- +1
聲網(wǎng)3D在線互動(dòng)場景空間音頻的實(shí)時(shí)渲染——如何把“聲臨其境”推向極致
編者按: 千人有千耳,不同的人耳對于聲音方位的適應(yīng)已形成習(xí)慣,但在Meta RTC場景中如何讓不同人也能暢想“身臨其境”的感覺?3D在線互動(dòng)場景空間音頻的實(shí)時(shí)渲染又有哪些應(yīng)用?LiveVideoStackCon 2022音視頻技術(shù)大會(huì)上海站邀請到了聲網(wǎng)音頻策劃負(fù)責(zé)人馮建元,為我們分享3D在線互動(dòng)場景空間音頻的實(shí)時(shí)渲染。
文/馮建元
整理/LiveVideoStack

大家下午好,我是來自聲網(wǎng)的馮建元。
今天給大家主要分享一下聲網(wǎng)在RTC 3D互動(dòng)場景中是如何操作空間音頻的渲染。讓人在虛擬的場景里感受現(xiàn)實(shí)生活中一樣聲臨其境的感覺。

我在聲網(wǎng)的主要負(fù)責(zé)音頻算法的開發(fā),之前也做過語音的增強(qiáng)、音效,包括音頻的編解碼的工作,也發(fā)布過基于AI的聲網(wǎng)Silver之類的編解碼器等,也開過一些介紹音頻的課程,包括《搞定音頻技術(shù)》等等。

今天主要是圍繞Meta RTC,探討如何實(shí)現(xiàn)聲臨其境,需要哪些渲染的方法,以及不同的聲音的渲染方法,是如何通過端云結(jié)合的形式去實(shí)現(xiàn)的,這會(huì)涉及算力成本、怎樣部署更合理、低延遲等等。最后介紹空間音頻在行業(yè)有些怎樣的應(yīng)用,是如何重塑我們在游戲以及社交行業(yè)的不同音頻體驗(yàn)。
1、在Meta RTC場景中如何實(shí)現(xiàn)“身臨其境”?

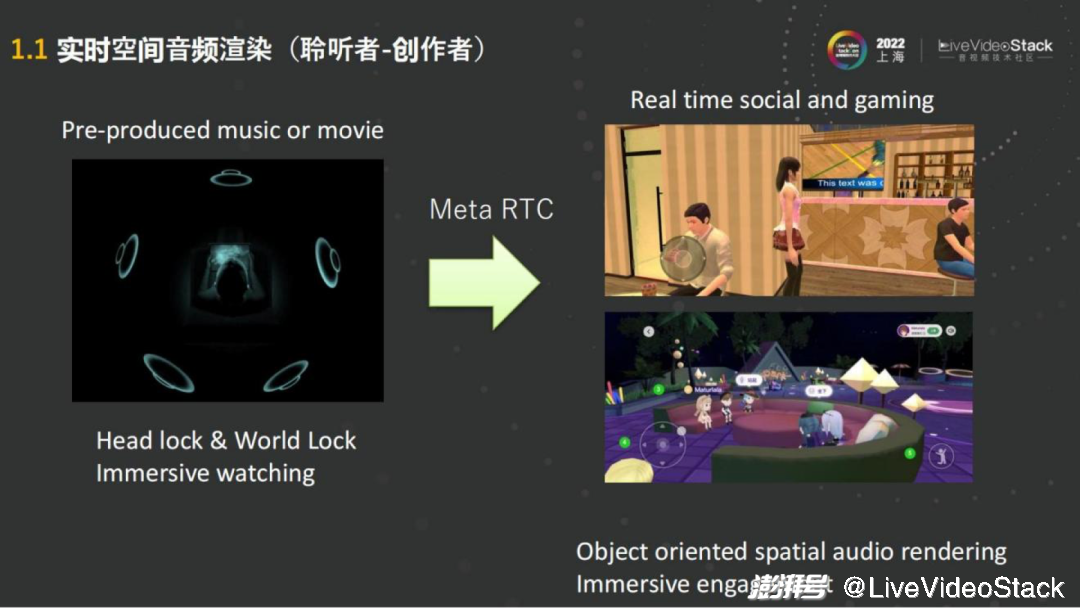
去年蘋果發(fā)布了AirPods能夠支持空間音頻之后,空間音頻迎來了一個(gè)小的高潮。主要的技術(shù)是基于杜比Atmos、DTS這些音頻的制作,來實(shí)現(xiàn)沉浸式的多聲道的播放。
例如通過蘋果的AirPods聽空間音頻的音樂,通過使用者頭部的轉(zhuǎn)動(dòng),會(huì)發(fā)現(xiàn)聲音可以根據(jù)手機(jī)和頭部的位置實(shí)時(shí)移動(dòng)。這些音源多數(shù)是需要預(yù)先制作的,在RTC的場景中每一個(gè)人就是內(nèi)容的生產(chǎn)者,可以理解為使用者在虛擬的世界里去演一部電影,需要去聽周圍的任何一個(gè)音源的聲音,會(huì)有空間的感知,相對的在遠(yuǎn)端進(jìn)行互動(dòng)的人也同樣需要在這種環(huán)境里體驗(yàn)沉浸式的音頻。
其實(shí)在Real time social或者gaming的場景里面,加入了位置信息,比如不同的朝向、距離等,就可以對聲場中的人或者音源去進(jìn)行渲染。這些大部分都是基于目標(biāo)的渲染,就比如人們作為一個(gè)聽音者,在下面聽我說話,我在有些人的左邊,也在有些人的右邊,但聲音會(huì)通過現(xiàn)場的揚(yáng)聲器播放,會(huì)有一個(gè)整體的聲場。這些都可以通過針對這些無論是說話人還是揚(yáng)聲器的音源來進(jìn)行渲染。
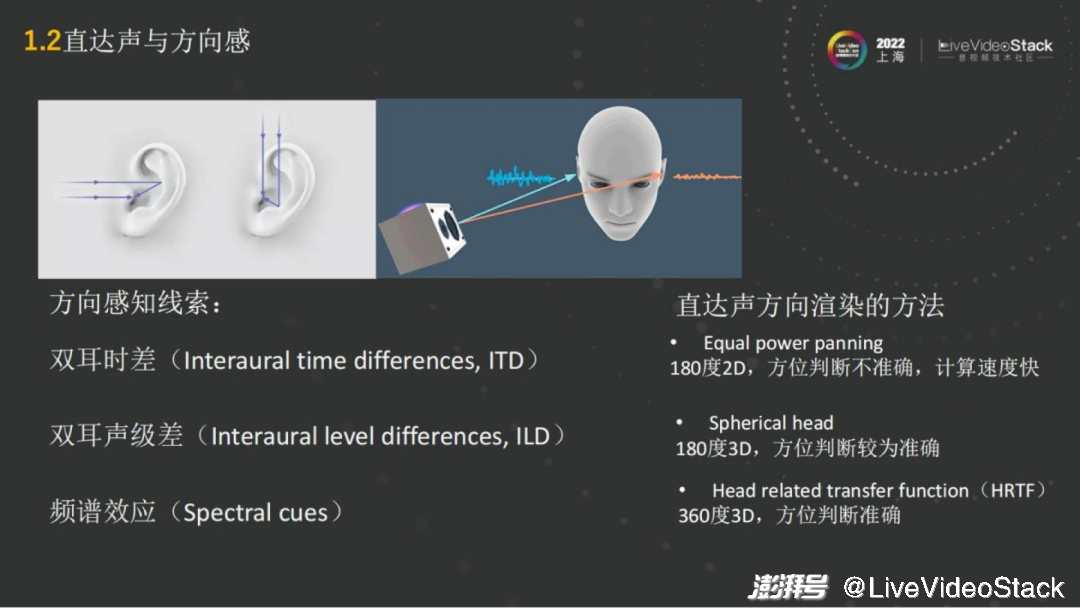
從具體的技術(shù)角度而言,如何去實(shí)現(xiàn)空間音頻的渲染呢?首先我們把它分成直達(dá)聲和混響。直達(dá)聲就是發(fā)出的聲波直接傳到人的耳朵,人的兩只耳朵是聽音辨位的一個(gè)前提條件,因?yàn)閮芍欢鋾?huì)有雙耳差的音源的線索,這樣就能通過線索來進(jìn)行聲音的位置判斷。
主要的方向感的線索,比如雙耳的時(shí)間差。就像在人的右邊說話,右耳是最先接收到聲波信號的,左耳就會(huì)有跨越頭部的延遲。通過延遲就能大致了解聲音大概是在哪邊。
第二個(gè)就是雙耳的音量也會(huì)有所差異,因?yàn)槁曇粼趥鞑サ臅r(shí)候會(huì)有所衰減,左右耳就會(huì)有不同的音量,這個(gè)比較顯而易見。
第三個(gè)就在于每個(gè)人的耳朵耳廓是有朝向的,有些人的耳廓比較朝前,像招風(fēng)耳,那他對前面聲音的感知會(huì)比較明顯。耳廓信息,它會(huì)對人感知到的聲音,不同的頻段的響度,都會(huì)有頻譜的效應(yīng)。所以每個(gè)人耳朵聽到的音色都是不一樣的,根據(jù)耳廓和聲音傳播的方向都會(huì)有所區(qū)別。
通過這三個(gè)不同的感知線索,就可以很清楚地分別空間中聲音的位置了。為了去渲染音源,找到它所在的位置,同時(shí)會(huì)利用這三個(gè)線索。
例如簡單的方法,左右耳去做一個(gè)panning,即做一個(gè)音量的區(qū)別,就能簡單的實(shí)現(xiàn)2D空間的180度只能區(qū)分左右的panning算法。這種算法的優(yōu)點(diǎn)就是只需要控制耳機(jī)左右耳的音量,幾乎沒有什么算力。同時(shí)缺點(diǎn)也很明顯,它只控制了左右耳的音量,如果音源是在正中間,無論是上下還是前后,都是無法去通過音量來調(diào)整的,所以就只能實(shí)現(xiàn)180度的2D。如果再精確一點(diǎn),那就會(huì)用到頭部模型,例如 Spherical head——把頭模擬成紡錘形狀。能將左右耳、音級差進(jìn)行模擬,獲得180度的3D的渲染。但這依然很難模擬人耳完整的信息,前后的信息更多是靠耳朵的形狀做音色上的區(qū)分。
那么最精準(zhǔn)的是什么?最精準(zhǔn)的渲染方法就是Head Related Transfer Function(HRTF),基于HRTF的渲染。
這是目前空間音頻基于 Object渲染的方法中最常用的一種,能夠?qū)崿F(xiàn)360度每一個(gè)3D的角度都準(zhǔn)確地判斷。
具體實(shí)現(xiàn)講解:

在幾十年前HRTF技術(shù)就產(chǎn)生了。在人耳朵的不同的方向放一個(gè)聲源,例如放一個(gè)音箱,然后通過去測量每一個(gè)方向音箱到人耳傳遞方程的沖擊響應(yīng),就能得到球面的雙耳的沖擊響應(yīng),這就是HRIR。
如上左圖,幾乎所有的方向都會(huì)測量一遍,就會(huì)得到一個(gè)離散的沖擊響應(yīng),可以通過差值的方法把它變成連續(xù)的整個(gè)球面各個(gè)方向的沖擊響應(yīng),當(dāng)有一個(gè)單聲道的聲音過來的時(shí)候,就可以“告訴”它人耳在這個(gè)位置,去卷積這個(gè)方向的沖擊響應(yīng),就可以得到雙耳渲染道的音頻。
目前看來這個(gè)方法可以說是最準(zhǔn)確的,它是真人在全消實(shí)驗(yàn)室中進(jìn)行實(shí)驗(yàn)、采集得到的。
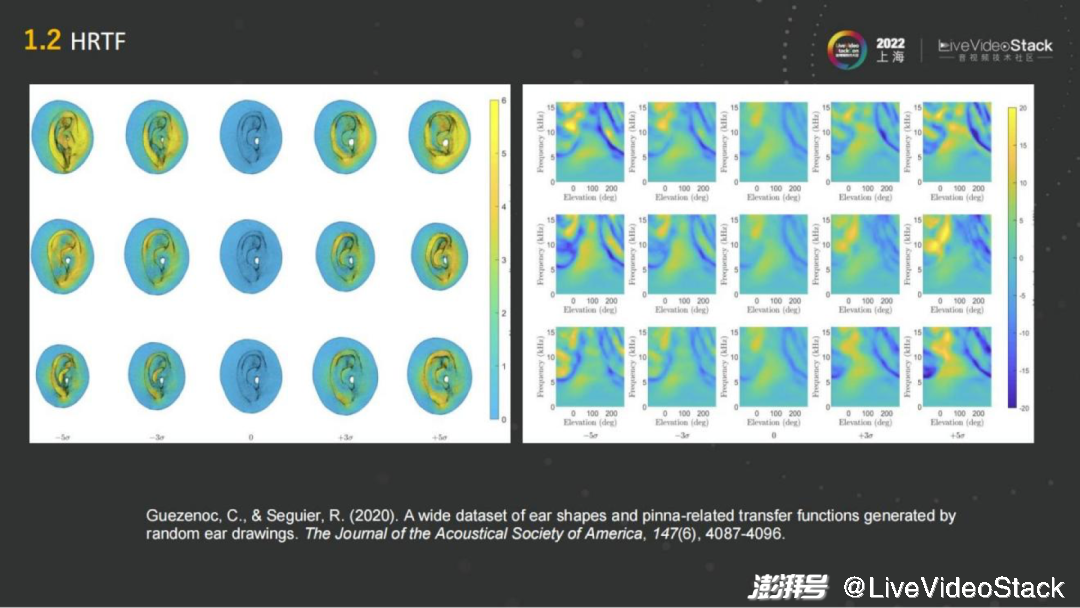
正常人的耳朵雖然都差不多但還是有區(qū)別的,每個(gè)人的耳朵無論是朝向還是形狀都不太一樣,都相當(dāng)于一個(gè)濾波器,所聽到的聲音雖然左右都能區(qū)分,但是其實(shí)一個(gè)人聽到的聲音跟其他人聽到的聲音是不一樣的。那我們要如何判斷聲音的方向或者是空間的感知呢?
它其實(shí)是一個(gè)長期記憶的過程,在長期的生活中,人們通過聽不同的方向聲音,就像是訓(xùn)練大腦一樣,長期的訓(xùn)練就能比較準(zhǔn)確判斷聲音出現(xiàn)在哪個(gè)方位。不同的耳朵對于自身而言已經(jīng)有了適應(yīng)性,大腦已經(jīng)被訓(xùn)練好了。因而缺點(diǎn)也比較顯而易見,當(dāng)一個(gè)人在操作虛擬環(huán)境的渲染的時(shí)候,用的HRTF可能是一個(gè)通用的HRTF, 它可能是一個(gè)人工頭的HRTF,也可能是別人的耳朵的HRTF,跟現(xiàn)實(shí)生活中的音色的體驗(yàn)就會(huì)有差異。

基于此我們就繼續(xù)看能不能把它再做得極致些,能夠讓使用者有一個(gè)性化的體驗(yàn)。這就是個(gè)性化HRTF,大概經(jīng)歷了10多年的發(fā)展,通過研究怎樣通過建模的方法以人的耳朵或者頭部為基礎(chǔ),得到個(gè)性化的空間音頻渲染的方法。
在這里面我主要羅列了一些近些年比較常見的方法,例如最簡單的通過測量耳朵的生理結(jié)構(gòu),包括20多種不同的結(jié)構(gòu)例如、長、寬、深度、耳道的大小等等。通過量取這些數(shù)據(jù),然后把它們進(jìn)行 HRTF的建模,把通用的HRTF調(diào)整成符合不同耳朵的參數(shù),來達(dá)到個(gè)性化。這種方法還是比較有難度的,只能提取較少的一個(gè)信息去操作,準(zhǔn)確率也不是很高。
隨著AI的模型的引用,包括現(xiàn)在有很多技術(shù)也是基于AI的模型去做的。最新的像Meta 發(fā)布的一個(gè)方案,通過掃描整個(gè)人的3D頭部模型,用3D掃描信息作為輸入,然后用AI的模型去生成個(gè)性化HRTF,目前已經(jīng)能達(dá)到頻譜的差異小于1DB,很接近真實(shí)的 HRTF測量。
但最準(zhǔn)確的測量(Golden standard)還是在實(shí)驗(yàn)室里,每一個(gè)方向測一遍。目前通過AI模型和頭部掃描,基本上能夠?qū)崿F(xiàn)和Golden standard差不多的水平。
例如iOS16,因?yàn)閕Phone是有深度攝像頭的,也有掃描的功能。通過掃描人左右耳朵,可以生成個(gè)性化的HRTF。基于此再去做空間音頻渲染的時(shí)候,就能得到個(gè)性化的最自然的空間音頻渲染。

剛才主要是聊如何做聽音辨位和渲染。另外,人耳都有遠(yuǎn)近的感知,離得遠(yuǎn)和湊近講話聽到的聲音也是不一樣的,針對此比較簡單的方法是調(diào)整音量。其實(shí)人對位置的感知是相對感知,不是絕對感知,即通過距離的由遠(yuǎn)到近,慢慢地聲音變大,或者是由近到遠(yuǎn),聲音慢慢變小,人能感知到它是在遠(yuǎn)離還是靠近,但是在某個(gè)音量下想要知道它到底離人有多遠(yuǎn),是很難通過絕對感知。
這個(gè)過程里有很多可以做的。首先音量是在空氣中傳播的,不同的頻段的衰減是不一樣的,高頻衰減更快,低頻衰減更慢。在距離比較遠(yuǎn)的時(shí)候,會(huì)覺得發(fā)聲人的聲音除了聲音小之外,還變“悶”了,這也是基于人的主觀感知。
那么,只做音量和做了空氣吸收/不同頻響的均衡,有什么樣的區(qū)別?
示例中的兩條音樂,聲音都是從25到100米,但能明顯聽到后者的聲音在比較遠(yuǎn)的時(shí)候已經(jīng)開始變“悶”了,給人的一種更遙遠(yuǎn)的感覺會(huì)更加逼真,這也是距離感知上可以做的一點(diǎn)
這樣的衰減如果程度更多一點(diǎn),例如模擬水下的衰減場景,在水里面說話的咕嚕咕嚕的感覺,也能夠靠這種方式模擬出來。
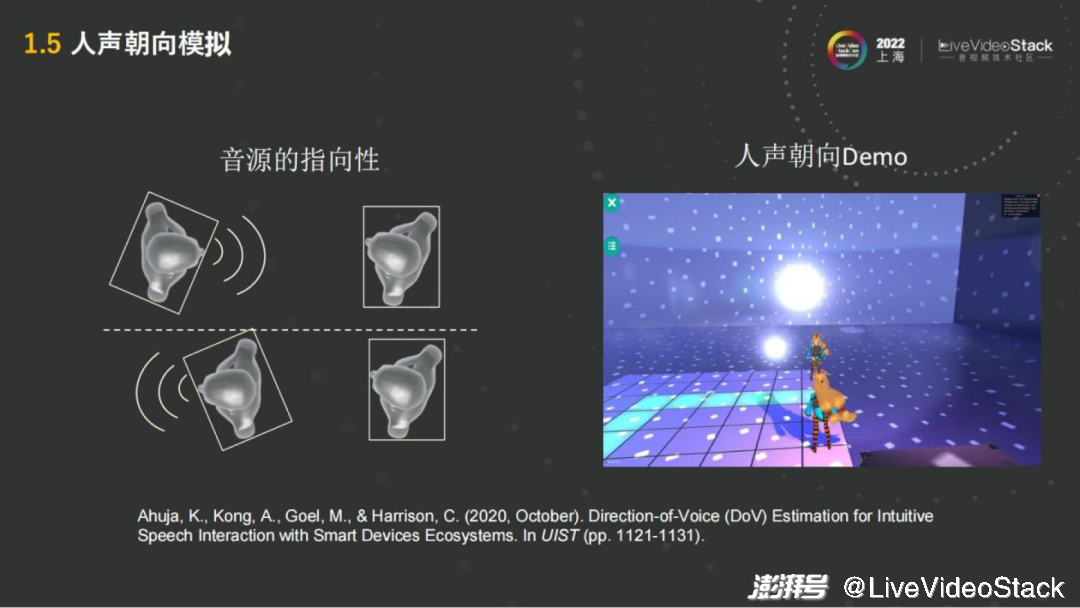
除了距離之外,還有很重要的一點(diǎn)——朝向,正對人說話和背對人說話的聲音是不一樣的。正對人說話是直接從嘴到另一人的耳朵,中間沒有什么障礙,但背對著則聲音需要跨過頭和身軀,在進(jìn)入另一人的耳朵,這個(gè)過程聲音會(huì)有衰減。
這也說明音源是有指向性的。無論是人還是音箱,模擬的時(shí)候都會(huì)有這種指向性的模擬。指向性的模擬來就是在不同的方向,需要對它的不同的頻響去做出調(diào)整,這也是在空間音頻的模擬中比較重要的一點(diǎn)。
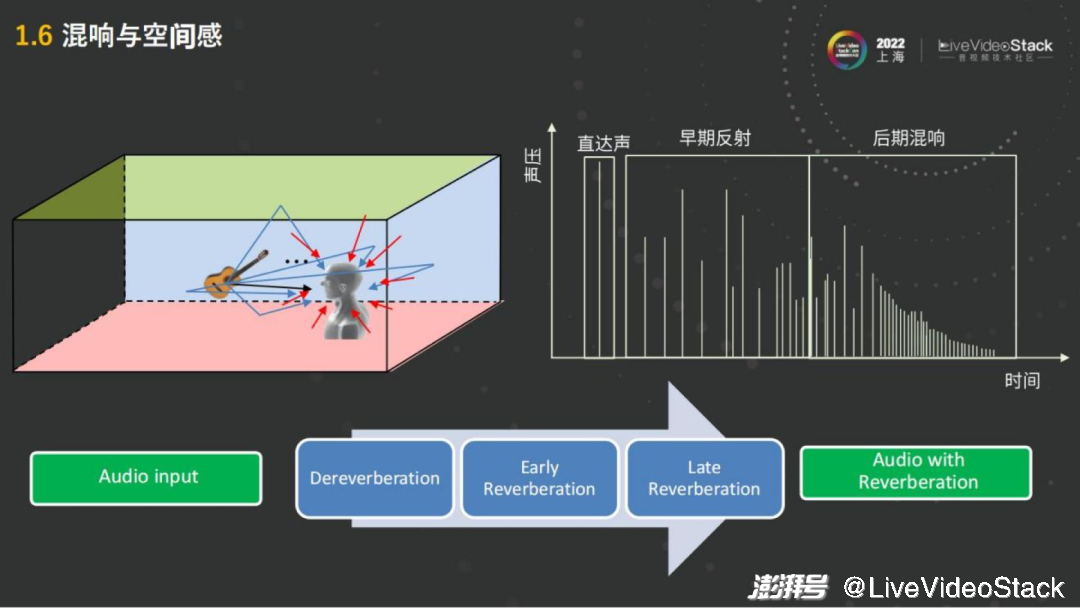
以上所說都是直達(dá)聲的渲染,一人的嘴到另一人的耳朵,中間沒有經(jīng)過其他物品的反射。在聲音的產(chǎn)生過程中人要感受,例如這個(gè)房間是大房間還是小房間,它裝修的材質(zhì)是玻璃房還是木板房鋪地毯,不同材質(zhì)也會(huì)有區(qū)別。
右圖而言第一個(gè)是模擬直達(dá)聲,第一個(gè)聲波過來,會(huì)有早期的反射,就像我的聲音通過木板、房頂。例如地毯的吸收的能力比較強(qiáng),反射比較少。
這些反射的聲音,會(huì)混到人的直達(dá)聲之中,跟它混接在一起,這樣的話人就能感受到所處的空間大概是怎樣反射的延遲以及整個(gè)反射空間是否密集,就會(huì)得到一個(gè)混響。混響也分早期的反射,例如第一次反射或者第二次反射。也包括后期的混響,后期混響反射還可以再反射,很多反射的疊加之后就會(huì)得到一個(gè)比較密集的后期混響。后期混響在玻璃的房間,或者是在混響延遲比較長的大的空間會(huì)多一點(diǎn)。
人對空間的感知,空間、裝修材質(zhì)、大小,主要是通過混響來提供的。所以在空間音頻的渲染中會(huì)起到比較大的作用。如果只有直達(dá)聲,人就相當(dāng)于在一個(gè)全消實(shí)驗(yàn)室,沒有任何混響,人的聲音會(huì)聽上去非常的“干”,這個(gè)聲音就叫干聲,如果有混響就比較“濕”,這種叫濕音。
操作渲染并不簡單,不能直接的去加一個(gè)混響,原因在于在實(shí)時(shí)RTC的過程中,例如在一個(gè)會(huì)議室、玻璃房里,本身它就有混響,如果是在混響之上再疊加混響,它就變糊了,人就聽不清楚了。在營造一個(gè)比較好的統(tǒng)一的混響的環(huán)境,或者統(tǒng)一的虛擬房間的環(huán)境時(shí),第一步需要先做解混響,把人的聲音先再從濕音變成干聲,這就是第一步Dereverberation解混響。然后再加入早期的反射,Early Reverberation或是加入后期的混響。早期后期的這些混響可以通過鏡面法或者早期的反射,后期的混響可以通過 Feed forward或者Feedback delay這種方式去做。
其實(shí)整體的算力來說它比直達(dá)聲高些,因?yàn)檎麄€(gè)混響包括很多個(gè)聲波的模擬,可以提供比較好的空間感,空間感在空間音頻中也是比較重要的一點(diǎn)。

在整個(gè)聲音中有了直達(dá)聲、有了混響基本上也就齊了,人能聽到的聲音都有。但在元場景Meta RTC中,它是源于現(xiàn)實(shí)但是又超越于現(xiàn)實(shí)的,例如你在現(xiàn)實(shí)中參加演唱會(huì)、雞尾酒會(huì),周圍有很多的人很嘈雜,但是你卻想聽樂隊(duì)的聲音。這個(gè)時(shí)候還是挺麻煩的,如果買的座位不是在第一排,可能聽不清,聽到全是旁邊的歡呼聲和唱歌的聲音。
這種情況需要有一個(gè)氛圍,就是周邊人在說話的同時(shí)不會(huì)干擾到你對于自己目標(biāo)的這樣聽取。這就可以通過人聲模糊的方法,把周圍的人的聲音進(jìn)行模糊化處理,達(dá)到能聽到說話聲,但是不知道別人在說什么。這也能在互動(dòng)場景里面提升聽聲音的體驗(yàn)。

除了模糊還有其他方面,例如在現(xiàn)在(演講)的環(huán)境中,大家的聲音都是在沒有遮擋情況之下的。但在一個(gè)虛擬的世界中,有多個(gè)房間,或者雙方在隔了一堵墻的情況下,就會(huì)有音障既為聲音障礙,是需要通過空間音頻渲染進(jìn)行模擬的。
在沒有障礙物的時(shí)候,聲音是直接傳播過去的。當(dāng)有障礙物的時(shí)候,它會(huì)讓人的聲音變悶,或者是讓人聲音的傳播的距離變小。在房間外聽屋內(nèi)人說話,近距離可以聽到,但離得遠(yuǎn)衰減后就聽不見了。
為了模擬類似的音障、聲音衰減的管理,可以通過模擬不同的厚度的障礙物,實(shí)現(xiàn)衰減的調(diào)整。
面對稍厚的墻,只有一米左右才能聽到講話人的聲音。無障礙物或一堵薄墻的情況下聲音是慢慢衰減的。聲音的障礙還有很多其他的模擬方法,這是其中一種,通過聲音的衰減(音量衰減和銀色衰減)快慢來模擬。
還有別的模擬方法,例如聲音本身是一個(gè)衍射的狀態(tài),隔的不是墻而是柱子,聲音的模擬就會(huì)更加復(fù)雜。
2、端云結(jié)合的空間音頻實(shí)時(shí)渲染引擎的設(shè)計(jì)

以上所講從渲染的方式來說都是鏈路式的,是直達(dá)聲的渲染,然后做不同的混響,加入一些人聲模糊等等。總體上整套使用起來還是有算力成本的。

我們來看整個(gè)一條鏈路如何實(shí)現(xiàn),以及是怎樣設(shè)計(jì)空間音頻渲染的流程,算法可以部署在什么地方延時(shí)最小,算力最小,成本也可控呢?
第一步在空間音頻渲染中需要空間的設(shè)計(jì),因?yàn)閽伒粢曈X只談音頻沒有太大的意義。我們會(huì)有在虛擬場景的一些空間設(shè)計(jì),包括復(fù)雜的如基于Unity、 Unreal的游戲引擎的3D場景,也有簡單的如會(huì)議交互場景的頭像分布距離和角度,而我們無論是做2D的交互還是3D的交互是要預(yù)先設(shè)計(jì)好的。
有了這個(gè)功能之后,在這樣的一個(gè)場景里,我們自己是類似Avatar的化身,或者是一個(gè)頭像,我們所在的音源的位置以及朝向,以及聽音者的位置和朝向,和虛擬環(huán)境的參數(shù),例如房間的大小,中間有無聲音的障礙,這些就是Meta Data(元數(shù)據(jù))。它是決定怎樣去進(jìn)行渲染的基礎(chǔ)。
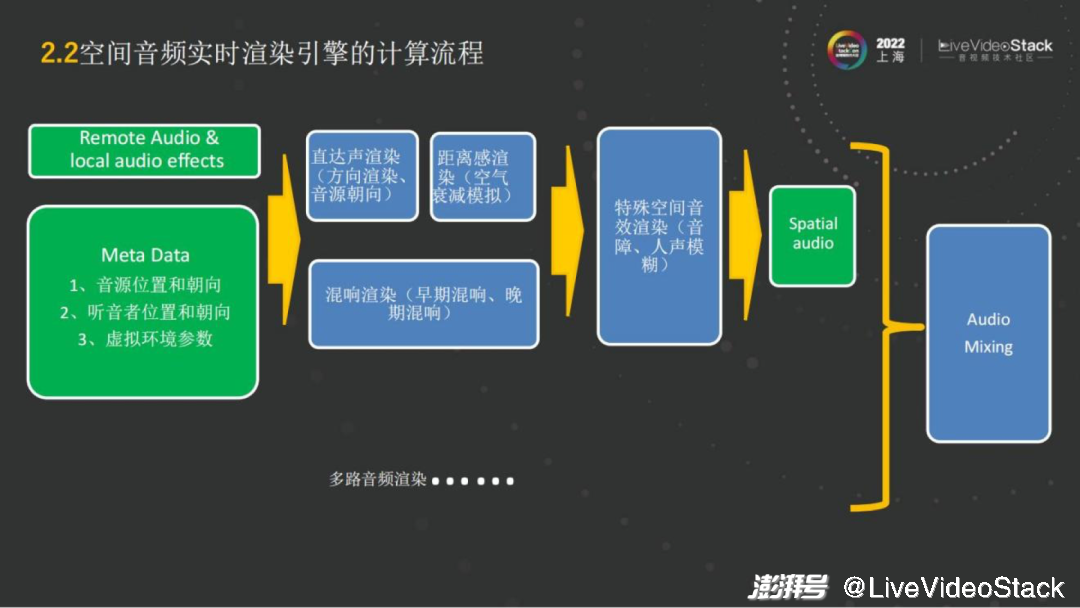
有了Meta Data,再結(jié)合傳統(tǒng)的RTC的遠(yuǎn)端的 Audio,或者是local的音效,就可以做空間音頻整體的渲染了。例如來了一路音頻流,首先要知道這路音頻流是屬于哪個(gè)ID,這個(gè)ID的Meta Data是什么,然后就可以對它進(jìn)行直達(dá)聲的渲染,包括方向的渲染、音源的朝向、距離的渲染。混響部分就是之前準(zhǔn)備好的房間里,包括這個(gè)房間大小多少,人處于房間的某個(gè)角落還是在正中央,位置在哪,來營造音頻流的混響氛圍。之后再看有沒有特殊的要求,例如是否需要選擇性地模糊某些音源。
最后當(dāng)每路音頻傳輸過來后或每個(gè)音源完成了空間音頻渲染,接下來就需要做混音,把多路的空間音頻混成特定聲道,例如耳機(jī)就是雙耳的立體聲,如果是5.1聲道,就把它混成5.1聲道的播放。
這就是整個(gè)空間音頻實(shí)時(shí)渲染的計(jì)算流程。從流程來看,它的算法部分整體來說是比較多的,包括直達(dá)聲的渲染,混響的渲染;從算力上而言,直達(dá)聲少一些,它相當(dāng)于編解碼中解碼的過程,跟解碼的算力相當(dāng)。如果是混響就會(huì)復(fù)雜一點(diǎn),取決于混響是精細(xì)還是粗糙,精細(xì)的混響對應(yīng)的算力就比較大。
整個(gè)流程而言,如果是在可控的范圍內(nèi),即渲染的路數(shù)不多時(shí),在端上運(yùn)行起來沒太大壓力,但是如果是千人會(huì)議,演唱會(huì),那在端上來說會(huì)比較困難。

這里有幾種方案,例如中心的服務(wù)器去做位置信息的這種計(jì)算、或者在端上去做。簡單而言,在RTC的音頻流里面,是可以直接把Meta信息放到音頻的包里去,里面就是 Meta的模塊。
音頻會(huì)隨著Audio和Meta Data同時(shí)傳播到遠(yuǎn)端,類似于P2P的網(wǎng)絡(luò)結(jié)構(gòu),每個(gè)人都是在自己的終端設(shè)備中進(jìn)行計(jì)算的。若是一個(gè)小型的互動(dòng)場景也是適用的,因?yàn)槁窋?shù)有限,收流只要把所有人都收過來,再同時(shí)進(jìn)行計(jì)算就可以。如果是在達(dá)到50人左右的小型的活動(dòng)上,一個(gè)手機(jī)就忙不過來了。首先從場景上考慮,比如很多游戲的互動(dòng)場景,本身就是有服務(wù)器的位置同步的功能,例如打MOBA游戲,沒有位置同步就不知道往哪發(fā)招。
當(dāng)有這樣的能力后,其實(shí)只需要把空間音頻的計(jì)算加進(jìn)去,位置同步的功能其實(shí)本身就自帶。在此情況下,位置同步信息已經(jīng)由服務(wù)器完成,本地只需要計(jì)算空間音頻的部分,不需要做同步,這樣流量也會(huì)減小。這個(gè)情況下就可以進(jìn)行小型活動(dòng),把位置同步放到服務(wù)器上,把本地的空間音頻渲染放在端上。
但即使端上能操作渲染,配置稍好的手機(jī)也就只能跑到50路左右,再往上就會(huì)聽到卡頓了,計(jì)算不過來了。在大規(guī)模的線下會(huì)展上,包括演唱會(huì)的場景下,就需要在服務(wù)器上完成空間音頻的位置同步和空間音頻渲染。這樣在服務(wù)器上把所有的流同時(shí)進(jìn)行渲染之后,最后發(fā)到遠(yuǎn)端時(shí),可以進(jìn)行混音,只需要在接收端去接收一路雙聲道的信號,就能夠感受空間音頻。從這個(gè)方案其實(shí)是增加了服務(wù)器的loading,但它有兩個(gè)好處。一個(gè)好處是它能夠支持更多同步的空間音頻計(jì)算的能力。另一個(gè)就發(fā)流而言,在接收端只需要接受一路流,流量也會(huì)減少很多。如果是同時(shí)接收100路流,那對于接收端的接受能力也會(huì)有很大的挑戰(zhàn)。
從空間音頻的部署上來說,根據(jù)它的規(guī)模和并發(fā)數(shù),可以找最合適、最經(jīng)濟(jì)的方案。大家都想往端上放,服務(wù)器loading就可以小一些,但實(shí)際上,端上目前而言能支持到50路就差不多了。
3、空間音頻實(shí)時(shí)渲染在游戲、社交等行業(yè)中的應(yīng)用

講完了算法部署的整個(gè)流程,我們再看看空間音頻實(shí)時(shí)渲染在游戲、社交的行業(yè)有哪些應(yīng)用。

有些空間音頻會(huì)起到增強(qiáng)的效果,有些會(huì)重構(gòu)行業(yè)的“新玩法”。就增強(qiáng)而言,互動(dòng)播客也好,或者虛擬活動(dòng),這些都會(huì)起到增強(qiáng)的作用。例如受疫情影響,現(xiàn)在有很多的虛擬會(huì)場、線上的展會(huì),有很好的3D的展示效果,它只是把空間音頻放上去,讓人有種在會(huì)場里走來走去、親切交流的感覺,就會(huì)起到增強(qiáng)的作用。包括線上的教育等,如樂隊(duì)的排練,音樂的教學(xué),會(huì)需要不同的方位,典型的例如樂隊(duì)的形式,需要中間有主唱、左邊一個(gè)吉他手、右邊一個(gè)貝斯手,這種需要不同位置的渲染,它是增強(qiáng)的效果。
而例如虛擬演唱會(huì)、Metaverse 這樣的場景,就是一個(gè)重構(gòu)式的變化。
當(dāng)有了空間感之后,結(jié)合頭戴式設(shè)備,頭動(dòng)、身體轉(zhuǎn)動(dòng)的時(shí)候,也會(huì)有一個(gè)空間音頻的實(shí)時(shí)渲染。以及人在位置變化的時(shí)候,可以實(shí)現(xiàn)音頻跟隨,就整體的效果而言是完全不一樣的,比如營造快速移動(dòng)產(chǎn)生多普勒效應(yīng)、很多像類似這樣的應(yīng)用會(huì)有新的玩法,是之前無法感受到的。
這個(gè)行業(yè)里面也讓人意想不到的應(yīng)用,包括虛擬房地產(chǎn),如NFT房地產(chǎn),它會(huì)有一個(gè)虛擬的空間,有整個(gè)聲場的虛擬環(huán)境,完全可以作為一個(gè)產(chǎn)品進(jìn)行販?zhǔn)邸?/p>
另外一塊例如流媒體的服務(wù),現(xiàn)在很多賽事或是電影,觀眾去觀看時(shí)它本身會(huì)有 immersive音頻的格式,在遠(yuǎn)端體驗(yàn)的時(shí)候就需要做空間音頻的渲染,才能體驗(yàn)出immersive音頻格式 的能力。無論是帶上耳機(jī)去聽,還是用5.1聲道的家庭影院設(shè)備,都可以把這個(gè)能力釋放出來。

除了行業(yè)上的應(yīng)用,還可以有多種新的玩法。例如像虛擬環(huán)繞聲,現(xiàn)有一些的音源,無論是立體聲、MP3格式或是無損格式,都是立體聲聲音,我們可以通過重構(gòu)這些聲音,轉(zhuǎn)換成一個(gè)環(huán)繞聲,使空間感更強(qiáng)。
類似的虛擬環(huán)繞聲能夠把雙聲道變成環(huán)繞聲,例如5.1、7.1或者是更多聲道的環(huán)繞聲的體驗(yàn),這樣對音樂的聽感或者環(huán)繞聲聽感都能有比較好的提升。這是基于現(xiàn)有的,但如果是基于例如杜比的Atmos做的話,本身就是環(huán)繞聲,會(huì)有更好的播放效果。
除此之外如果需要在音樂里有更好的聽感,例如使用Ambisonic的麥克風(fēng),可以把整個(gè)聲場錄下來。如果只有一個(gè)單聲道的麥克風(fēng)錄音,在回聽的時(shí)候還是一個(gè)單聲道。如果把整個(gè)聲場錄下來,就可以在整個(gè)聲場里走動(dòng),也可以在整個(gè)聲場里進(jìn)行觀看。整體而言,無論是交互式的電影還是交互式的現(xiàn)場,都能進(jìn)行整個(gè)聲場的采集和回放。
基于Ambisonic技術(shù)的麥克風(fēng)其實(shí)在廣播電臺(tái)已經(jīng)有很多的應(yīng)用,而線下的RTC場景還是有很多新的體驗(yàn)可以去嘗試。

我今天分享的內(nèi)容總結(jié)在這張圖里。我們再展望一下還有哪些更多的空間音頻的探索領(lǐng)域。其實(shí)要展現(xiàn)更逼真的臨場感,還有很多新的玩法和新的功能,例如近場的HRTF,貼著人的耳朵說話,類似ASMR的模擬。另外有很多聲音,不一定是點(diǎn)狀,它可以是一個(gè)瀑布,或者是一個(gè)“下雨天”。很多聲音是體積聲,有比較大的聲場,體積聲的渲染也會(huì)對沉浸感有比較大的提升。
剛才我們提到沉浸式的虛擬世界,其實(shí)每一個(gè)人都是虛擬世界制作者。你本人就是一個(gè)導(dǎo)演,或者是在進(jìn)行比賽,無論是電競也好,還是真實(shí)的場景觀看也好,這些都可以通過空間音頻把整個(gè)聲場錄下來,然后再回放,就可以實(shí)現(xiàn)交互式的電影。人在整個(gè)聲場里面走動(dòng)觀察每一個(gè)細(xì)節(jié),都會(huì)有很好的沉浸式體驗(yàn)。
同時(shí)空間音頻的編碼還有很多可以深究的地方。如何更好地去進(jìn)行空間音頻的分發(fā),尤其是在實(shí)時(shí)領(lǐng)域還要滿足低延遲和低算力的編解碼成本,這也是比較好的探索方向。
另外在Metaverse會(huì)有新的 AR和VR的交互式。例如在一個(gè)VR的空間里面,我們可能需要瞬移代替走路來解決頭暈?zāi)垦5母杏X。那么瞬移的場景下如何進(jìn)行交互,這些都是可以跟空間音頻結(jié)合的。可能在未來的元宇宙世界里,個(gè)體可能不是簡簡單單的一個(gè)人,可能是一個(gè)超人、是蜘蛛俠的角色,類似的場景都是可以有更多新的交互式的體驗(yàn)。

我今天的分享就到這里,謝謝大家。
本文為澎湃號作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場,澎湃新聞僅提供信息發(fā)布平臺(tái)。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

