- +1
未來城市思辨|大型語言模型,規模就是一切嗎?
語言模型的產生
近日舉辦的神經信息處理系統大會(NeurIPS 2022)上,來自DeepMind的研究人員發表了一個人工智能模型,用以從持不同觀點的參與者所給出的表述中,形成一個較有可能達成的共識。研究者聲稱,通過這一模型生成出的文本表述,較人工所作的總結更受參與者青睞。
相比之下,更多的將多樣自然文本建模成計算機能理解并可計算的方案——一般被稱為語言模型——已經進入到人們的日常生活中。從手機上各種“智能助手”看似簡單的口令,到客服機器人,乃至于各種“AI繪畫”中輸入的提示詞,都需要經過復雜程度不同的語言模型處理。

2022年10月,上海。澎湃新聞記者 周平浪 圖
對語言模型的追尋,可上溯到上世紀中葉。1947年3月4日,數學家沃倫·韋弗(Warren Weaver)寫信給維納(Nobert Wiener):“我想知道,設計一臺可以翻譯的計算機是否是不可想象的。即使它只能翻譯科學材料(顯著降低語義困難),即使它會產生不優雅的結果,但對我來說,只要尚可理解,就值得嘗試。”“翻譯問題是否可以想象為密碼學中的一個問題?……你想過這個問題嗎?作為一名語言學家和計算機專家,你認為這值得思考嗎?”
維納在同年4月30日作出的答復中并不看好機械翻譯。在他看來,談論機械翻譯為時尚早——不僅“不同語言中的詞匯界限太模糊,情感和國際內涵太廣泛”,而且即便是“基本英語”(Basic)這樣從日常英語中有所篩選、人為設計的“機械化語言”,也很難擺脫復雜的語義負擔,從而使之能夠機械性地轉換為另一種語言。
不過,韋弗似乎并沒有來得及等到維納遲來的回復。在寄出致維納的信件后不過兩天,他就從英國的計算機技術先驅者布斯(Andrew Booth)那里了解到美國計算機發展的情況,認定將計算機用于非數字運算的應用,將更容易獲得資金支持,并將機器翻譯列為一個可選方向。至于維納所提到的語義負擔,他認為,可以將相鄰單詞視作一個詞來加以解決。
韋弗的提議在香農(Claude Shannon)撰寫的《通信的數學理論》(A Mathematical Theory of Communication)一文中被推廣為考察多個相鄰詞的N元組(N-gram),在此基礎上,香農還討論了將馬爾科夫鏈(Markov Chain)這種嚴格的概率統計方法用于語言文本分析的可能性。可以說,這是最早在數學意義上提出的自然語言模型,也是一個基于概率和統計的語言模型。
但是,語言學家喬姆斯基(Noam Chomsky)并不認可這一路徑。他指出,有限狀態(如N元組)不足以描述自然語言,而應代之以一種生成語法,即面向有限長字符構成的有限詞匯,規定的一組能夠生成所有可能句子的規則。喬姆斯基的思想,代表了這一時期以規則和實例為導向,對語言現象進行計算機處理并試圖從中研發出機器翻譯和聊天機器人等應用的進路。
時至今日,喬姆斯基和他所代表的這一進路,雖然仍具有學術意義和歷史價值,但在人工智能技術中已不再有影響力。取而代之的是基于人工神經網絡的語言模型:2001年,約書亞·本吉奧(Yoshua Bengio)等人撰寫了《一種神經概率語言模型》(“A neural probabilistic language model”),開啟了語言模型的新篇章。他們的工作可以被視為N-grams的某種延續和擴展:用可認為連續的方式表征單詞,并用結構多變的神經網絡來代替簡單的馬爾科夫鏈形式。
大型語言模型的繁榮與隱憂
隨著研究者發現更為復雜的建模能夠更為貼近人們的語言日常,今天人工智能領域熱議的“語言模型”,指的已不再是這些較為原始的模型,而是2018年以來陸續發展的一系列參數規模上億的大型語言模型(large language model,LLM)。在短短4年時間里,大型語言模型的參數數量保持著指數增長勢頭。據預測,OpenAI開發中的最新大型語言模型GPT-4將包含約100萬億的參數,與人腦的突觸在同一數量級。由此,出現了一個新的人工智能口號:“規模就是一切”。
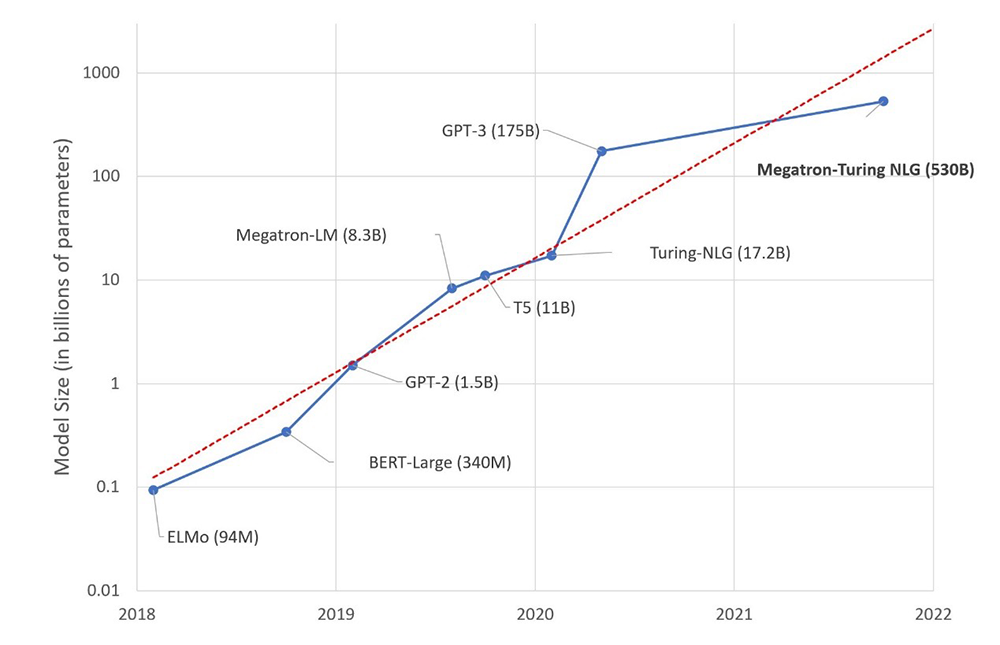
圖片來源:https://huggingface.co/blog/large-language-models
更大的模型帶來了更高的訓練成本。這既包括智力支出和經濟成本,也有不可忽視的環境影響。馬薩諸塞大學阿姆赫斯特分校的一項研究指出,僅是訓練參數數量不到最新模型1%的BERT模型,就會造成652千克的碳排放,可與跨越美國東西海岸的一次航班所造成的碳排放相比擬。
與此同時,越來越大的模型所提升的效用正在縮小。人們發現,模型參數規模增長10倍,得到的性能提升往往不到10個百分點。相比之下,倒是那些同等(乃至更小)參數規模的新模型,會帶來真正質的提升。還有一些研究者嘗試把大模型拆分成更多小模型并集之所長,但由于其模型參數不會全部加入計算,“這是否會是參數量狂熱之下的一種數字泡沫”的質疑也隨之而來。
而且,隨著大型語言模型的廣泛應用,一些負面的社會效應也開始顯現。據預測,到2023年,約有5%的大學生會使用大型語言模型生成的文本來代替本應由他們自己撰寫的作業,而與之對抗的檢測手段則很難真正發揮作用。
就在上月,Meta公司發布了一個名為Galactica的大型語言模型,宣稱它“可以總結學術論文,解決數學問題,生成維基百科文章,編寫科學代碼,標記分子和蛋白質,以及更多功能。”但上線僅3天,該模型就在巨大爭議中撤回:它雖然能生成一些貌似通順的學術文本,但文本中的信息是完全錯誤的——貌似合理的化學方程,描述的是實際上并不會發生的化學反應;格式合規的引文參考的是子虛烏有的文獻;甚而種族主義、性別歧視的觀點,也能通過模型生成的文本而被包裝成“科學研究”。批評者質疑,這樣的模型會使學術造假變得更為隱蔽,也將使科學謠言的散播變得更加便利。

2022年10月,上海人民廣場。澎湃新聞記者 周平浪 圖
一般的觀點認為,盡管人工智能系統能在諸多特定任務中顯現出看似智能的行為,但它們并不像人那樣理解它們所處理的數據。譬如,Character.ai、ChatGPT這樣的模型應用雖然已能流暢地與人進行“對話”,而且相當程度上顧及到上下文,然而,人工智能系統中無法預測的錯誤、對于一般情況推廣能力的欠缺等都被視為它們無法“理解”的證據。這樣的大型語言模型并未真正“理解”語言所描述的現實世界。
大型語言模型的局限性逐漸暴露在公眾面前,單純追求模型尺度的增加,不僅面臨經濟、環保等因素的限制,而且也遭受技術群體內部的質疑。這是一種“為科學而科學”的精神,還是只是一種對單一尺度的盲信?《麻省理工技術評論》作者哈文(Will Douglas Heaven)寫道:“Meta的失誤和它的傲慢再次表明,大科技公司對大型語言模型的嚴重局限性視而不見。”
“鏡像假說”與大型語言模型的社會內涵
但是,知名的復雜性科學研究機構圣塔菲研究所(Santa Fe Institute)研究人員在2022年10月發表的一篇預印本論文中指出,這項關于人工智能的基本共識正被打破。
一項面向自然語言處理領域活躍研究者的調查顯示,51%的受訪者相信,提供充分的數據和計算資源,僅憑文本訓練的語言模型能夠在某種非平凡的意義上理解自然語言。隨著模型越來越能輸出類似人類寫作的文本,文本的真誠性成為一個日益嚴峻的問題。對于大型語言模型如何工作,科學家實際和外行人一樣不知情。這些神經網絡的內在工作模式,很大程度上仍是一個謎團。神經科學家特倫斯·塞諾夫斯基(Terrence Sejnowski)如此描述大型語言模型的出現:“就好像突然達到了一個門檻,出現了一個外星人,卻可以用一種特別接近人類的方式與我們交流。只有一件事是清楚的——它們不是人類......它們行為的某些方面似乎是智能的,但如果不是人類的智能,它們的智能的本質是什么?”
塞諾夫斯基并未為“外星人”般的“智能”所阻嚇。他另辟蹊徑,提出“反向圖靈測試”的觀點:語言模型所給出的“看似體現智能的東西”,成為了“反映面試者智能的鏡子”,而研究人與機器的“對話”,我們可能更多了解到的是人類用戶的智能和信念。畢竟,相較于難以確定的“語言模型的智能”,人類用戶在與這樣的計算機系統的交互中所表達的內容是可以確定的。他發現,人們輸入給語言模型的提示詞或問題,越是精心設計,模型給出的結果就越是反過來讓人信服它的“智能”。這就好像人們在與高手對弈時也能促使自己提升棋藝一般,從人工智能的“回應”中可以看出人們深層意愿的鏡像。這被他稱為“鏡像假說”。
賽諾夫斯基援引人類學家羅賓·鄧巴在20世紀80年代末提出的觀點,認為智能并不是從在一個荒涼的世界中生存的智力需求中產生的,畢竟很多其他動物依靠它們的小腦袋也能存活下去。相反,智能的“大爆炸”開始于同其他人的合作與競爭。從這個角度看,所謂的“智能”并不是單個行動體(agent)具有的某種“屬性”,而是始終在與他者的交互中呈現出的一種集體狀態,即(雖然只是假設性地)“進入”別人的大腦,“了解”他們的感知、思考和感受,與他人產生共鳴,從而預測他們的行為、影響他們的行動。將同樣的能力應用于自身,可以使我們進行反省,使我們的行為合理化,并對未來進行規劃。在這種觀點中,意識不是從天而降的神秘幽靈,而只是我們用來描述這種“設身處地”與“躬身自省”的語匯。
“鏡像假說”的提出,為大型語言模型重新賦予了社會性的內涵。與語言模型的交互并不是一種真正的知識生產(如Meta公司宣稱Galactica要做到的那樣),而是通過一種機制來反映人們自身的訴求和意圖,為理解這些抽象的“概念”提供了具體的“事實”。從這個視角來看,人工智能的發展,所需要的不僅是具體計算技術的發展和對智能模型的“唯象”考察,而是仍舊需要某種理論的提煉乃至想象,不斷吸收和接納對人自身更深層的理解。這些,無疑都超出了“規模就是一切”所宣稱的范疇。
(作者朱恬驊系上海社會科學院文學研究所助理研究員;陳涵洋系獨立開發者)



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

