- +1
上海AI實(shí)驗(yàn)室發(fā)布“書(shū)生·浦語(yǔ)”大模型:在高考等評(píng)測(cè)中表現(xiàn)優(yōu)秀
·“書(shū)生·浦語(yǔ)”聯(lián)合團(tuán)隊(duì)選取了20余項(xiàng)評(píng)測(cè)對(duì)其進(jìn)行檢驗(yàn),其中包含全球最具影響力的四個(gè)綜合性考試評(píng)測(cè)集,對(duì)“書(shū)生·浦語(yǔ)”、清華大學(xué)的GLM-130B、Meta的LLaMA-65B、OpenAI的ChatGPT和GPT-4進(jìn)行了全面測(cè)試。
6月7日,上海人工智能實(shí)驗(yàn)室(上海AI實(shí)驗(yàn)室)、商湯科技聯(lián)合香港中文大學(xué)、復(fù)旦大學(xué)及上海交通大學(xué)發(fā)布千億級(jí)參數(shù)大語(yǔ)言模型“書(shū)生·浦語(yǔ)”(InternLM),具有1040億參數(shù),在多項(xiàng)中文考試中取得超越ChatGPT的成績(jī),在數(shù)學(xué)考試中成績(jī)明顯領(lǐng)先于谷歌、Meta的大模型。
“書(shū)生·浦語(yǔ)”聯(lián)合團(tuán)隊(duì)選取了20余項(xiàng)評(píng)測(cè)對(duì)其進(jìn)行檢驗(yàn),其中包含全球最具影響力的四個(gè)綜合性考試評(píng)測(cè)集:由伯克利加州大學(xué)等高校構(gòu)建的多任務(wù)考試評(píng)測(cè)集MMLU;微軟研究院推出的學(xué)科考試評(píng)測(cè)集AGIEval(含中國(guó)高考、司法考試及美國(guó)SAT、LSAT、GRE 和 GMAT等),AGIEval的19個(gè)評(píng)測(cè)大項(xiàng)中有9個(gè)大項(xiàng)是中國(guó)高考,通常也列為一個(gè)重要的評(píng)測(cè)子集AGIEval(GK);由上海交通大學(xué)、清華大學(xué)和愛(ài)丁堡大學(xué)合作構(gòu)建的面向中文語(yǔ)言模型的綜合性考試評(píng)測(cè)集C-Eval;以及由復(fù)旦大學(xué)研究團(tuán)隊(duì)構(gòu)建的高考題目評(píng)測(cè)集Gaokao。
實(shí)驗(yàn)室聯(lián)合團(tuán)隊(duì)對(duì)“書(shū)生·浦語(yǔ)”、清華大學(xué)的GLM-130B、Meta的LLaMA-65B、OpenAI的ChatGPT和GPT-4進(jìn)行了全面測(cè)試,針對(duì)上述四個(gè)評(píng)測(cè)集的成績(jī)對(duì)比如下(滿分100分)。
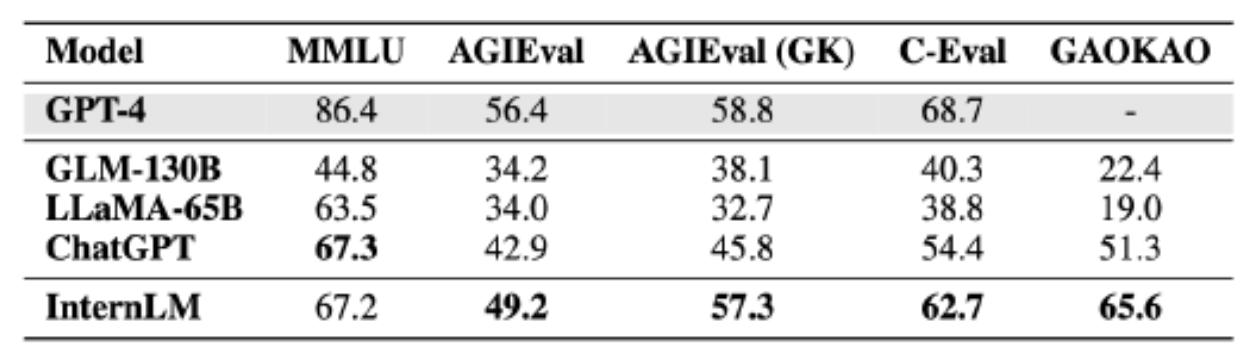
“書(shū)生·浦語(yǔ)”、GLM-130B、LLaMA-65B、ChatGPT和GPT-4的測(cè)試結(jié)果。
據(jù)上海人工智能實(shí)驗(yàn)室消息,“書(shū)生·浦語(yǔ)”全面評(píng)測(cè)結(jié)果顯示,其在知識(shí)掌握、閱讀理解、數(shù)學(xué)推理、多語(yǔ)翻譯等多個(gè)測(cè)試任務(wù)上表現(xiàn)優(yōu)秀,在綜合性考試中表現(xiàn)突出,在多項(xiàng)中文考試中取得超越ChatGPT的成績(jī),其中就包括中國(guó)高考各科目的數(shù)據(jù)集(GaoKao),在以美國(guó)考試為主的MMLU上和ChatGPT基本持平。
為了避免“偏科”,研究人員通過(guò)多個(gè)學(xué)術(shù)評(píng)測(cè)集,對(duì)“書(shū)生·浦語(yǔ)”等語(yǔ)言模型的分項(xiàng)能力進(jìn)行了評(píng)測(cè)對(duì)比。結(jié)果顯示,“書(shū)生·浦語(yǔ)”不僅在中英文的閱讀理解方面表現(xiàn)突出,并且在數(shù)學(xué)推理、編程能力等評(píng)測(cè)中也取得了較好的成績(jī)。

分項(xiàng)能力的評(píng)測(cè)對(duì)比。
在英語(yǔ)閱讀理解方面,“書(shū)生·浦語(yǔ)”明顯領(lǐng)先于LLaMA-65B和ChatGPT,“書(shū)生·浦語(yǔ)”在初中和高中英語(yǔ)閱讀理解中得分為92.7和88.9,?ChatGPT得分為85.6和81.2,LLaMA-65B則更低。在數(shù)學(xué)推理方面,“書(shū)生·浦語(yǔ)”在GSM8K和MATH這兩項(xiàng)被廣泛用于評(píng)測(cè)的數(shù)學(xué)考試中,分別取得62.9和14.9的得分,明顯領(lǐng)先于谷歌的PaLM-540B(得分為56.5和8.8)與LLaMA-65B(得分為50.9和10.9)。
但在測(cè)評(píng)中也可以看到,大語(yǔ)言模型仍然存在能力局限。“書(shū)生·浦語(yǔ)” 受限于2K的語(yǔ)境窗口長(zhǎng)度(GPT-4的語(yǔ)境窗口長(zhǎng)度為32K),在長(zhǎng)文理解、復(fù)雜推理、撰寫(xiě)代碼以及數(shù)理邏輯演繹等方面還存在明顯局限。另外,在實(shí)際對(duì)話中,大語(yǔ)言模型還普遍存在幻覺(jué)、概念混淆等問(wèn)題。這些局限使得大語(yǔ)言模型在開(kāi)放場(chǎng)景中的使用還有很長(zhǎng)的路要走。




- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

