- +1
如何跳出推薦算法的信息繭房?Nature子刊闡釋人與AI自適應動力學推動繭房涌現
原創 劉志航 集智俱樂部=

導語
基于 AI 技術的推薦系統為我們高效地呈現了豐富的個性化內容,成功避免了信息的過度泛濫。然而,這種技術卻無聲息地將我們束縛在信息繭房內,讓我們不知不覺陷入單調內容的漩渦,無形中加深了我們的固有偏見。清華大學的研究團隊近期在 Nature Machine Intelligence 期刊上發表研究,利用兩大數據集并構建了一個描述人類與推薦系統自適應的動力學模型,深入探討了信息繭房的涌現機制,并為我們提供了突破這一繭房的實用策略。
研究領域:信息繭房,自適應動力學,信息熵,反饋機制,推薦算法
劉志航 | 作者

論文題目:
Human–AI adaptive dynamics drives the emergence of information cocoons
論文鏈接:
https://www.nature.com/articles/s42256-023-00731-4
1. 推薦算法背后的信息繭房
無論是新聞媒體,短視頻娛樂還是線上交友和購物,基于人工智能的推薦算法已經滲透到現代生活的方方面面,幫助我們篩選和消化海量的在線信息。然而,這些系統是否總是為我們提供了真正有價值、多樣化的信息呢?還是在無形中將我們限制在一個狹窄的信息繭房中,使我們陷入單一內容的陷阱?
“信息繭房”(Information Cocoon)這一術語形象地描述了一個人僅僅被展示與其過去的喜好、行為和觀點相符的信息,而與外部多樣化的信息隔離的狀態。這種現象可能導致社會的兩極分化,加劇人們的偏見和刻板印象,抑制創新和創造力,甚至影響決策的質量。
現代搜索引擎和社交媒體通過算法為用戶提供個性化內容,結合人們的選擇性曝露和社交媒體的回聲室效應,導致了信息繭房的形成。盡管以往研究探討了這些現象之間的相關性,但深度學習的“黑箱”特性和缺乏對人與AI之間共同演化機制的深入了解,使得信息繭房的根本機制仍是一個謎團。
在最新發表于 Nature Machine Intelligence 的一項研究中,清華大學的研究團隊使用了兩大數據集來探索我們如何與AI互動。其中一個數據集來自中國的熱門短視頻平臺,記錄了超過11萬新用戶的行為,另一個數據集則來自 Microsoft News,涵蓋了14個新聞主題和9萬用戶的互動。令人驚訝的是,研究發現大部分的用戶在與AI互動后,接觸到的信息種類實際上減少了(圖1a-c),這意味著他們可能被困在了所謂的“信息繭房”中。這項發現引發了一個緊迫的問題:是什么使得我們在與AI的日常互動中逐漸失去了信息的多樣性?
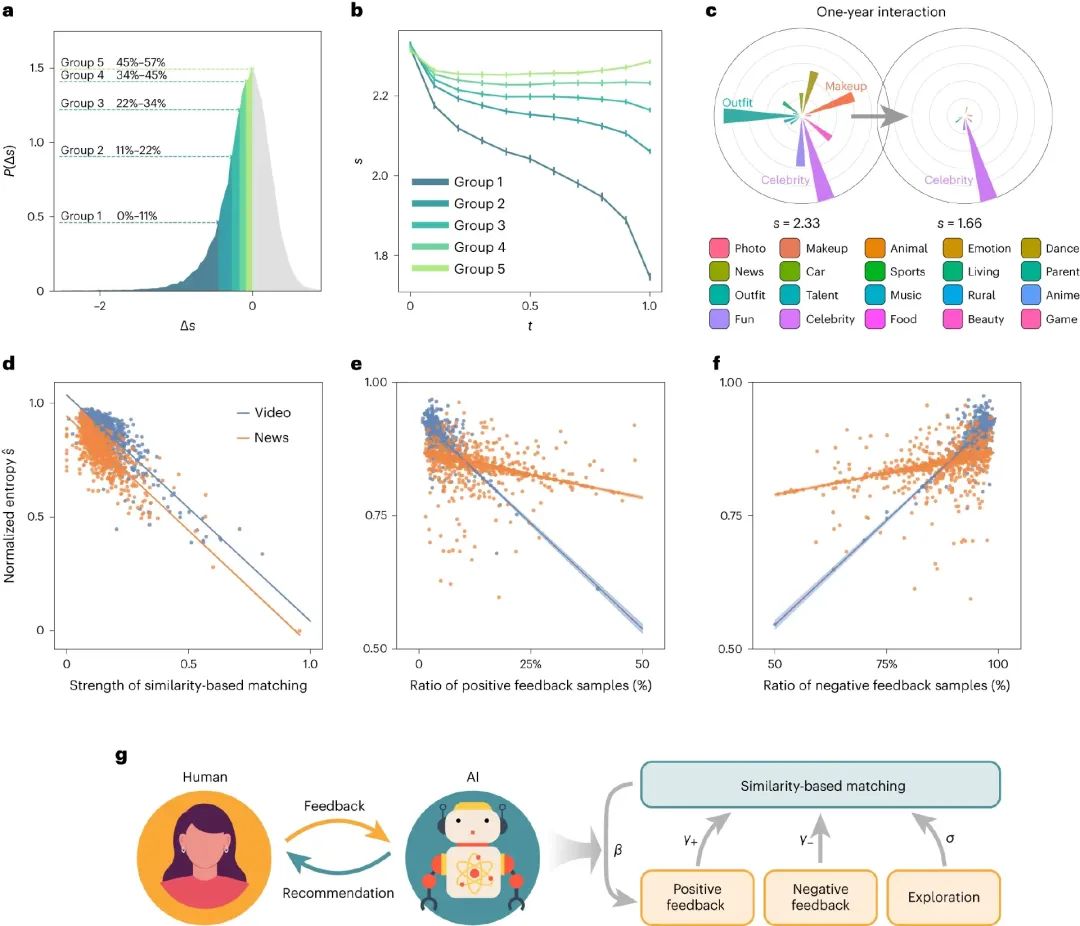
圖1. 對信息繭房的實證研究和自適應信息動力學模型。(a)Δs 展示了超過57%的活躍用戶接受到的推薦結果越來越同質化。根據 Δs,這些用戶被均勻地分為五組。(b)隨時間變化的信息熵 s,線條代表不同 Δs 的用戶組。隨著互動的增加,總體用戶中的11%(第1組)的熵從2.32下降到1.75(下降了24.8%)。(c)第1組中隨機選擇的一個用戶示例,該用戶被AI驅動的推薦算法強烈地限制在同質化的信息中。(d-f) 歸一化信息熵與基于相似性的匹配強度(d)、正反饋樣本比例(e)和負反饋樣本比例(f)之間的關系。(g)自適應信息動力學模型的概覽,其中人類和AI驅動的推薦算法相互互動,形成一個反饋循環。AI基于估計的相似性(β)匹配用戶和項目,用戶提供反饋,AI從用戶的正反饋(γ+)和負反饋(γ?)中學習,以及隨機的自我探索(σ),然后進行進一步的推薦。
2. 自適應信息動力學模型
為了實證地量化用戶可訪問的信息多樣性,研究者使用了信息熵(information entropy)的概念。與隨機熱力學理論類似,人和推薦算法的整體系統最初是遠離平衡的。在基于相似性匹配生成(推薦與用戶過去喜歡主題信息)的有效力場作用下,信息主題逐漸從多樣化狀態演變為信息繭房狀態,這一相變的特點是信息熵下降。
通過對一年內的熵變化進行測量,研究發現超過57%的活躍用戶的信息熵有所下降(圖1a),這意味著他們接觸到的信息變得越來越單一。特別是,有11%的用戶在使用平臺的初期就經歷了信息多樣性的急劇下降,一年后他們的信息熵下降了24.8%(圖1b)。更進一步,研究者隨機選擇了一個信息多樣性下降最多的用戶進行觀察。令人震驚的是,這名用戶在開始時可以接觸到各種各樣的話題,但在與平臺互動一年后,他幾乎只被推薦了一個話題的內容(圖1c)。
進一步的實證觀察發現,信息熵與相似性匹配強度呈負相關,即推薦系統越推薦用戶過去喜歡的主題,信息繭房越可能出現(圖1d,負相關),并且如果表示出積極的反饋,會加劇這種信息繭房(圖1e,負相關),而負面的反饋則會緩解信息熵下降的趨勢(圖1f, 正相關)。
基于這些,作者提出了一個用于復雜的人工智能交互系統的自適應動力學建模框架,以解釋信息繭房的出現。與包含數十億參數的基于深度學習的模型不同,這個提議的模型只依賴于四個參數。這些參數既來源于實證觀察,也來源于當前推薦算法的工作原理。該模型在建模框架中整合了基于相似性的匹配、用戶反饋和人類探索行為(如圖1g所示)。
模型的基于相似性的匹配 (β) 參數描述了用戶的喜好與推薦內容之間的相似度。當β值較大時,與用戶相似的內容更有可能被推薦。用戶對推薦內容的反饋分為正反饋和負反饋,分別由參數γ+和γ?表示。正反饋意味著用戶喜歡某個推薦,而負反饋則表示不喜歡。主動探索 (σ) : 用戶不僅僅依賴于推薦系統,他們還會主動地通過其他途徑(如搜索引擎)探索內容。σ 參數捕獲了這種隨機自我探索的程度。
3. 人類與算法自適應導致繭房的涌現
模型顯示,當推薦系統過度依賴于用戶與內容之間的相似度(即β值增加)時,用戶更容易陷入所謂的“信息繭房”(圖2a)。簡而言之,這意味著系統會過度推薦與用戶過去喜好相似的內容,導致信息的多樣性減少。
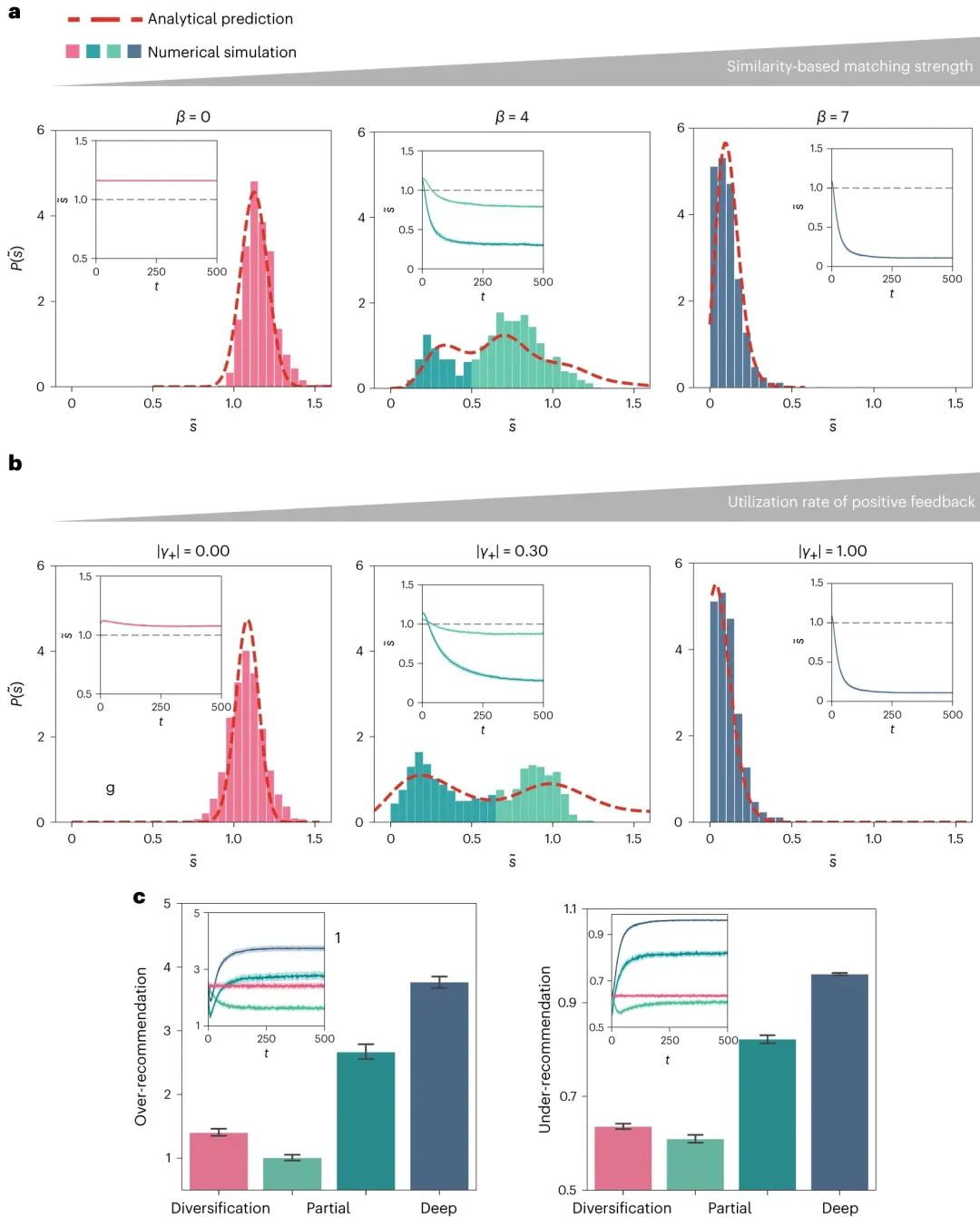
圖2. β 和 ∣γ+∣ 參數對信息繭房的影響。(a)隨著β值的變化,相對信息熵 P 的分布也發生了變化。這意味著,當推薦系統更強烈地依賴用戶與內容之間的相似度時,用戶接觸到的信息多樣性會減少。(b)正反饋強度 ∣γ+∣ 的變化也影響了相對信息熵的分布。這進一步證實了,當系統過度依賴用戶的正反饋時,信息繭房的現象更為明顯。(c)描述了在不同狀態下的過度推薦和欠推薦的程度。
此外,正反饋的過度使用也被發現是導致信息繭房的另一個關鍵因素(圖2b)。當用戶頻繁地給出正反饋,推薦算法可能會過度依賴這些反饋,從而過度推薦某些話題,而忽視了其他可能對用戶有價值的話題。
但是,有希望的是,研究還發現,負反饋的有效利用和用戶的隨機自我探索行為,都可以幫助他們擺脫信息繭房的束縛(圖3a-b)。具體來說,當用戶給出負反饋,或者主動探索新的內容,推薦算法可以更全面、準確地捕捉到用戶的真實喜好,從而提供更多樣化的推薦。
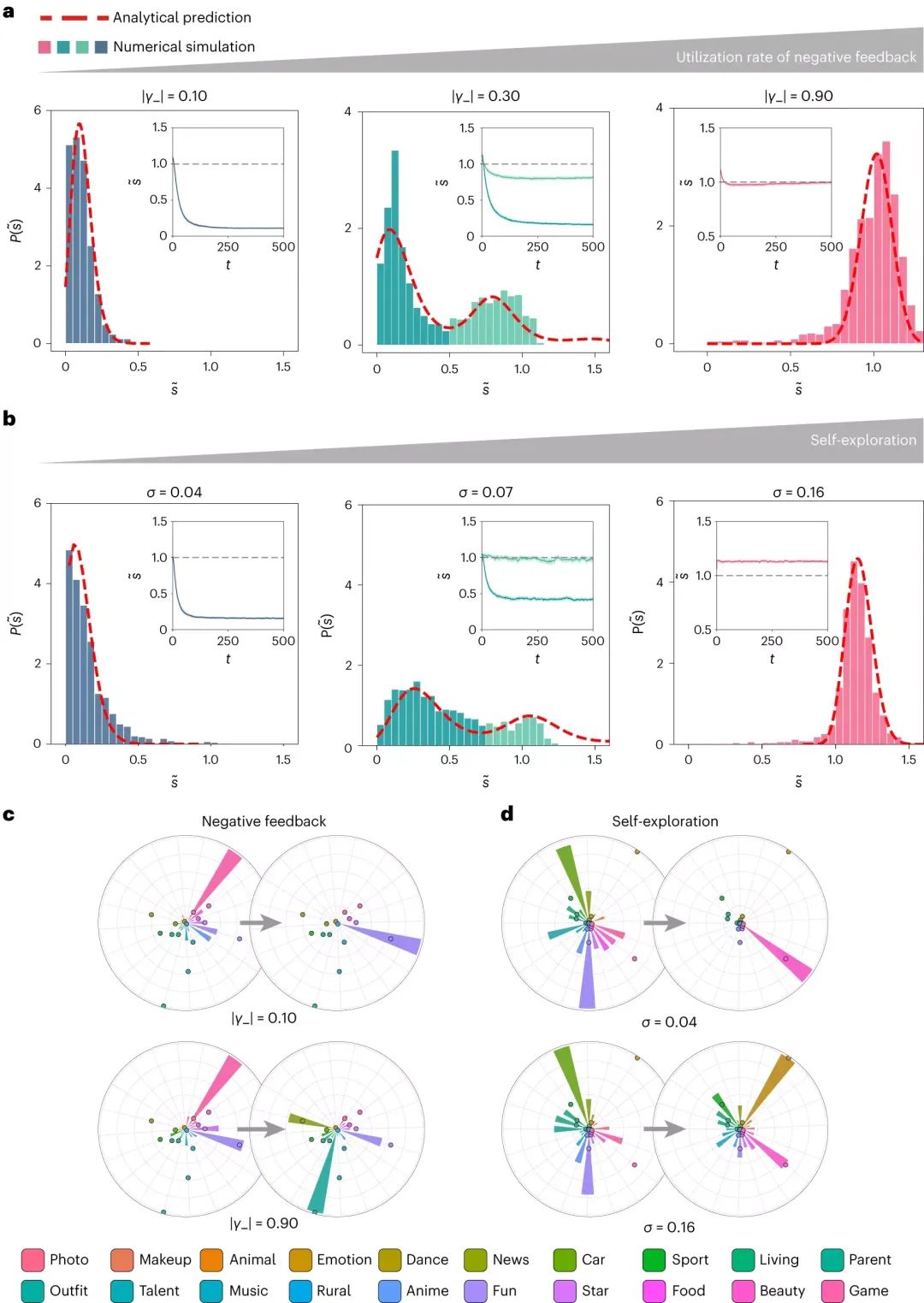
圖3. ∣γ?∣ 和 σ 參數對信息繭房的影響。(a)這部分展示了隨著∣γ?∣(負反饋的使用強度)的變化,相對信息熵的分布。這意味著,當算法更多地依賴用戶的負反饋時,用戶接觸到的信息多樣性如何受到影響。(b)這部分展示了隨著σ(用戶的自主探索行為)的增加,相對信息熵的分布。這意味著,當用戶更多地進行自主探索時,他們接觸到的信息多樣性如何受到影響。(c-d)這兩部分對比了在不同的γ?和σ值下,隨機選取的用戶的初始和可訪問的話題分布。
4. 跳出AI的“繭”:如何避免信息繭房困境
最后,文章的圖4為我們揭示了一個清晰的信息繭房狀態相變圖。這些三維狀態圖展示了在不同的參數組合下,如相似性匹配、正反饋和負反饋,以及自我探索,系統可能會經歷不同的信息繭房狀態,能夠據此預測三種狀態之間的臨界轉變:多樣化、部分信息繭房和深度信息繭房。
值得注意的是,這些圖表揭示了一個關鍵發現:即使相似性匹配的強度很高,只要適當地增加負反饋和鼓勵用戶的自我探索,系統就可以從信息繭房狀態轉移到多樣化狀態。這意味著,通過調整這些關鍵參數,我們可以有效地避免或至少減輕信息繭房的效應。具體來說,我們可以通過更多地關注用戶的負反饋和鼓勵他們進行自我探索,來打破這個“繭”。
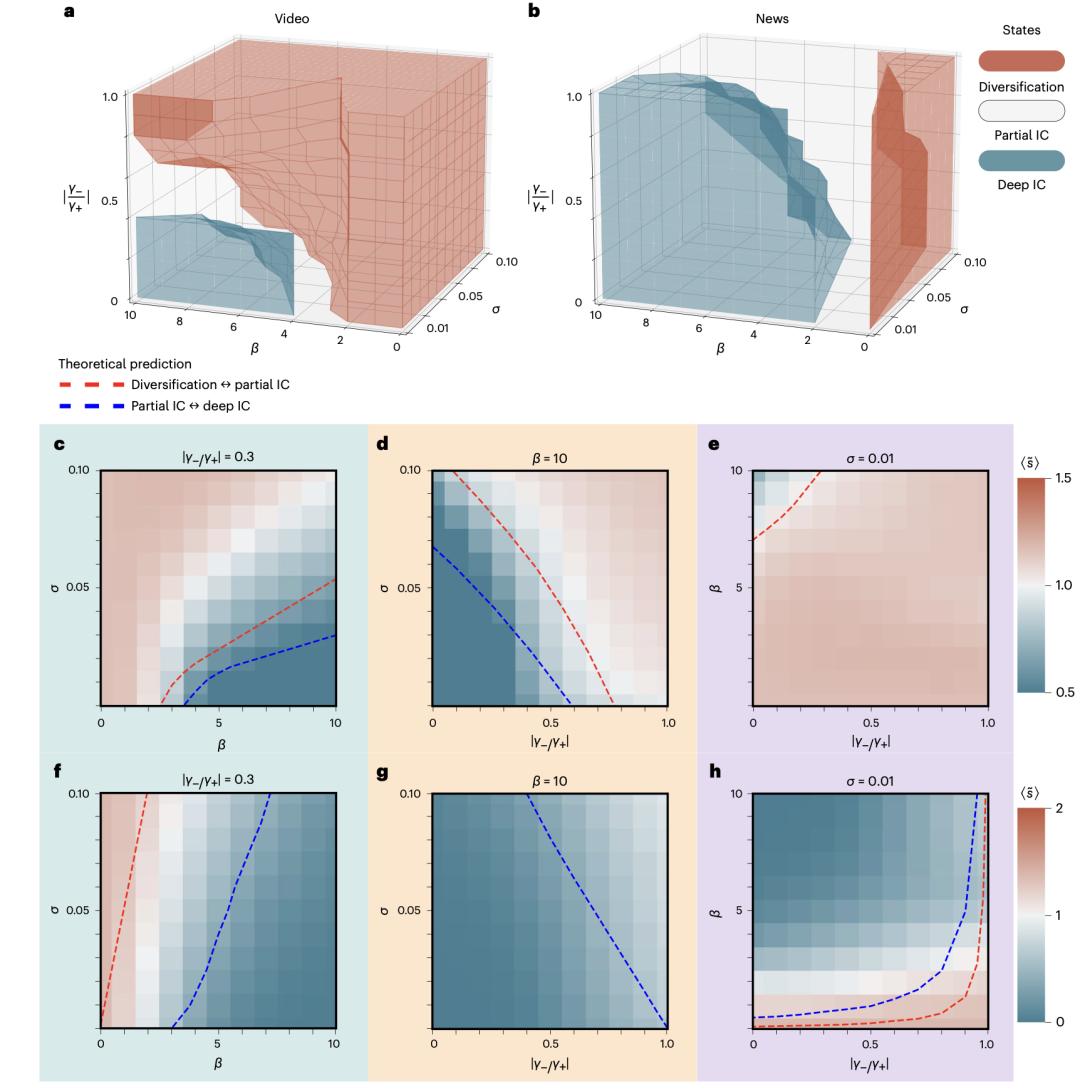
圖4. 不同狀態之間的相變。(a-b)由視頻數據集(a)和新聞數據集(b)初始化的模擬中的三維狀態圖。(c-h)由視頻數據集(c-e)和新聞數據集(f-h)初始化的三維模擬圖的橫截面。
人與AI之間的交互構建了一個復雜的系統,涉及多個實體和反饋機制。這項研究的核心發現為我們跳出信息繭房提供了策略,我們可以采取兩種實際方法來減輕現實世界的信息困境:(1) 有效地利用負反饋,通過識別用戶的不喜歡來提供關于用戶偏好的新視角;(2) 促進自我探索,通過賦予用戶對算法更大的自主權來多樣化可用的信息。
總的來說,這項研究不僅為基于AI的推薦算法提供了實際的方向,還為我們提供了一種理解由于復雜的人工智能交互系統中的自適應動力學而產生的主要社會問題的理論方法。
原標題:《如何跳出推薦算法的“信息繭房”?Nature子刊闡釋人與AI自適應動力學推動信息繭房涌現》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

