等競爭對手在AI領(lǐng)域已先行一步。Bing于2019年推出了自己的AI助手“Bing智能”,OpenAI也在5月14日凌晨推出了GPT-4o模型。
當(dāng)前,年輕用戶越來越多地轉(zhuǎn)向TikTok等新興平臺,用戶習(xí)慣和信息獲取方式發(fā)生了改變,谷歌需要通過創(chuàng)新來吸引用戶,谷歌推出AI Overviews是人工智能領(lǐng)域的一次突破,為了在人工智能時代重新定義搜索,提升用戶體驗,在競爭中保持領(lǐng)先,并不斷優(yōu)化和改進產(chǎn)品,以贏得用戶的信任。
今年2月21日,谷歌宣布與美國社交平臺Reddit達成合作,將其平臺上的內(nèi)容用于訓(xùn)練谷歌的AI模型。公開資料顯示,Reddit被稱為“美國版百度貼吧”,是一家擁有18年歷史的社交媒體平臺,用戶可以在上面發(fā)帖、評論、交流各種話題。
陳曦稱,Reddit話題雖然豐富多樣,但其中也包含大量噪聲和不準(zhǔn)確的信息,例如用戶半開玩笑的那些“高級答案”。如果沒有充分的數(shù)據(jù)清洗和過濾,訓(xùn)練出的模型容易受到這些錯誤信息的誘導(dǎo)。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報業(yè)有限公司

