- +1
落地端側,2B模型如何以小搏大?|對話面壁CEO李大海

文|郝 鑫
“AGI是一場馬拉松”,面壁智能聯合創始人、CEO,知乎CTO李大海道。
作為一個馬拉松的愛好者,李大海深知在大模型的競爭中,一時的“快”只是暫時的,更重要的是把賽程中的每一步都跑下來,跑踏實。
回顧面壁智能的發展歷程也確實如此,2018年脫胎于清華NLP實驗室,發布了全球首個知識指導的預訓練模型ERNIE;2020年成為悟道大模型的首發主力陣容;2022年成立OpenBMB開源社區;2022年面壁智能開始公司化運作;2023年把Agent作為主要發力方向,相繼發布了AgentVerse、ChatDev、XAgent等智能企業框架。

從大模型Infra層到Agent應用層,從科學實驗室到商業化落地,夯實走的過程中,逐漸演化為了2023年的沖刺能力。去年,就在國內外還在研究Agent定義的時間點,面壁智能已經率先在行業內提出了群體智能的框架和Agent商業化落地的方案。
2024年,大模型應用新篇章即將開啟之際,面壁智能又出乎意料地發布了端側大模型和面壁MiniCPM。
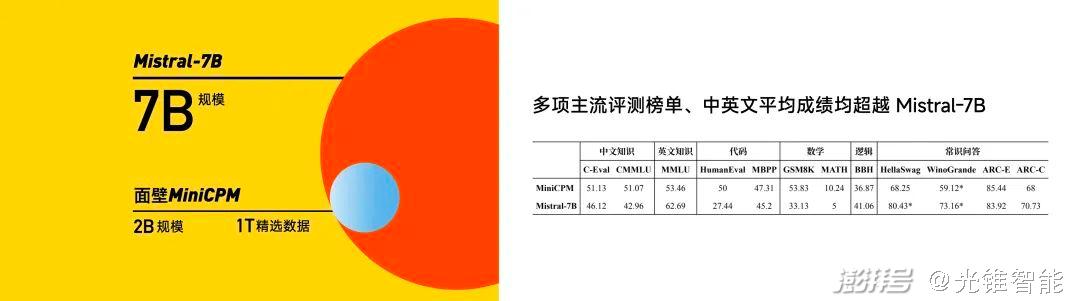
對標國外Mistral-7B,核心就是以最小的模型規模,實現最強的模型效果,這項能力被李大海總結為“以小搏大”、“以大搏聚”,這也是面壁智能的核心能力之一。
從各項結果來看,小鋼炮MiniCPM用2B的規模、1T的精選數據,從性能指標上打敗了Mistral-7B、微軟明星模型Phi-2、蒸餾GPT-4、13BLLaMA等一眾主流模型。并且將模型部署的成本徹底打了下來,在側端,1元=1700000tokens,僅是MiniCPM在云端的1%。
從大模型到Agent,再到側端模型,總體來看面壁智能的布局,可以發現其已經在為大模型應用的落地和爆發做準備。大模型提供底座能力支撐,Agent做為腳手架打通應用的“最后一公里”,最后在側端進行部署和運行。
正如李大海所言,“側端模型能夠為大模型和Agent服務,因為端跟云的協同能夠更好得讓應用落地。端側模型是大模型技術的積累,在如何把模型小型化,讓云上的模型能夠用更小的規模實現更好的效果方面,是一脈相承的關系。”
2024年已經緩緩拉開了帷幕,大模型戰事瞬息萬變。光錐智能對話面壁智能聯合創始人、CEO,知乎CTO李大海和其團隊,深入探究面壁智能核心競爭力的修煉秘密,同時展望2024年的大模型行業格局。
核心觀點如下:
1、“以小搏大”、“以大搏聚”,用2B的模型做出了比2B模型更大的模型效果。
2、“沙盒實驗”就是在一個模擬仿真的環境里面,用更小的成本和代價去搞清楚規律。
3、端側大模型不能只看端側,未來一定是云端協同。
4、Agent私有化部署成本有兩塊,一是模型廠商對模型使用收費,一是客戶部署完以后的推理成本。
5、面壁智能的差異化競爭策略可以總結為,高效和一體化,即高效推理和模型+Agent一體化。
6、CV是一個單點技術的突破,而大模型是在各個技術點上探索和升級,還遠遠未達到技術成熟階段。
以下為對話實錄:
Q:為什么選擇在2024年開端時候,發布MiniCPM側端大模型?出于怎樣的考慮?
A:在MiniCPM的背后,是做了上千次的沙盒實驗,在這過程中我們掌握了“以小搏大”、“以大搏聚”的能力。正如大家所見,我們用2B的模型做出了比2B模型更大的模型效果。這個核心能力,我們本來打算運用到未來新的模型研發上。但我們發現,現階段,“以小搏大”、“以大搏聚”的能力,運用到端側上能夠產生突破性的進展,所以這才促使我們把模型趕緊做出來。真正做出MiniCPM時間不到一周,根本上得益于過去上千次的實驗積累,而這些工作面壁智能在2023年就已經完成,所以MiniCPM可以看作一個厚積薄發的結果。

Q:您剛才提到“沙盒實驗”在面壁智能模型訓練中起到了重要的作用,可以展開闡釋一下嗎?
A:用形象的比喻來解釋,沙盒實驗就像就像航空里面的“風洞實驗”。
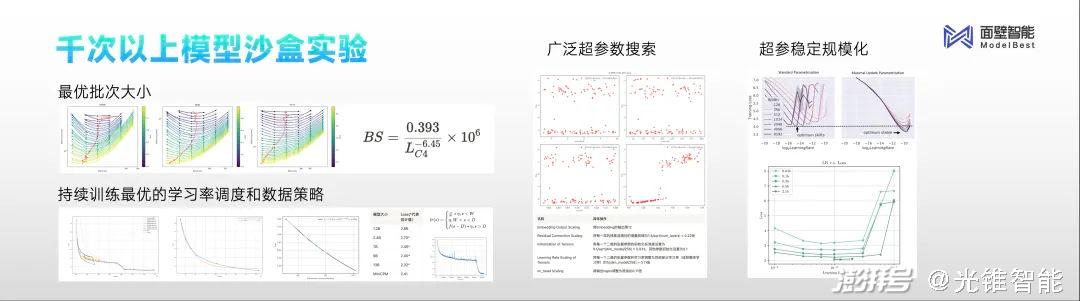
“沙盒實驗”就是在一個模擬仿真的環境里面,用更小的成本和代價去搞清楚規律。我們希望通過這種方式,來搞清楚用什么訓練方式能夠得到何種表現規模的模型,這就是“沙盒實驗”整體的目的和方法論。
我們發布MiniCPM之前做了上千次的模型沙盒實驗,探索出了最優的配制,所有尺寸的模型可以通過最優的超參數的配制,保證訓練任意大小的模型取得最好的效果。
通過上千次實驗,最終可以幫助我們去學習,從特別小的模型,遠比MiniCPM還小的模型到千億甚至比千億還大的模型的訓練控制方法,以便最后得到更好的模型訓練效果,從這個角度來看,不管是端側模型還是千億級模型,甚至更大的模型,面壁智能的“沙盒實驗”過程都能被覆蓋。
Q:MiniCPM僅用了1T的數據量就完成了模型訓練效果,聯系到您知乎CTO的身份,數據的來源與知乎有多大的關系?
A:我們精選了1T的數據,篩選的一個重要標準就是要展現數據的多樣性。知乎的高質量數據在模型訓練過程中起到十分重要的作用,具體的方法就是,以非常細的顆粒度去把數據打散后,做算法的自動選取。
Q:此次面壁開源了MiniCPM全家桶,作為創業公司,面壁智能如何看待開源這件事?這回為什么選擇開源側端大模型?
A:面壁智能在2022年就成立了開源社區。面壁智能一直是開源的受益者,這也是團隊能在AI領域走得比較快的原因。所以從我們團隊成立之初,就秉承開源、開放的特點,人人為我,我為人人,能為整個行業做貢獻,我覺得還是非常重要的。
另一方面,開源對建立影響力非常重要,有了影響力隨之能帶來資本的注意力、人才的注意力以及2B的客戶注意力,這些其實都是建立商業邏輯的基礎。
談到側端大模型的開發,雖然相對云端的大模型來說,是一個小模型,但實際上開發仍是一個特別復雜和龐大的任務。這里面涉及的技術難點有兩個,一個是除了要能做出更小的模型,還得能釋放出更大的性能;此外,模型推理、硬件推理性能、各層面的適配等等,都存在很多技術難點。面壁智能選擇開源,也是希望能和手機廠商、APP開發者和領域專家合作,促成技術創新,達成更高效的解決方案,推動整個生態系統的繁榮。
Q:市場上很多手機廠商相繼推出了各自的大模型,那未來面壁智能和這些手機廠商的關系是怎樣的?大模型公司又如何切入到手機端側市場中去呢?
A:端側大模型不能只看端側,未來一定是云端協同。云上的模型跟端側的模型需要聯動,這就意味著由同一廠商來做聯動會更高效。以這個邏輯去推演,最終云側和端側的模型最好都是由專業的模型開發者去做。整體來看,這個事持續投入的門檻其實還蠻高的,所以我們不是特別建議手機廠商去持續的做這個事情,我覺得每個公司都有自己的商業考量。
Q:Agent在落地的過程中會遇到很多敏感的隱私數據,面壁智能在與企業合作中是如何解決數據痛點的?成本規模大概是多少?
A:在Agent落地方面,我們其實也在考慮這個問題,對于數據敏感型的客戶,我們會做私有化部署方案來解決他們的需求。
私有化部署層面的成本主要分為兩方面。一個是模型廠商對模型使用收費,另一個是客戶真正部署完以后的推理成本。正是基于此,當特別大的模型完成私有化部署后,對客戶來說,其推理成本就會變成一個比較大的成本障礙。在我們看來,不同的模型尺寸,有它所具備的能力和適配的場景,比如7B的模型大小,對標GPT-4的效果。
Q:在整個大模型市場中,跟頭部大模型公司相比,面壁智能差異化競爭策略是什么?
A:面壁智能角色定位為商業公司,NLP實驗室定位為科研,由于我們在產學研結合上有非常深厚的優勢,所以面壁智能在模型Infra和Agent層面都有相應的積累,未來還是會繼續擴大我們在技術上的優勢。同時,也通過開源去團結更多的伙伴,一言以蔽之,面壁智能的差異化競爭策略可以總結為,高效和一體化,即高效推理和模型+Agent一體化。
Q:目前,面壁智能的主要目標客戶是什么?主要收入來源有哪些?是如何思考商業化的?
A:因為我們C端產品才剛剛上線,所以目前商業收入來源主要來自B端客戶。現在標桿客戶有招商銀行、西門子、中國易車網等一些比較知名的客戶,集中在金融和營銷等領域。我們跟易車剛剛達成了深度的戰略合作,跟義烏小商品市場集團也達成了很重要的戰略化合作態,這些都是在營銷領域的一些重要成果。目前,端側大模型的商業化模式還尚在探索之中。
Q:新的一年,面壁智能的戰略規劃是什么?2B和2C方向是如何選擇的?作為公司的CEO,你的關注點有哪些?
A:整個2024年,面壁智能依然會堅持大模型+Agent的雙引擎戰略。

一方面,要繼續推進提升我們的模型能力,在端側已經發布了端側模型,同時今年仍然會去繼續提升基座模型能力,挑戰GPT-4的能力;另一方面,要用Agent來解決大模型落地最后一公里的問題,提升落地效率,在此方向上,我們甚至制定了一個比較激進的收入目標。因為我們相信,大模型真的能夠去給客戶帶來效率和效益的提升,也比較看好整個大模型市場。
在2B和2C方向選擇上,其實并沒有明確的劃分,因為在我們看來都是大模型+Agent的上層應用,所以我們并沒有把重點放在具體的哪個應用方向上。在現階段,前端的應用落地比較聚焦,在C端方向,我們會特別關注情感陪伴這個方向,也就是給用戶提供情緒價值。
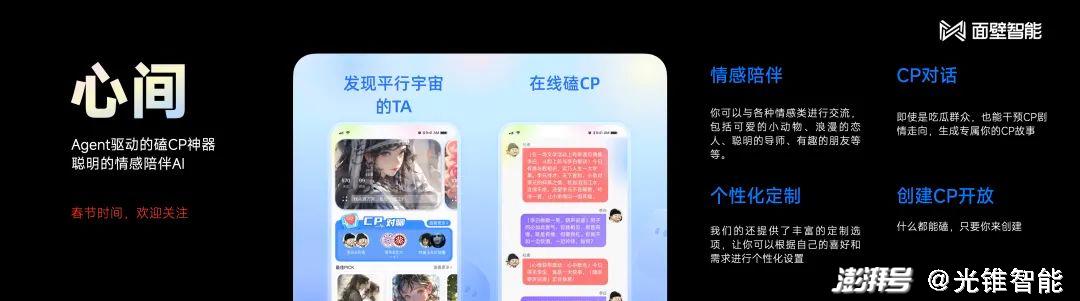
比如,我們開發的“心間”應用上線了測試版本,里面有個特色功能叫做磕CP,內置了李白杜甫和清華北大的CP,用戶也可以制造自己的CP,背后是用大模型做的推理。
從我自己關心的事情上來說,因為面壁智能在模型訓練方面的積累已經非常深厚了,所以對我們模型能力提升還是蠻有信心的。對我們而言,這個方向的確定性比較高。未來,我個人其實會更關心模型落地,也就是應用的問題。
Q:行業內都在談論2024年是模型轉應用的一年,您如何看待這一趨勢?以您的角度來看,未來市場競爭中是否還需要這么多的大模型廠商?最終什么樣的模型廠商能夠跑出來呢?
A:整個24年,行業都會更重視應用的落地,這是個大趨勢。目前模型已經達到基本可用的狀態,在這樣的基礎上去發展應用,我覺得是一個順理成章的趨勢。我們發布的“心間”,就是面壁智能在應用層積極布局的表現。
但我們認為,AGI就像馬拉松比賽一樣,是需要長期努力的目標,需要各個公司在技術上持續的積累。
從廠商分布來看,從2024年開始,大模型廠商會開始出現分層。我自己判斷,分層出現的原因不是市場所導致的,更多還是因為技術,隨著大模型的發展,技術的門檻會越來越高。
在市場層面,我認為大模型是一個行業級別的機會。我們看到,無論是做大模型基座,還是做應用,都有非常大的空間。因為市場足夠大,所以很多公司可能都有機會能生存下來,最終能活下來的公司,一定是技術、產品和市場能力都很強的選手。
Q:就像您所說“AGI是一場馬拉松”,這樣的發展特性,對未來的行業格局變化有怎樣的影響?
A:這回給行業格局洗牌帶來許多不確定性,以我的觀察,我覺得這不是2024年、2025年,甚至2026年能夠分出勝負的事情。
回首過去CV發展的情況,會發現AI 1.0的競爭格局也不是在頭兩年確定的,即使到了第三個年頭還是在發生非常大的變化,所以這啟示我們要以長遠的眼光看待行業的變化。當然,跟AI 1.0時代相比,2.0智能時代最大的差別在于,CV是一個單點技術的突破,而大模型是在各個技術點上探索和升級,還遠遠未達到技術成熟階段。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

