- +1
基于無(wú)監(jiān)督預(yù)訓(xùn)練的語(yǔ)音識(shí)別技術(shù)落地實(shí)踐,火山語(yǔ)音表示有話(huà)要說(shuō)
一直以來(lái),火山語(yǔ)音團(tuán)隊(duì)都為時(shí)下風(fēng)靡的視頻平臺(tái)提供基于語(yǔ)音識(shí)別技術(shù)的智能視頻字幕解決方案,簡(jiǎn)單來(lái)說(shuō)就是可以自動(dòng)將視頻中的語(yǔ)音和歌詞轉(zhuǎn)化成文字,來(lái)輔助視頻創(chuàng)作的功能。但伴隨平臺(tái)用戶(hù)的快速增長(zhǎng)以及對(duì)語(yǔ)言種類(lèi)更加豐富多樣的要求,傳統(tǒng)采用有監(jiān)督學(xué)習(xí)技術(shù)來(lái)解決的辦法日漸遭遇瓶頸,這讓團(tuán)隊(duì)著實(shí)犯了難。
眾所周知,傳統(tǒng)的有監(jiān)督學(xué)習(xí)會(huì)對(duì)人工標(biāo)注的有監(jiān)督數(shù)據(jù)產(chǎn)生嚴(yán)重依賴(lài),尤其在大語(yǔ)種的持續(xù)優(yōu)化以及小語(yǔ)種的冷啟動(dòng)方面。以中文普通話(huà)和英語(yǔ)這樣的大語(yǔ)種為例,盡管視頻平臺(tái)提供了充足的業(yè)務(wù)場(chǎng)景語(yǔ)音數(shù)據(jù),但有監(jiān)督數(shù)據(jù)達(dá)到一定規(guī)模之后,繼續(xù)標(biāo)注的ROI將非常低,必然需要技術(shù)人員考慮如何有效利用百萬(wàn)小時(shí)級(jí)別的無(wú)標(biāo)注數(shù)據(jù),來(lái)進(jìn)一步改善大語(yǔ)種語(yǔ)音識(shí)別的效果。
相對(duì)小眾的語(yǔ)言或者方言,由于資源、人力等原因,數(shù)據(jù)的標(biāo)注成本高昂。在標(biāo)注數(shù)據(jù)極少的情況下(10小時(shí)量級(jí)),有監(jiān)督訓(xùn)練的效果非常差,甚至可能無(wú)法正常收斂;而采購(gòu)的數(shù)據(jù)往往和目標(biāo)場(chǎng)景不匹配,無(wú)法滿(mǎn)足業(yè)務(wù)的需要。
為此火山語(yǔ)音團(tuán)隊(duì)迫切需要研究如何以盡可能低廉的標(biāo)注成本充分利用大量的無(wú)標(biāo)注數(shù)據(jù),提升少量標(biāo)注數(shù)據(jù)下的識(shí)別效果并落地到實(shí)際業(yè)務(wù)中,所以無(wú)監(jiān)督預(yù)訓(xùn)練技術(shù)成為視頻平臺(tái)ASR(Automatic Speech Recognition / 自動(dòng)語(yǔ)音識(shí)別)能力向小語(yǔ)種推廣的關(guān)鍵。
盡管近年來(lái)學(xué)術(shù)界在語(yǔ)音無(wú)監(jiān)督預(yù)訓(xùn)練領(lǐng)域取得了許多重大進(jìn)展,包括Wav2vec2.0 [1]、HuBERT [2]等,但在工業(yè)界卻鮮有落地案例可以參考借鑒。整體來(lái)看,火山語(yǔ)音團(tuán)隊(duì)認(rèn)為,以下三方面主要原因,阻礙了無(wú)監(jiān)督預(yù)訓(xùn)練技術(shù)的落地:
模型參數(shù)量大、推理開(kāi)銷(xiāo)大。大量無(wú)標(biāo)注數(shù)據(jù)需要用較大的模型做無(wú)監(jiān)督預(yù)訓(xùn)練,才能得到高質(zhì)量的語(yǔ)音表征,但這樣的模型如果直接部署到線上,會(huì)帶來(lái)高昂的推理成本。
無(wú)監(jiān)督預(yù)訓(xùn)練只關(guān)注語(yǔ)音表征的學(xué)習(xí),需要結(jié)合大量純文本訓(xùn)練的語(yǔ)言模型聯(lián)合解碼才能達(dá)到理想效果,和端到端ASR推理引擎不兼容。
無(wú)監(jiān)督預(yù)訓(xùn)練開(kāi)銷(xiāo)大、周期長(zhǎng)且不穩(wěn)定。以Wav2vec2.0為例,300M參數(shù)量的模型用64張V100 GPU預(yù)訓(xùn)練60萬(wàn)步,耗時(shí)長(zhǎng)達(dá)半個(gè)月;此外由于數(shù)據(jù)分布的差異,在業(yè)務(wù)數(shù)據(jù)上訓(xùn)練容易發(fā)散。
對(duì)此火山語(yǔ)音團(tuán)隊(duì)在基于無(wú)監(jiān)督預(yù)訓(xùn)練的語(yǔ)音識(shí)別技術(shù)落地過(guò)程中,針對(duì)以上三大痛點(diǎn)進(jìn)行了算法改進(jìn)和工程優(yōu)化,形成一套完整易推廣的落地方案。本文將針對(duì)方案,從落地流程、算法優(yōu)化以及工程優(yōu)化等環(huán)節(jié)展開(kāi)詳盡介紹。
落地流程
下圖是基于無(wú)監(jiān)督預(yù)訓(xùn)練的低資源語(yǔ)種ASR的落地流程,大致可以劃分為數(shù)據(jù)收集、種子模型訓(xùn)練和模型遷移三個(gè)階段。

圖1 基于無(wú)監(jiān)督預(yù)訓(xùn)練的ASR落地流程
具體來(lái)說(shuō),第一階段的數(shù)據(jù)收集,可以通過(guò)語(yǔ)種分流、采購(gòu)等手段收集目標(biāo)語(yǔ)言的無(wú)標(biāo)注語(yǔ)音、標(biāo)注語(yǔ)音和純文本數(shù)據(jù)。
第二階段的種子模型訓(xùn)練,也就是經(jīng)典的“無(wú)監(jiān)督預(yù)訓(xùn)練+有監(jiān)督微調(diào)”過(guò)程。 這一階段將得到一個(gè)聲學(xué)模型,通常基于連接時(shí)序分類(lèi)(Connectionist Temporal Classification, CTC [3])損失函數(shù)微調(diào)。聲學(xué)模型結(jié)合純文本訓(xùn)練的語(yǔ)言模型,構(gòu)成一個(gè)完整的語(yǔ)音識(shí)別系統(tǒng),可以取得不錯(cuò)的識(shí)別效果。之所以稱(chēng)之為種子模型,是因?yàn)檫@個(gè)模型并不適合直接上線到業(yè)務(wù),我們更傾向于使用LAS(Listen, Attend and Spell [4])或RNN-T(Recurrent Neural Network Transducer [5])這類(lèi)端到端模型進(jìn)行線上部署。
歸其原因,主要是LAS/RNN-T具有出色的端到端建模能力,同時(shí)在近年來(lái)已經(jīng)取得了優(yōu)于傳統(tǒng)CTC模型的效果,并在工業(yè)界得到越來(lái)越多的應(yīng)用。火山語(yǔ)音團(tuán)隊(duì)針對(duì)端到端語(yǔ)音識(shí)別模型的推理和部署做了大量?jī)?yōu)化工作,已形成一套相對(duì)成熟的方案,并支持眾多業(yè)務(wù)。在維持效果無(wú)損的前提下,如果可以沿用端到端推理引擎,就能大幅降低引擎的運(yùn)維成本。
基于此團(tuán)隊(duì)設(shè)計(jì)了第三階段,即模型遷移階段。主要借鑒知識(shí)蒸餾的思想,用種子模型對(duì)無(wú)標(biāo)注數(shù)據(jù)打偽標(biāo)簽,然后提供一個(gè)參數(shù)量較小的LAS模型做訓(xùn)練,同步實(shí)現(xiàn)了模型結(jié)構(gòu)的遷移和推理計(jì)算量的壓縮。整個(gè)流程的有效性在粵語(yǔ)ASR上得到驗(yàn)證,具體實(shí)驗(yàn)結(jié)果如下表所示:
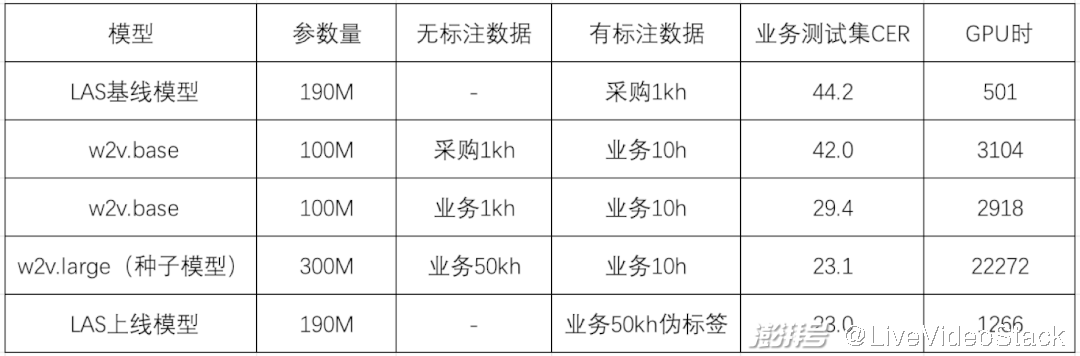
首先,團(tuán)隊(duì)采購(gòu)了1kh成品數(shù)據(jù)用于實(shí)驗(yàn)對(duì)比,直接訓(xùn)練LAS模型性能不佳,字錯(cuò)率(Character Error Rate, CER)高達(dá)44.2%。經(jīng)過(guò)分析,火山語(yǔ)音認(rèn)為主要原因是采購(gòu)數(shù)據(jù)(對(duì)話(huà))和業(yè)務(wù)測(cè)試集(視頻)領(lǐng)域不匹配,在wav2vec2.0上的初步實(shí)驗(yàn)也發(fā)現(xiàn)了類(lèi)似的現(xiàn)象。
相比用采購(gòu)數(shù)據(jù)做預(yù)訓(xùn)練,采用和目標(biāo)領(lǐng)域一致的數(shù)據(jù)做預(yù)訓(xùn)練,在業(yè)務(wù)測(cè)試集上的CER可以從42.0%下降到29.4%,于是團(tuán)隊(duì)將業(yè)務(wù)場(chǎng)景的無(wú)標(biāo)注數(shù)據(jù)積累到50kh,模型參數(shù)量從100M增加到300M,CER進(jìn)一步下降到23.1%。
最后團(tuán)隊(duì)驗(yàn)證了模型遷移的效果,結(jié)合粵語(yǔ)語(yǔ)言模型對(duì)50kh無(wú)標(biāo)注數(shù)據(jù)解碼得到偽標(biāo)簽,訓(xùn)練LAS模型。可以看到,基于偽標(biāo)簽訓(xùn)練的LAS模型基本可以保持CTC種子模型的識(shí)別效果且模型參數(shù)量減少了三分之一,可以直接基于成熟的端到端推理引擎部署上線。

圖2 模型參數(shù)量和CER對(duì)比
最終在模型結(jié)構(gòu)和參數(shù)量不變的前提下,團(tuán)隊(duì)用50kh無(wú)標(biāo)注業(yè)務(wù)數(shù)據(jù)和10h有標(biāo)注業(yè)務(wù)數(shù)據(jù)取得了23.0%的CER,相對(duì)基線模型下降48%。解決了線上計(jì)算量和兼容性的問(wèn)題之后,聚焦到整個(gè)流程中最為核心的無(wú)監(jiān)督預(yù)訓(xùn)練技術(shù),針對(duì)wav2vec2.0,火山語(yǔ)音團(tuán)隊(duì)分別從算法和工程兩個(gè)維度進(jìn)行了優(yōu)化。
算法優(yōu)化
wav2vec2.0作為Meta AI在2020年提出來(lái)的自監(jiān)督預(yù)訓(xùn)練模型,開(kāi)啟了語(yǔ)音無(wú)監(jiān)督表征學(xué)習(xí)的新篇章。其核心思想在于用量化模塊將輸入特征離散化,并通過(guò)對(duì)比學(xué)習(xí)優(yōu)化,模型主體與BERT類(lèi)似,隨機(jī)mask部分輸入特征。
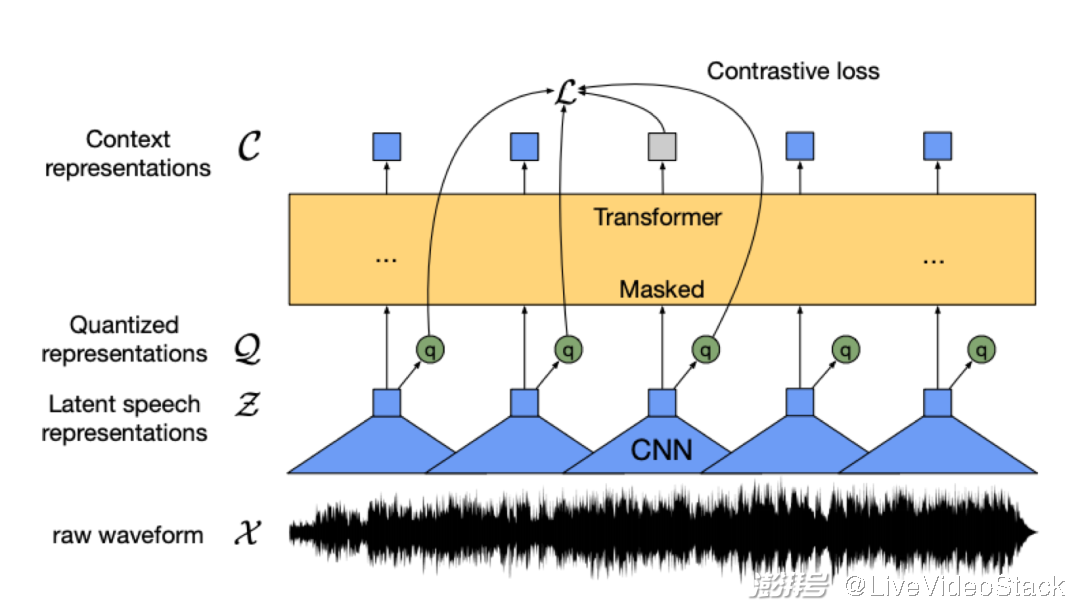
圖3 wav2vec2.0模型結(jié)構(gòu)示意圖(來(lái)源:wav2vec 2.0 Figure 1 [1])
對(duì)此在業(yè)務(wù)數(shù)據(jù)上訓(xùn)練wav2vec 2.0模型遇到了兩個(gè)棘手的問(wèn)題:一個(gè)是訓(xùn)練效率低,300M的大模型64卡需要十幾天才能訓(xùn)完;另一個(gè)是訓(xùn)練不穩(wěn)定,容易發(fā)散。為此團(tuán)隊(duì)提出Efficient wav2vec以緩解上述兩個(gè)問(wèn)題:
對(duì)于訓(xùn)練效率低的問(wèn)題,團(tuán)隊(duì)通過(guò)降低模型的幀率來(lái)加快訓(xùn)練速度,將輸入特征從waveform替換成filterbanks,幀率由原來(lái)的20ms變成40ms。這樣既大幅降低了特征提取卷積的計(jì)算量,同時(shí)也大幅降低了Transformer內(nèi)部編碼的長(zhǎng)度,從而提高訓(xùn)練效率。對(duì)于訓(xùn)練不穩(wěn)定的問(wèn)題,則是通過(guò)分析無(wú)監(jiān)督預(yù)訓(xùn)練的學(xué)習(xí)方式并結(jié)合業(yè)務(wù)數(shù)據(jù)實(shí)際情況綜合判斷解決,對(duì)比學(xué)習(xí)損失可以用下式表達(dá):

對(duì)于每一幀t,Ct表示該幀的編碼器輸出,qt表示該幀的量化輸出。除此之外,還需要采樣若干其它幀作為負(fù)樣本,從而當(dāng)前幀與負(fù)樣本幀的集合就相當(dāng)于是動(dòng)態(tài)構(gòu)造的詞表Qt。
對(duì)比學(xué)習(xí)的優(yōu)化目標(biāo)就是最大化當(dāng)前幀編碼與該幀量化結(jié)果的相似度,同時(shí)最小化當(dāng)前幀編碼與其它幀量化結(jié)果的相似度。不難發(fā)現(xiàn),負(fù)樣本與正樣本的相似度以及負(fù)樣本個(gè)數(shù)這兩點(diǎn)直接決定了對(duì)比學(xué)習(xí)的效果;而在實(shí)際操作中,業(yè)務(wù)數(shù)據(jù)的平均長(zhǎng)度較短,一句話(huà)僅能提供50個(gè)負(fù)樣本,是遠(yuǎn)遠(yuǎn)不夠的;同時(shí)考慮到語(yǔ)音相鄰幀之間的相似度很高,需要保證mask區(qū)域的連續(xù),從而提高表征重構(gòu)的難度。
為了解決上述兩個(gè)問(wèn)題,火山語(yǔ)音對(duì)應(yīng)提出了兩點(diǎn)改進(jìn):
等長(zhǎng)數(shù)據(jù)流:預(yù)訓(xùn)練過(guò)程中將整個(gè)訓(xùn)練集視為由每句話(huà)首尾拼接而成的一段音頻,每個(gè)訓(xùn)練樣本從中截取固定長(zhǎng)度得到,這樣做是為了保證負(fù)樣本數(shù)量足夠多,且上下文編碼網(wǎng)絡(luò)內(nèi)部的長(zhǎng)度在不同幀率下一致,進(jìn)而保證訓(xùn)練的穩(wěn)健性。
自適應(yīng)連續(xù)mask:為緩解數(shù)據(jù)噪音對(duì)訓(xùn)練的影響,選取較小的mask長(zhǎng)度且強(qiáng)制每個(gè)mask區(qū)域連續(xù),并且mask區(qū)域?qū)?yīng)的音頻長(zhǎng)度在不同幀率下相當(dāng)。這樣既減輕了噪音數(shù)據(jù)下對(duì)比學(xué)習(xí)的難度,同時(shí)也做到了適配不同的幀率。
在業(yè)務(wù)數(shù)據(jù)上對(duì)比了wav2vec2.0(w2v)與 Efficient wav2vec (w2v-e)的效果,如下表所示(所有模型均采用64 V100 GPUs訓(xùn)練):

可以看到改進(jìn)過(guò)的Efficient wav2vec相對(duì)原始wav2vec 2.0有穩(wěn)定5%的性能提升,并且訓(xùn)練效率接近翻倍。
工程優(yōu)化
盡管團(tuán)隊(duì)提出的Efficient wav2vec已經(jīng)從算法層面將訓(xùn)練效率提升近兩倍,但由于300M模型通信量大,訓(xùn)練通信依然存在波動(dòng)且多機(jī)擴(kuò)展效率低。對(duì)此火山語(yǔ)音團(tuán)隊(duì)總結(jié)道:“為了提高模型預(yù)訓(xùn)練在同步梯度場(chǎng)景下的通信效率,我們基于BytePS的分布式訓(xùn)練框架,在通信后端完成了Bucket分組通信優(yōu)化技術(shù),數(shù)據(jù)并行效率能取得10%的提升;同時(shí)針對(duì)模型參數(shù)定義順序與梯度更新順序不同造成的等待問(wèn)題,還實(shí)現(xiàn)了自適應(yīng)的參數(shù)重排(Parameter Reorder)策略。”在這些優(yōu)化基礎(chǔ)上,進(jìn)一步結(jié)合梯度累加等技術(shù),300M模型的單卡擴(kuò)展效率由55.42%提升至81.83%,多機(jī)擴(kuò)展效率由60.54%提升至91.13%,原來(lái)需要6.5天訓(xùn)完的模型現(xiàn)在只需要4天就可以訓(xùn)完,耗時(shí)縮短40%。
此外,為了支持未來(lái)探索的大模型大數(shù)據(jù)場(chǎng)景,火山語(yǔ)音工程團(tuán)隊(duì)進(jìn)一步完成了一系列超大規(guī)模模型的原子能力建設(shè)。首先實(shí)現(xiàn)了local OSS技術(shù),在去除優(yōu)化器大部分的冗余內(nèi)存占用的同時(shí),解決了機(jī)間擴(kuò)展效率問(wèn)題;之后在同步梯度通信上支持了bucket lazy init,減少了一倍參數(shù)量的顯存占用,能大幅降低顯存峰值并適配顯存資源緊張的超大模型場(chǎng)景;最后在數(shù)據(jù)并行的基礎(chǔ)上,還支持了模型并行和流水線并行,并在1B和10B模型上完成了驗(yàn)證和定制化支持。這一系列優(yōu)化為大模型大數(shù)據(jù)的訓(xùn)練打下堅(jiān)實(shí)基礎(chǔ)。
目前,通過(guò)采用低資源ASR落地流程,已有兩個(gè)低資源語(yǔ)言成功落地視頻字幕和內(nèi)容安全業(yè)務(wù)。除語(yǔ)音識(shí)別外,基于wav2vec2.0的預(yù)訓(xùn)練模型在其他多個(gè)下游任務(wù)上也已取得顯著收益,涉及音頻事件檢測(cè)、語(yǔ)種識(shí)別、情感檢測(cè)等,未來(lái)將陸續(xù)落地到視頻內(nèi)容安全、推薦、分析、音頻分流、電商客服情感分析等相關(guān)業(yè)務(wù)中。無(wú)監(jiān)督預(yù)訓(xùn)練技術(shù)的落地將顯著降低各類(lèi)音頻數(shù)據(jù)的標(biāo)注成本,縮短標(biāo)注周期,實(shí)現(xiàn)對(duì)業(yè)務(wù)需求的快速響應(yīng)。
總結(jié)與展望
火山語(yǔ)音團(tuán)隊(duì)在實(shí)踐中摸索出一套基于wav2vec2.0的低資源語(yǔ)種ASR落地方案,解決了推理開(kāi)銷(xiāo)大的問(wèn)題,實(shí)現(xiàn)了與端到端引擎的無(wú)縫銜接。針對(duì)其中最核心的wav2vec2.0訓(xùn)練效率低和不穩(wěn)定的問(wèn)題,提出了Efficient wav2vec。相比wav2vec2.0,在下游任務(wù)上效果提升5%,預(yù)訓(xùn)練耗時(shí)縮短一半,結(jié)合工程上的優(yōu)化,最終預(yù)訓(xùn)練耗時(shí)相比原始版本縮短70%。未來(lái),火山語(yǔ)音團(tuán)隊(duì)將在以下三個(gè)方向持續(xù)挖掘探索:
無(wú)監(jiān)督算法升級(jí):在wav2vec 2.0之后語(yǔ)音無(wú)監(jiān)督預(yù)訓(xùn)練的研究工作如雨后春筍,團(tuán)隊(duì)將持續(xù)跟進(jìn)最新的研究,并內(nèi)化到業(yè)務(wù)場(chǎng)景。現(xiàn)階段主要嘗試了HuBERT[2]、MAE[6] 和 data2vec[7]等無(wú)監(jiān)督模型,并探索了它們各自在不同下游任務(wù)下的表現(xiàn)。未來(lái)將從兩個(gè)方面提升無(wú)監(jiān)督模型性能:根據(jù)不同業(yè)務(wù)場(chǎng)景,設(shè)計(jì)高效適配的無(wú)監(jiān)督方案;設(shè)計(jì)通用的無(wú)監(jiān)督模型,提升在各類(lèi)下游任務(wù)的性能表現(xiàn)。
多語(yǔ)言多模態(tài):目前無(wú)監(jiān)督與多語(yǔ)言結(jié)合的研究工作有許多,比如XLSR[8]。團(tuán)隊(duì)在此基礎(chǔ)上提出了S3Net[9],其通過(guò)在預(yù)訓(xùn)練模型中劃分出多個(gè)稀疏子網(wǎng)絡(luò)來(lái)分別對(duì)不同語(yǔ)言進(jìn)行建模,有效緩解了不同語(yǔ)言之間的相互干擾(Language Interference)問(wèn)題,對(duì)大語(yǔ)料語(yǔ)言有明顯的性能提升效果。現(xiàn)有的研究工作主要集中在音頻編碼器端進(jìn)行,而目前主流的端到端模型均采用了編碼器-解碼器結(jié)構(gòu),即音頻文本多模態(tài)建模。團(tuán)隊(duì)判斷單純的音頻端預(yù)訓(xùn)練已經(jīng)不能滿(mǎn)足端到端模型的需要,未來(lái)將在音頻文本多模態(tài)預(yù)訓(xùn)練上進(jìn)行探索工作,分別是海量非對(duì)齊音頻文本與端到端模型聯(lián)合建模以及純無(wú)監(jiān)督的多模態(tài)預(yù)訓(xùn)練。
大數(shù)據(jù)大模型:現(xiàn)有的模型在10萬(wàn)小時(shí)規(guī)模時(shí)其性能就接近飽和,團(tuán)隊(duì)在中文10萬(wàn)小時(shí)標(biāo)注數(shù)據(jù)訓(xùn)練的模型基礎(chǔ)上,利用100萬(wàn)小時(shí)無(wú)標(biāo)注數(shù)據(jù)做NST[10]訓(xùn)練,在通用測(cè)試集上取得相對(duì)7%的CER下降,同時(shí)模型的泛化能力得到明顯的改善,在20個(gè)領(lǐng)域測(cè)試集上平均CER相對(duì)下降15%。要充分吸收百萬(wàn)小時(shí)量級(jí)的海量數(shù)據(jù)就需要更大的模型,目前團(tuán)隊(duì)已經(jīng)在1B參數(shù)量級(jí)的模型上取得初步進(jìn)展。大模型的性能上限高,隨之而來(lái)的問(wèn)題是落地難。為了將大模型落地到實(shí)際業(yè)務(wù)中,未來(lái)將嘗試各種模型壓縮方法,如矩陣分解、權(quán)重裁剪和知識(shí)蒸餾等,盡可能做到無(wú)損壓縮效果。
火山語(yǔ)音,長(zhǎng)期以來(lái)面向字節(jié)跳動(dòng)各大業(yè)務(wù)線以及火山引擎ToB行業(yè)與創(chuàng)新場(chǎng)景,提供全球領(lǐng)先的AI語(yǔ)音技術(shù)能力以及卓越的全棧語(yǔ)音產(chǎn)品解決方案,包括音頻理解、音頻合成、虛擬數(shù)字人、對(duì)話(huà)交互、音樂(lè)檢索、智能硬件等。目前團(tuán)隊(duì)的語(yǔ)音識(shí)別和語(yǔ)音合成覆蓋了多種語(yǔ)言和方言,多篇技術(shù)論文入選各類(lèi)AI 頂級(jí)會(huì)議,為抖音、剪映、飛書(shū)、番茄小說(shuō)、Pico等業(yè)務(wù)提供了領(lǐng)先的語(yǔ)音能力,并適用于短視頻、直播、視頻創(chuàng)作、辦公以及穿戴設(shè)備等多樣化場(chǎng)景,通過(guò)火山引擎開(kāi)放給外部企業(yè)。
參考文獻(xiàn)
[1] Baevski, A., Zhou, Y., Mohamed, A. and Auli, M., 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33, pp.12449-12460.
[2] Hsu, W.N., Bolte, B., Tsai, Y.H.H., Lakhotia, K., Salakhutdinov, R. and Mohamed, A., 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, pp.3451-3460.
[3] Graves, A., Fernández, S., Gomez, F. and Schmidhuber, J., 2006, June. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (pp. 369-376).
[4] Chan, W., Jaitly, N., Le, Q. and Vinyals, O., 2016, March. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 4960-4964). IEEE.
[5] Graves, A., 2012. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711.
[6] He, K., Chen, X., Xie, S., Li, Y., Dollár, P. and Girshick, R., 2022. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000-16009).
[7] Baevski, A., Hsu, W.N., Xu, Q., Babu, A., Gu, J. and Auli, M., 2022. Data2vec: A general framework for self-supervised learning in speech, vision and language. arXiv preprint arXiv:2202.03555.
[8] Conneau, A., Baevski, A., Collobert, R., Mohamed, A. and Auli, M., 2020. Unsupervised cross-lingual representation learning for speech recognition. arXiv preprint arXiv:2006.13979.
[9] Lu, Y., Huang, M., Qu, X., Wei, P. and Ma, Z., 2022, May. Language adaptive cross-lingual speech representation learning with sparse sharing sub-networks. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6882-6886). IEEE.
[10] Park, D.S., Zhang, Y., Jia, Y., Han, W., Chiu, C.C., Li, B., Wu, Y. and Le, Q.V., 2020. Improved noisy student training for automatic speech recognition. arXiv preprint arXiv:2005.09629.
本文為澎湃號(hào)作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場(chǎng),澎湃新聞僅提供信息發(fā)布平臺(tái)。申請(qǐng)澎湃號(hào)請(qǐng)用電腦訪問(wèn)http://renzheng.thepaper.cn。



- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

