- +1
2022年中國數智融合發展洞察
原創 艾瑞 艾瑞咨詢
數智融合丨研究洞察
核心摘要:
VUCA時代,市場變化加速。企業需要更加敏捷而準確的數智化決策,這些決策應當是分鐘級的而非天級的,應當是基于全量數據的而非局部數據的,應當是基于準確數據的而非基于“臟數據”的,應當是業務人員和數據分析人員任意發起的而非是通過復雜流程和多部門配合才能實現的。
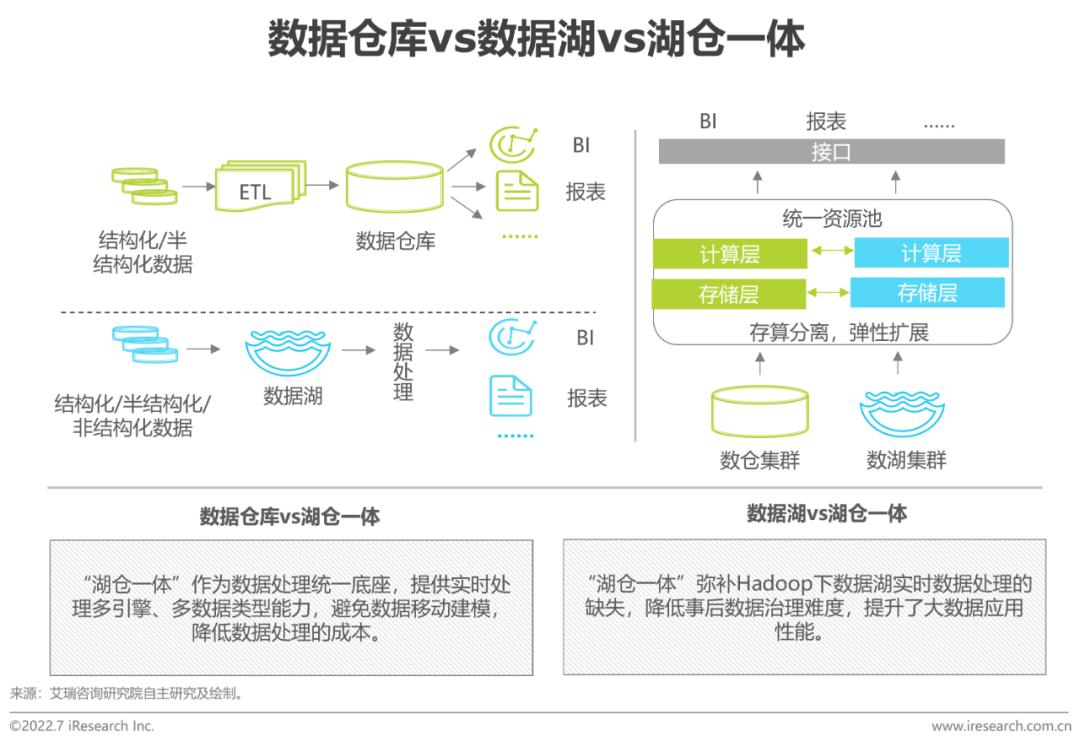
傳統的數倉或者湖倉分離架構讓數智融合和企業敏捷決策變得困難:數據孤島存在,決策無法基于全量數據;數據來回流轉,成本高、周期長、時效差。基于存儲-緩存-計算分離,湖-倉-AI數據統一元數據管理的Serverless,可在數據量、成本、效率、敏捷方面取得最優解。
開源為數智生態貢獻重要力量,但這不預示所有企業需通過開源產品自建數智平臺。實際上,大多企業聚焦自己核心業務,選擇性能穩定、無須運維、數智融合、端到端自動化與智能化的商業化數智平臺,ROI會更高。當然,平臺應與主流開源產品具有良好繼承性,如此,更加靈活開放,企業的IT人才補給成本也更低。

數據量和非結構化數據占比上升
統一管理,統一查詢使用,成為新的挑戰
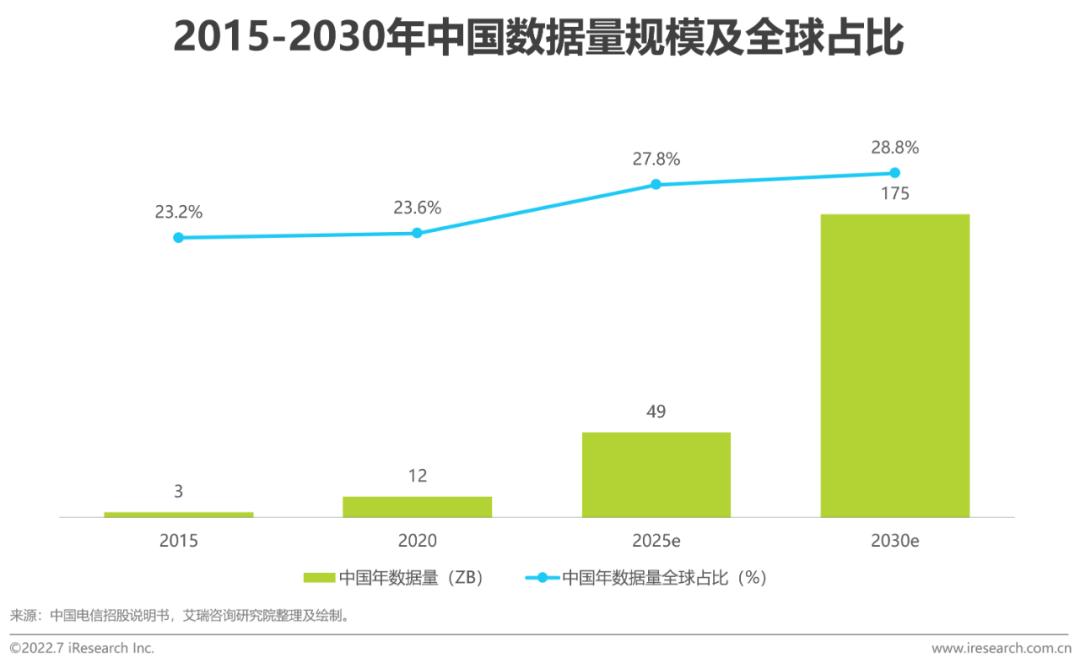
全球數據量以59%以上的年增長率快速增長,其中80%是非結構化和半結構化數據,中國數據量的上升較全球更為迅速。數據量和非結構化數據的上升,使得基于對象存儲的數據湖越來越為普及。此時,如何使用統一管理,統一查詢使用,成為新的挑戰。

數據多源異構成為常態
數據從“匯聚才可被用”到“鏈接即可被用”
在傳統數倉中,多源數據經ETL過程并集中入倉,方可被使用。該方式有許多不足:第一,因有復雜的ETL過程及大量數據的傳輸,數據實時性難以保障,因此分析常必須T+1才可完成;第二,數據的全量存儲和存儲成本之間難以取舍,因此必須提前抉擇保留哪些數據,隨著數據種類的逐漸增多,這很難做到;第三,對于異常值的下鉆、回溯等,無法回溯到最為原始的數據。隨著應用場景的增多,數據庫的種類也逐漸豐富,如更適應物聯網場景的時序數據庫、更適應知識譜圖應用的圖數據庫,等等。
綜上,多源異構、分布存儲、現用現傳、統一查詢與應用的架構,逐漸被敏捷型企業認可。
大數據的5V價值有待進一步釋放
可從平臺性工具入手,進而解決思維和技能的問題
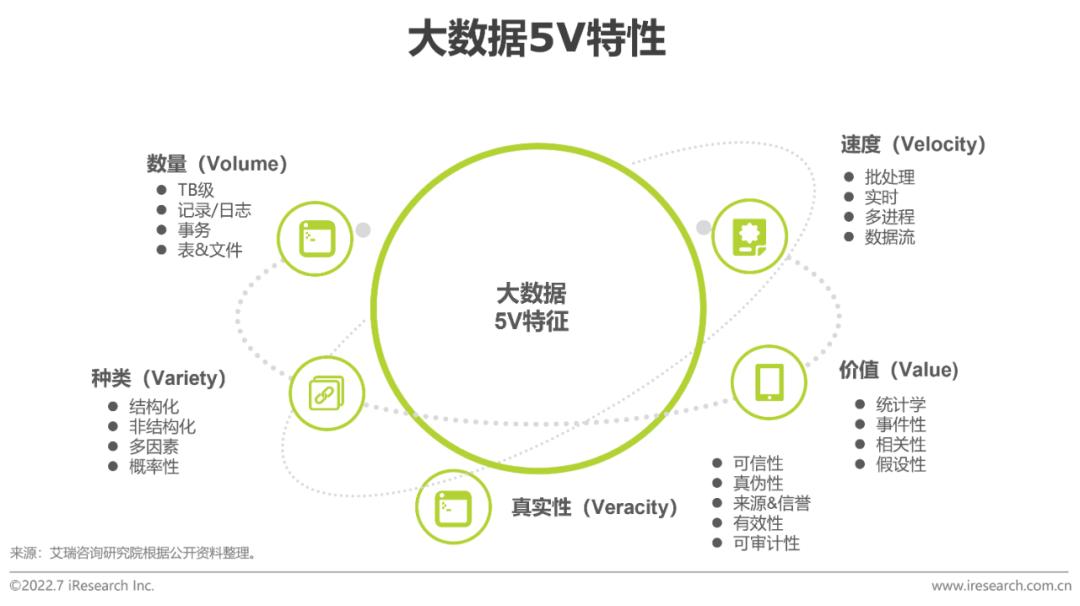
大數據產業作為以數據生成、采集、存儲、加工、分析、服務為主的戰略性新興產業,提供全鏈條技術、工具和平臺,孕育數據要素市場主體,深度參與數據要素全生命周期活動,是激活數據要素潛能的關鍵支撐,是數據要素市場培育的重要內容。目前,大數據產業仍存在數據壁壘突出、碎片化問題嚴重等瓶頸約束,大數據容量大、類型多、速度快、精度準、價值高的5V特性未能得到充分釋放。這其中既有思維、技能的要素,又有工具的要素,三者也并非割裂存在,一般來說,性能穩定、簡單易用的全鏈條平臺工具有助于消除思維的“不敢”和技能的“不會”,化解掉5V特性釋放的原始阻力,使得大數據更加普適化。
云原生:從微服務走向Serverless
從PaaS到FaaS,基礎設施被更深層次地托管和“屏蔽”
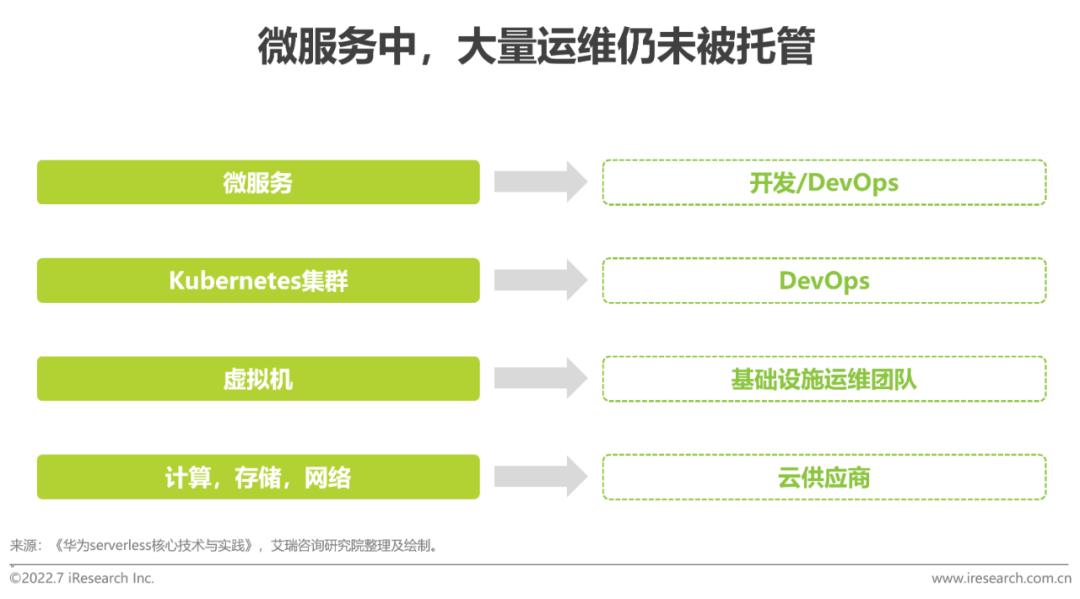
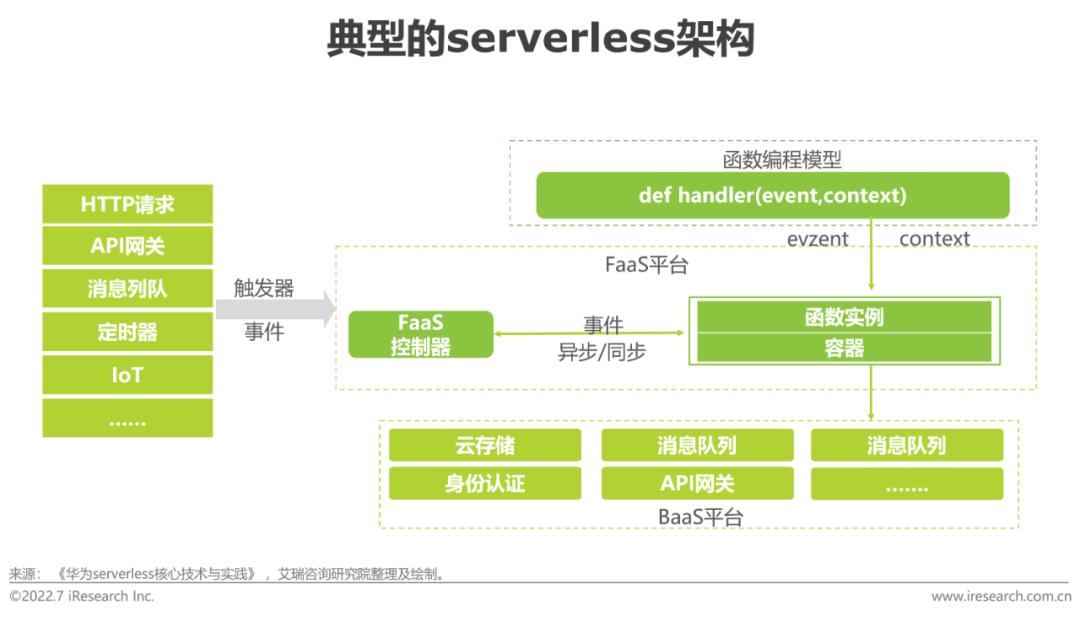
當前,微服務的生態和實踐已經比較成熟,其設計方法、開發框架、CI/CD工具、基礎設施管理工具等,都可以幫助企業順利實施,然而其仍有許多不足:(1)粒度仍然比較大。(2)開發仍有較高門檻。(3)微服務基礎設施管理、高可用和彈性仍然很難保證。(4)基礎設施的成本依然較高。而Serverless中,開發者不再需要將時間和資源花費在服務器調配、維護、更新、擴展和容量規劃上,這些任務都由平臺處理,開發者只需要專注于編寫應用程序的業務邏輯。如果再結合低零代碼,則 “編寫應用程序”的難度也大為降低,企業內的技術人員更加貼近業務。
人工智能:需要大規模準確數據哺育
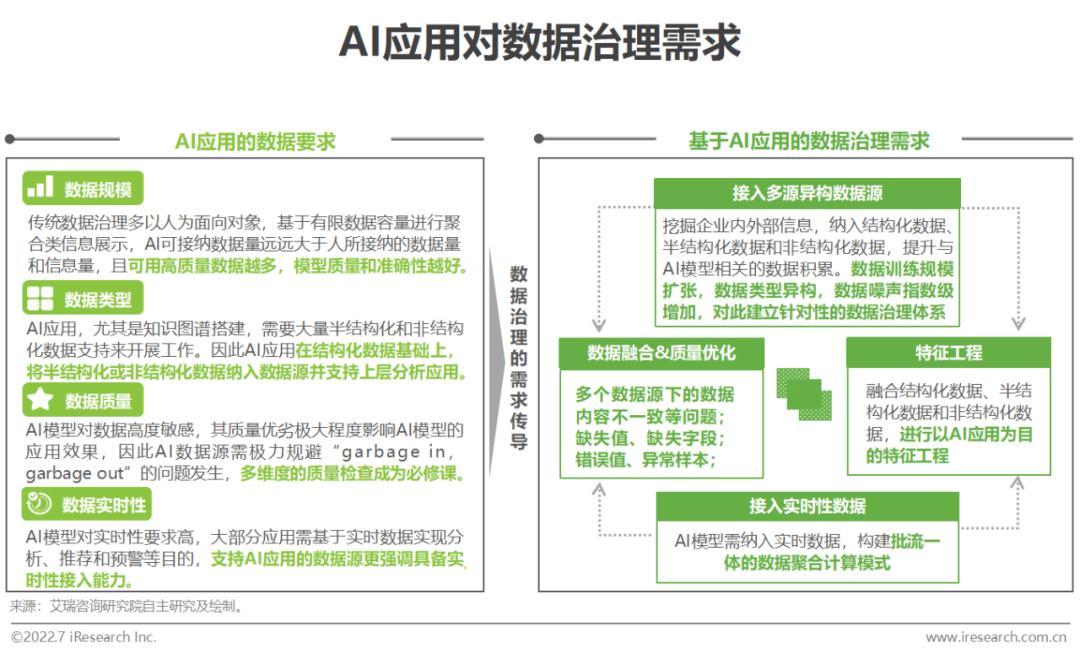
人工智能應用引發數據治理需求
企業在部署AI應用時,數據資源的優劣極大程度決定了AI應用的落地效果。因此,為推進AI應用的高質量落地,開展針對性的數據治理工作為首要且必要的環節。而對于企業本身已搭建的傳統數據治理體系,目前多停留在對于結構性數據的治理優化,在數據質量、數據字段豐富度、數據分布和數據實時性等維度尚難滿足AI應用對數據的高質量要求。為保證AI應用的高質效落地,企業仍需進行面向人工智能應用的二次數據治理工作。
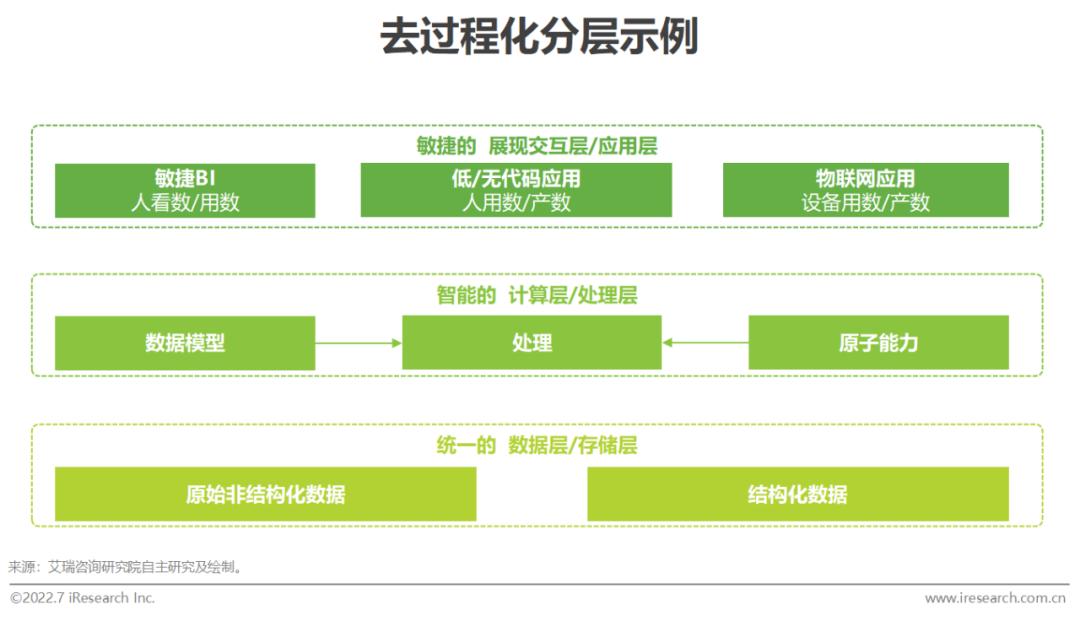
業務敏捷需要IT架構“去過程化”
通過抽象解耦、水平擴展、自動化與智能化實現去過程化
VUCA時代,市場變化加速,通過數據來分析和決策的需求,也有了更高的不確定性。當這些需求提出,通過一套復雜的IT流程和漫長的等待,變得不再現實,IT架構的去過程化變得極為重要。去過程化是指減少或完全去掉原始數據/原子能力與業務需求之間的中間數據/步驟,或使中間數據/步驟無須人為干預,自動化、智能化完成。其可實現架構的簡單化、扁平化,同時可對業務需求實時響應,以進一步實現敏捷和創新。架構一開始就放棄“精細梳理方可使用”以及“梳理完成千萬別動”思想 ,用全量原始數據保障讀時模式,有助于打破“僵”與“亂”的悖論,使得企業用更少的“能量” 便可以維持數字化系統的持續運行。



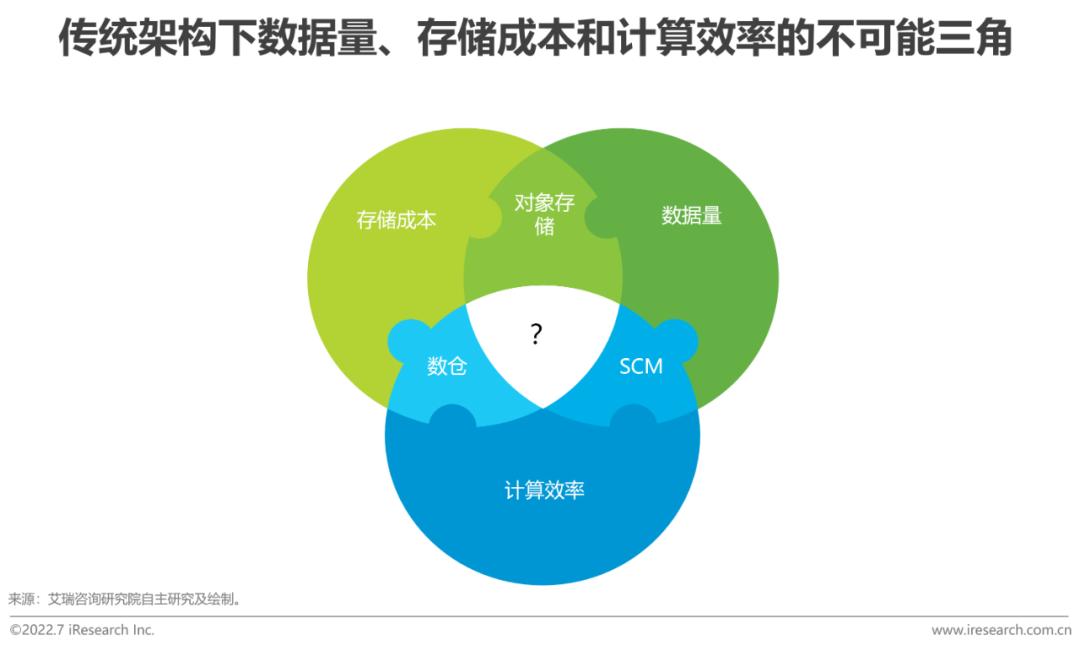
痛點一:數據量-成本-效率難以兼得
不可能三角需要更高維的技術去打破
在傳統架構中,數據量、存儲成本和計算效率是一組不可能三角。如果不考慮數據量和數據類型,那么一個傳統的數倉或者單體的DBMS即可滿足;不考慮計算效率,那么基于HDFS或者公有云對象存儲即可滿足,當下價格僅約0.1元/G/月,并持續下降,歸檔存儲等價格更低;不考慮存儲成本,可使用非易失性存儲,其擁有一般硬盤的無限容量和斷電保護特性,卻有接近于內存的性能。
應對一:存儲-緩存-計算三層分離
以內存為中心的架構,在大數據量下降低成本、保持性能
為了使數據充分共享,降低均攤成本且打破數據孤島,存算分離架構產生,存儲和計算各自彈性伸縮,按需使用。但此時,因存儲拉遠,IO成為瓶頸,性能有所下降,因此需要緩存層來存儲高IO的熱數據,并最終形成以內存為中心的架構。
從必要性看,以計算為中心架構已經無法適應當前數據生態發展:數據方面,大數據、人工智能等以數據為中心的工作負載快速發展;云方面,數據湖存算分離架構存儲訪問性能低,不支持實時分析。從可行性看,介質、網絡、協議的高速發展驅動架構轉型:SCM填補了內存縱向擴展的介質空白;緩存一致性標準的爭奪進入白熱化;高速內存直連協議及技術(如華為1520,InfiniBand,Converged Ethernet)使得內存的遠程直接訪問不再是障礙。


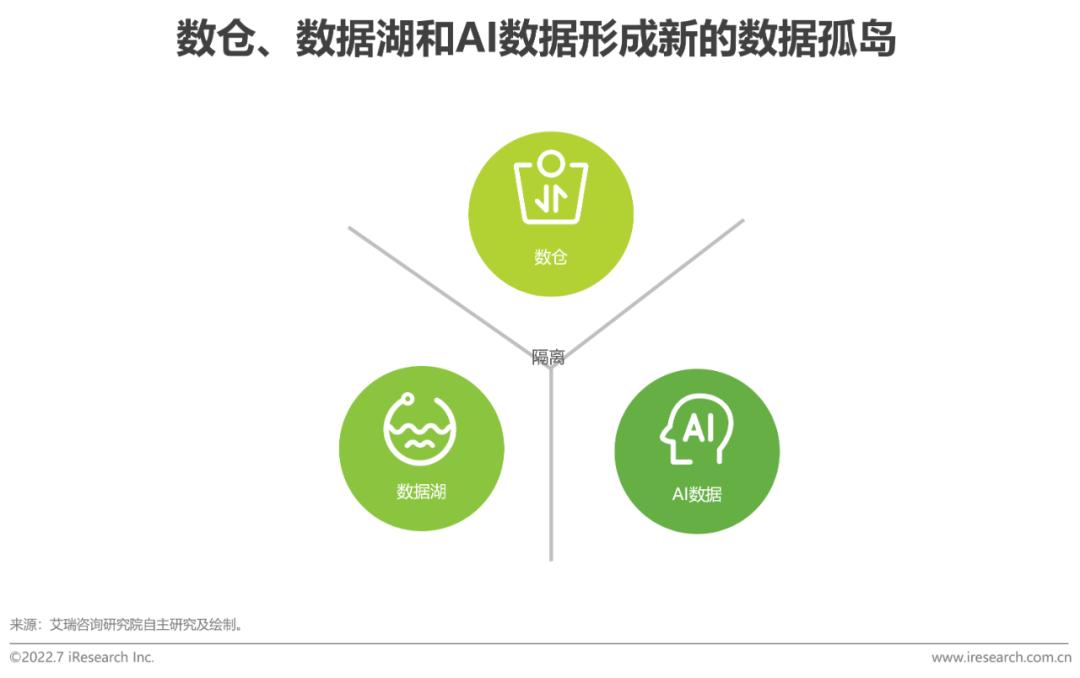
痛點二:倉-湖-AI數據形成新孤島
要么隔離,要么遷移,均無法適應全量、敏捷、低成本需求
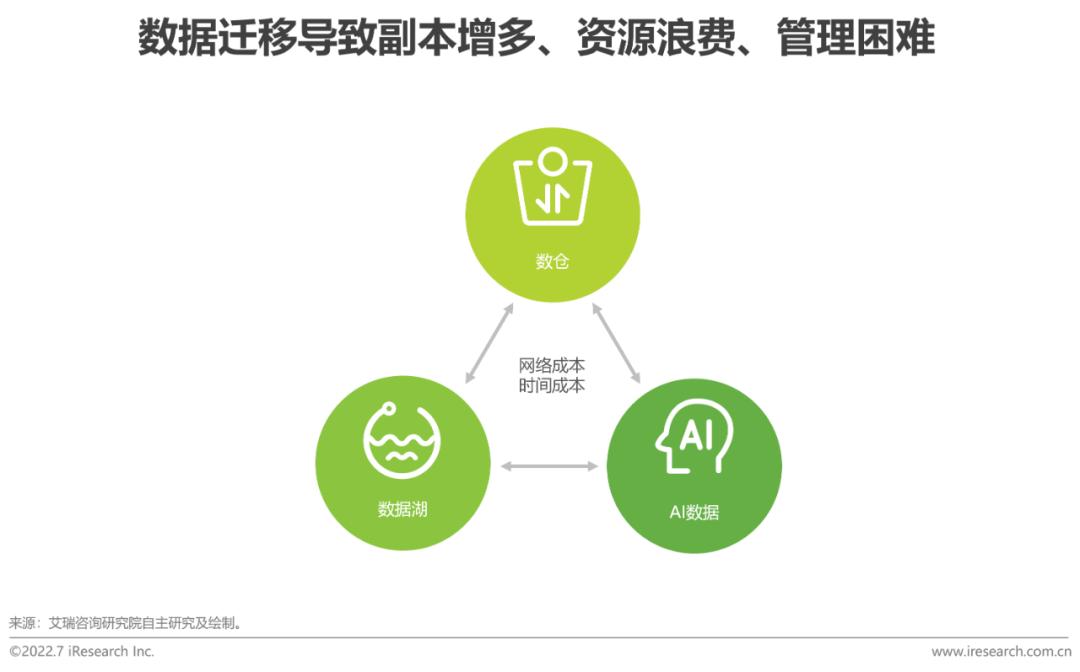
數據分析和AI分析經過多年的發展,出現了很多面向不同任務的專用數據系統:數倉系統處理結構化數據,規模不夠大;基于對象存儲的大數據系統處理海量數據和非結構化數據;AI系統一般是數據存儲在本地。這些專用系統要么無法打通,形成新的數據孤島,要么不同業務的開發要遷移數據,耗費存儲和網絡資源,數據準備慢、等待周期長,且面臨后期數據不一致的風險,發現異常時數據的下鉆、溯源等也相對困難,無法適應市場環境快速變化下敏捷數據分析的需求。
應對二:統一元數據到中心節點
Master-Slave架構,以集中管理代替集中存儲
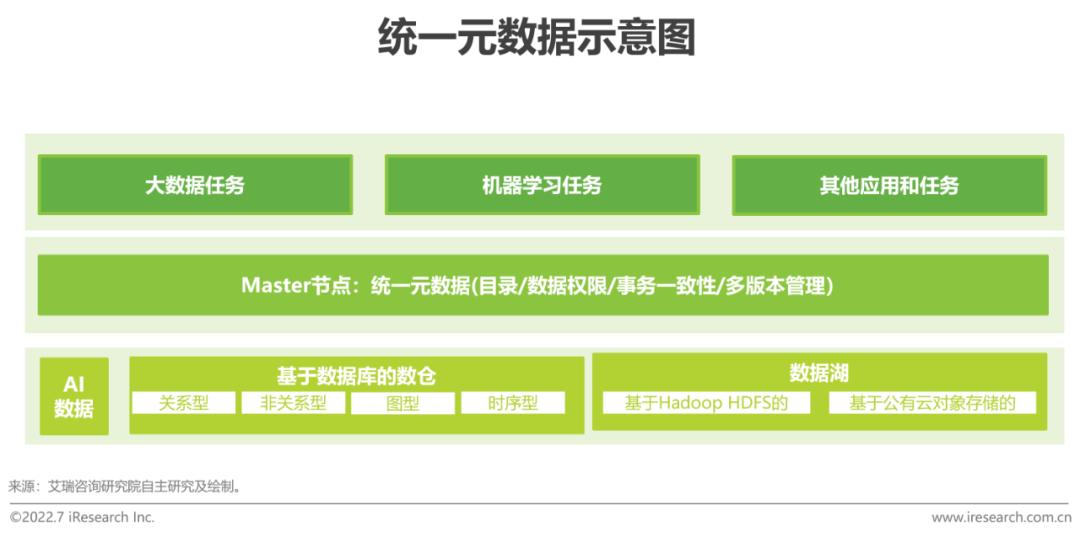
把數倉、數據湖、AI數據的目錄、數據權限、事務一致性、多版本管理等能力都統一到一個中心點,依賴于這個中心點來訪問數據,這樣數據的利用就不會被孤立的系統束縛。這種分布式存儲,統一管理的Master-Slave架構,類似于計算領域的Mapreduce。這種方式:首先,可以打破數據孤島、讓一份數據在多個引擎間自由共享,例如同一個表格可以被不同的分析工具做分析,既可以跑數倉任務,也可以做大數據和機器學習任務,不同的用戶角色不管用什么工具訪問數據,都有一致的權限,一致的事務控制;其次,可以避免數據來回遷移而造成資源的浪費;再次,任何環節都可以看到自己權限下的全量數據,例如ML工程師可以利用整個數據湖的數據做特征訓練;最后,所有模型均基于唯一事實來源(原始數據),避免不同團隊基于不同數據分析造成結果不一致,且一旦發現異常可以便捷地下鉆、回溯。
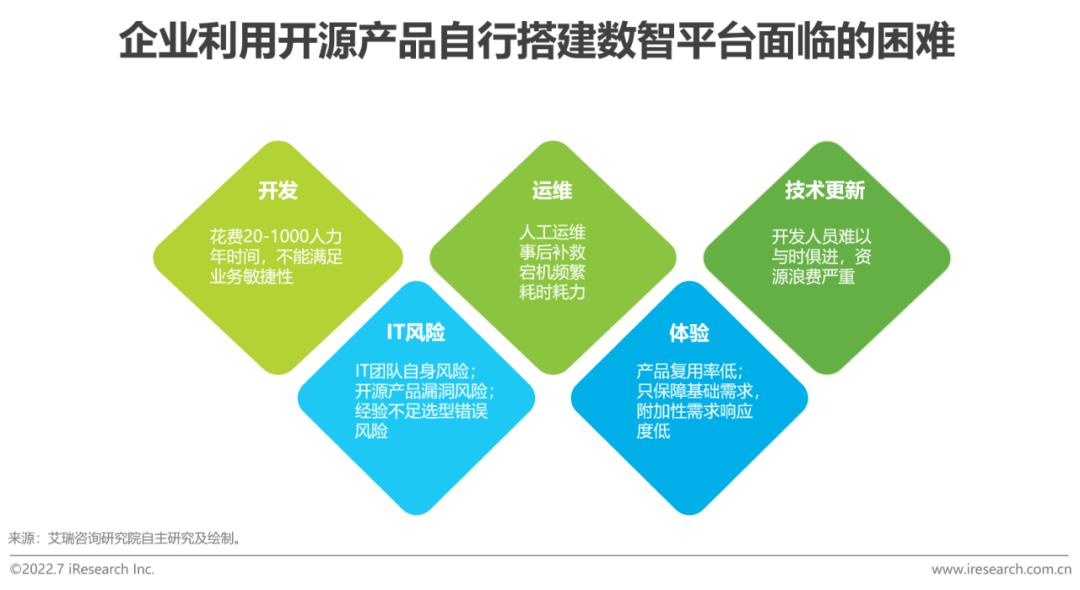
痛點三:開源產品豐富,但開發運維難
開發成本高,運維成本高,技術與時俱進難,風險大
盡管在云、數、智體系下,開源產品極為豐富,但企業安全、穩定地駕馭,TCO并不低。在開發上,企業一般需花費20-1000人力年的時間,不能滿足業務敏捷性;在運維上,人工運維,事后補救,宕機頻繁,耗時耗力;在技術更新上,開發人員難以與時俱進,資源浪費嚴重;在IT風險上,企業將面對IT團隊自身的風險(復雜架構下,團隊離職無人接手)以及開源產品的漏洞風險(如log4j4漏洞事件),還可能面對因經驗不足選型錯誤的風險;在體驗上,因產品自產自用,復用率低,技術團隊一般只保障基礎需求,對于降低業務人員使用難度、提升使用體驗的附加性需求響應度低。并且,這些基礎的開發、運維等,與企業核心業務常無必然聯系,并不會帶來企業核心競爭力的提升,導致企業數智化的ROI較低。
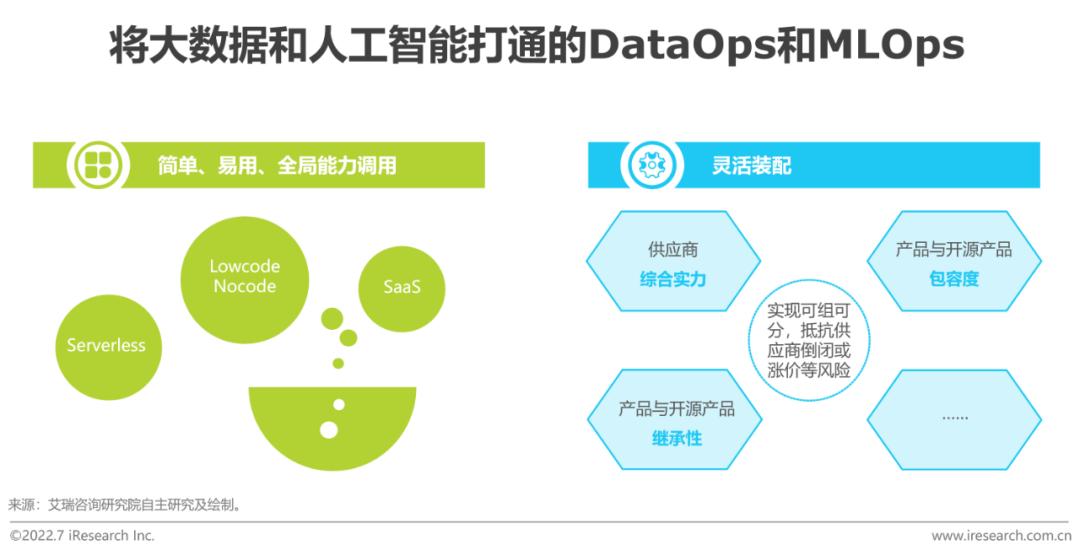
應對三:DataOps和MLOps融合
享受成熟產品的紅利,兼顧與開源產品的繼承和包容性
企業在數智化選型中,應首先明確自身的核心競爭力和能力邊界,摒棄“重即好”思想,以更加輕盈的Serverless、Lowcode/Nocode、SaaS等方式享受社會分工和先進技術的紅利。以數智融合為例,拋開IaaS層,企業自研還需掌握Kubernetes+Docker生態、Java+Hadoop生態、Python+Pytorch/Tensorflow生態、SQL生態……即便成功對接,往往也離好用、敏捷相去甚遠,最終往往只形成指標長期不變的靜態報表。而與此同時,業界已存在較為領先的一站式數智平臺,讓數據工程師甚至業務人員以簡單、熟悉的工具/語言,甚至拖拉拽即可在全域數據內使用預置AI算法,打通大數據和人工智能,使得DataOps和MLOps融合,使數據和模型的開發成本大為降低,周期大為縮短。
企業選擇基于開源產品自研,不少時候是出于一種怕被“綁架”的防御心態,以化解供應商倒閉或漲價等風險。為此,企業可從供應商綜合實力,與開源產品的包容度和繼承性等方面綜合考慮,做到可組可分,靈活裝配。
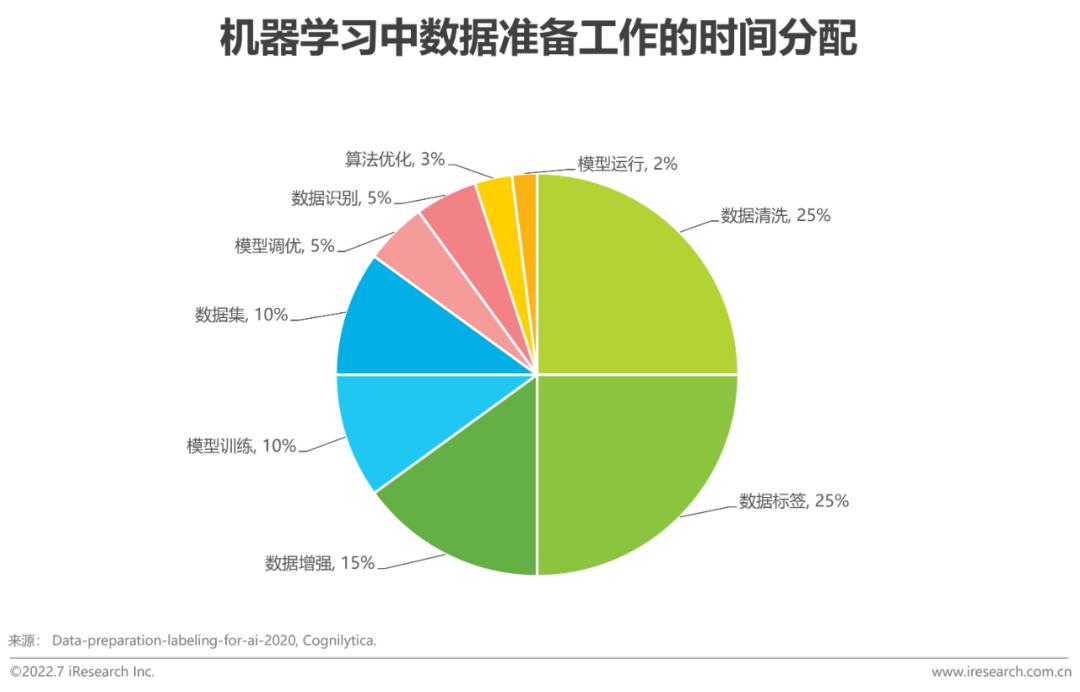
痛點四:數據準備工作復雜低效
數據長生命周期決定了其復雜性
數據質量至關重要,錯誤數據致使企業做出錯誤決策。數據的生成、采集、存儲、加工、分析、服務、安全、應用長生命周期,使得數據的準備工作復雜、低效。例如,數據工程師開發大量的ETL任務,依賴大量算力資源,運行成本高,作業管理復雜,時間周期長,而此時數據分析師和AI開發者都需要等待ETL任務執行完,才能做相應的分析工作和建模工作。Cognilytica調研顯示,機器學習中,超過80%的時間都用于數據的準備,預示著大量的數據工作其實與企業的經營目標并不相關,只是不得以而為之。并且,當任務不能便捷地執行和即時的反饋,偏業務側的數據分析師常主動放棄“不太重要的”需求和對數據的深入探索。顯然,這些都不符合企業數智化轉型的真正目標。
應對四:端到端的自動化與智能化
低零代碼實現自動化,AI反哺數據實現智能化
實現數據應用的敏捷化和去過程化,需要在整個數據鏈條的端到端實現自動化和智能化。自動化一般用低/零代碼實現:一方面可以屏蔽軟硬件差異和復雜的底層技術,以便于理解的拖拉拽和少量代碼,來降低使用門檻;另一方面,可以基于規則,配置自動化的工作流,以ifttt的方式減少重復工作量。智能化是指基于半監督或無監督的學習,自動發現數據管理中的規則,在Data4AI的同時,實現AI4Data,目前人工智能已經用于數據集成、數據質量、數據建模、數據安全與訪問控制、數據關聯、數據洞察等多個場景中。另外,低/零代碼常和人工智能結合使用:將人工智能的統計意義上的規則,融入到低/零代碼的邏輯化的流程中。

原標題:《2022年中國數智融合發展洞察》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

