- +1
Meta:已開發閩南語AI翻譯,解決無文字語言翻譯難題
·機器學習翻譯系統通常需要大量可標記的語言實例來進行訓練,包括書面和口頭語言,這正是像閩南語這種沒有文字的語言所不具備的。Meta的研究團隊利用普通話作為中間語言來建立偽標簽,首先將英語(或閩南語)語音翻譯成普通話文本,然后再翻譯成閩南語(或英語),并將其加入訓練數據。
·“我們希望最終能夠實現多種語言的實時語音到語音翻譯。我們相信,無論人們身處何地,口語交流都能將他們聚集在一起——即使是在元宇宙。”
世界上大約7000種已知的語言中,有近一半的語言仍然在被使用,其中40%沒有廣泛的書寫系統。這些沒有文字的語言給現代機器學習翻譯系統帶來了一個獨特的問題,因為它們通常需要先將口頭語言轉換為書面文字,翻譯后再將文字還原為語音,但Meta公司10月19日宣布,已經通過其最新的開源語言人工智能(AI)解決了這個問題。
作為Meta通用語音翻譯器(UST)項目的一部分,Meta 為閩南語建立了第一個AI驅動的語音翻譯系統,并在視頻中展示了一段閩南語和英語之間的實時翻譯。該項目正致力于開發更多實時語音到語音的翻譯,以便元宇宙居民更方便地互動。
機器學習翻譯系統通常需要大量可標記的語言實例來進行訓練,包括書面和口頭語言,這正是像閩南語這種沒有文字的語言所不具備的。為了解決這個問題,“我們使用語音到單元翻譯(S2UT)將輸入的語音直接轉換為之前由Meta開創的聲學單元序列。”Meta的研究團隊在新聞稿中解釋說,“然后,我們從這些單元生成波形。此外,UnitY被采用為雙通解碼機制,第一通解碼器生成相關語言(普通話)的文本,第二通解碼器創建單元。”
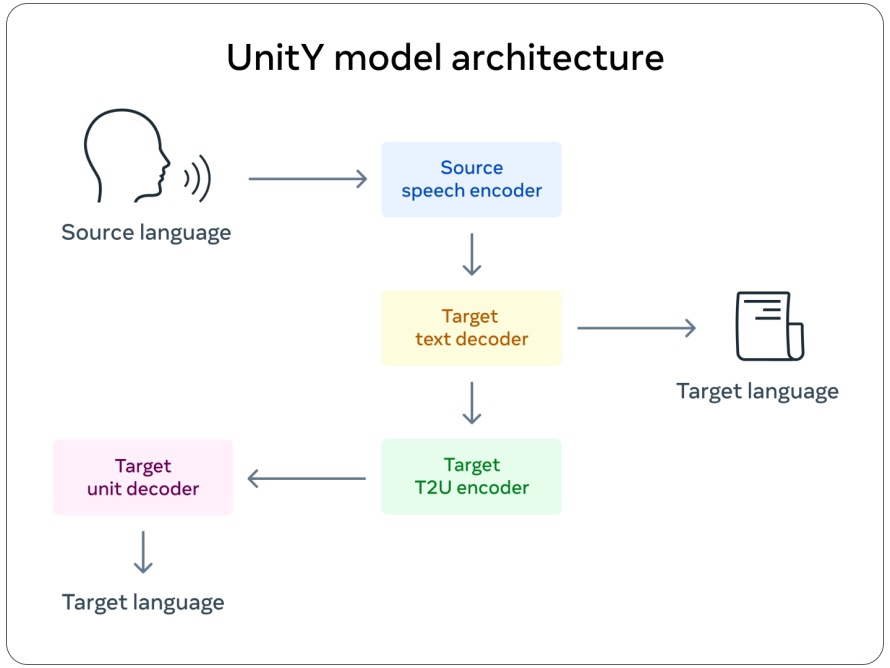
UnitY語音翻譯系統的模型架構。圖片來源:Meta
“我們利用普通話作為中間語言來建立偽標簽,我們首先將英語(或閩南語)語音翻譯成普通話文本,然后我們再翻譯成閩南語(或英語),并將其加入訓練數據。”Meta的研究團隊稱。目前,該系統允許講閩南語的人與講英語的人交談,盡管很生硬。該模型一次只能翻譯一個完整的句子,但扎克伯格相信,這項技術最終可以應用于更多語言,并將改進到提供實時翻譯的程度。
Meta宣布,除了從這個項目中獲得開源的模型和訓練數據外,該公司正在發布首個基于閩南語語料庫的語音翻譯基準系統,以及語音矩陣(SpeechMatrix),“一個使用Meta的LASER數據挖掘技術的大型語音到語音翻譯語料庫”,這個系統將使研究人員能夠創建他們自己的語音到語音翻譯(S2ST)系統。
“我們希望最終能夠實現多種語言的實時語音到語音翻譯。我們相信,無論人們身處何地,口語交流都能將他們聚集在一起——即使是在元宇宙。”Meta的研究團隊在新聞稿中寫道,“我們的人工智能研究正在幫助打破物理世界和元宇宙的語言障礙,以鼓勵聯系和相互理解。我們期待著擴大我研究,并在未來將這項技術帶給更多的人。”
挑戰:數據收集、翻譯評估
Meta還強調了這項技術面臨的挑戰。研究人員稱,收集足夠的數據是他們建立閩南語翻譯系統時面臨的一個重大障礙。“閩南話是一種所謂的低資源語言,這意味著與西班牙語或英語相比,沒有大量的訓練數據可供利用。此外,英語到閩南語的翻譯人員相對較少,這使得收集和注釋數據以訓練模型變得困難。”Meta的研究團隊在新聞稿里寫道。所以他們利用普通話作為中間語言來建立偽標簽以及人工翻譯,這種方法通過利用類似的高資源語言的數據,大大提高了模型的性能。
此外,對于像閩南語這樣的口頭語言,評估語音翻譯也面臨挑戰。為了能夠進行自動評估,他們開發了一個系統,將閩南語轉寫成一個標準化的語音符號。
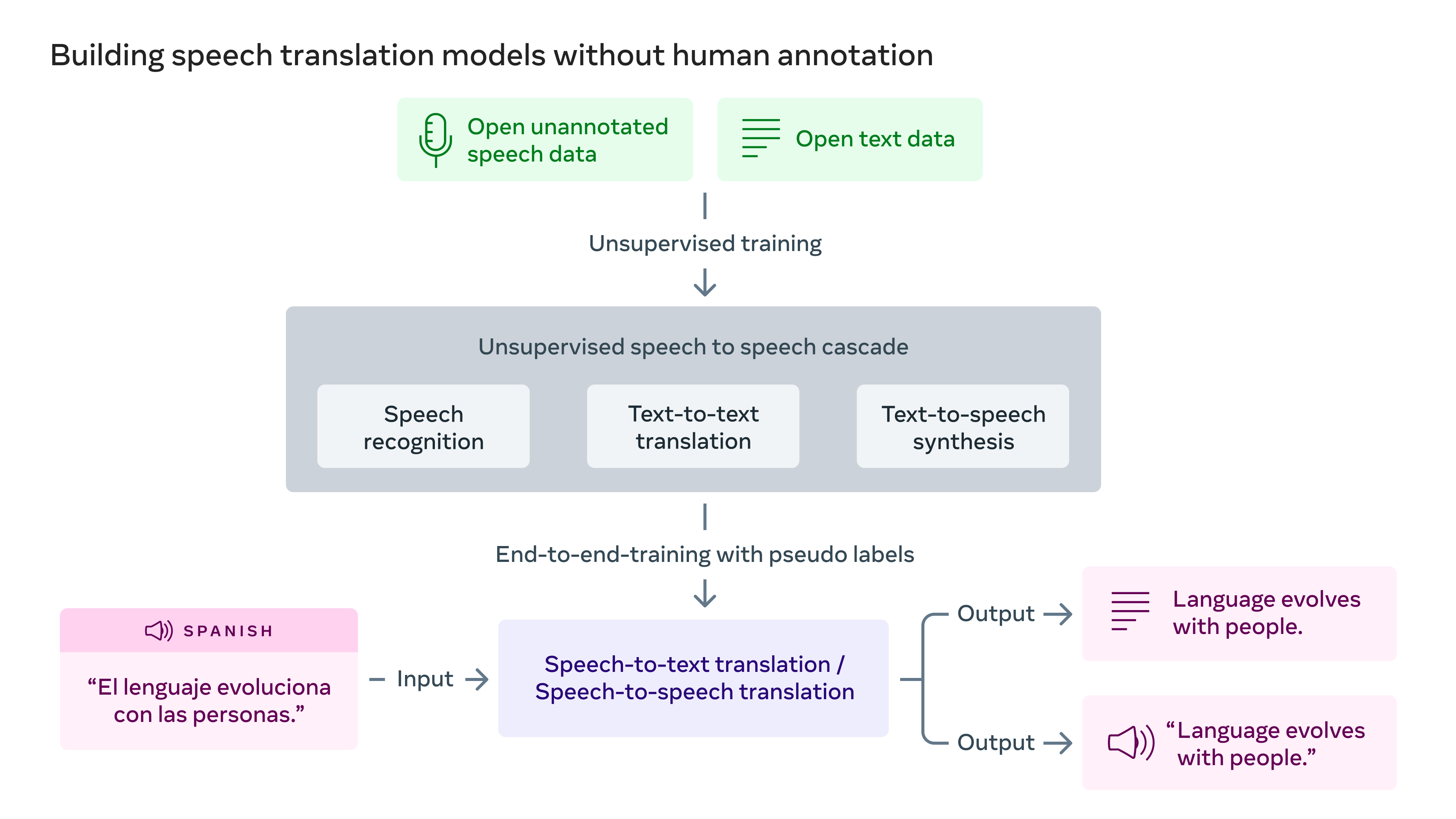
建立沒有人類標記的語音翻譯模型。圖片來源:Meta
Meta公司宣稱,最近在無監督語音識別(wav2vec-U)和無監督機器翻譯(mBART)方面取得的進展,將為未來翻譯更多口語的工作提供參考。“我們在無監督學習方面的進展表明,在沒有任何人類注釋的情況下建立高質量的語音到語音翻譯模型是可行的。該系統大大降低了擴大低資源語言覆蓋面的要求,因為許多語言根本沒有標注的數據。”
參考資料:
https://about.fb.com/news/2022/10/hokkien-ai-speech-translation/
https://ai.facebook.com/blog/ai-translation-hokkien/



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

