- +1
詳解AI加速器(三):架構基礎離不開ISA、可重構處理器
選自 Medium
作者:Adi Fuchs
機器之心編譯
機器之心編輯部
前蘋果工程師、普林斯頓大學博士 Adi Fuchs 解釋了為什么現在是 AI 加速器的黃金時代。在這篇文章中,我們將聚焦 AI 加速器的秘密基石——指令集架構 ISA、可重構處理器等。
這是本系列博客的第三篇,我們來到了整個系列的架構基礎部分。
在這一章節中,Adi Fuchs 為我們介紹了 AI 加速器的架構基礎,包括指令集架構 ISA、特定領域的 ISA、超長指令字 (VLIW) 架構、脈動陣列、可重構處理器、數據流操作、內存處理。
指令集架構——ISA
ISA 描述了指令和操作如何由編譯器編碼,然后由處理器解碼和執行,它是處理器架構中面向程序員的部分。常見的例子是 Intel 的 x86、ARM、IBM Power、MIPS 和 RISC-V。我們可以將 ISA 視為處理器支持所有操作的詞匯表。通常,它由算術指令(如加、乘)、內存操作(加載、存儲)和控制操作(例如,在 if 語句中使用的分支)組成。
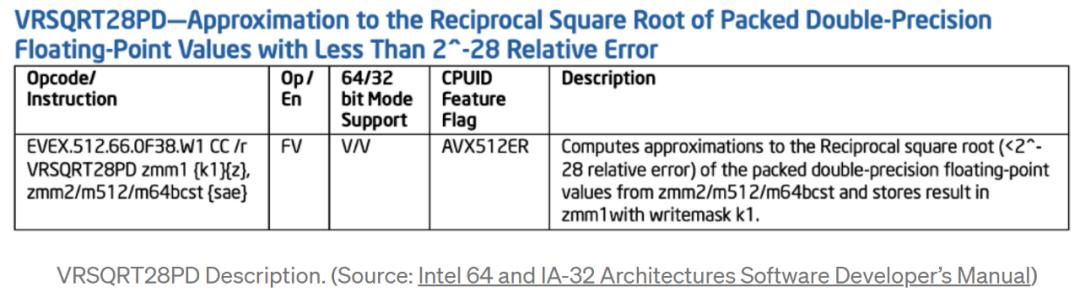
目前看來,CPU ISA 已被分類為精簡指令集計算 (RISC) 和復雜指令集計算 (CISC):
RISC ISA 由簡單的指令組成,它們支持少量簡單操作(加、乘等)。所有指令的位長相同(例如 32 位),因此,RISC 指令的硬件解碼器被認為是簡單的;
相反,在 CISC ISA 中,不同的指令可以有不同的長度,單個指令就可以描述操作和條件的復雜組合。
通常,CISC 程序比其等效的 RISC 程序代碼占用空間更小,即存儲程序指令所需的內存量。這是因為單個 CISC 指令可以跨越多個 RISC 指令,并且可變長度的 CISC 指令被編碼為使得最少的位數代表最常見的指令。然而,為了體現復雜指令帶來的優勢,編譯器需要做的足夠復雜才能實現。
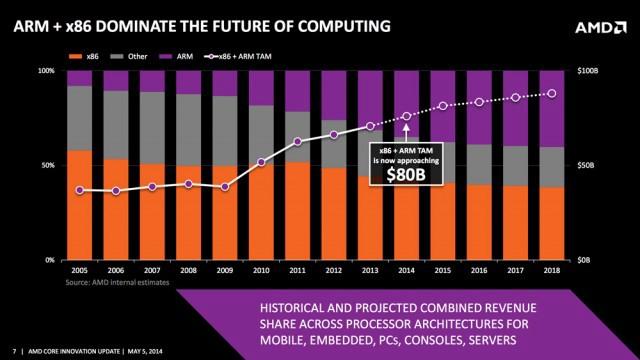
x86(橙色)相對于 ARM(紫色)的計算市場遞減率預測。圖源:AMD/ExtremeTech
早在 1980 年、1990 年和 2000 年代初期,就有「RISC 與 CISC 之戰」,基于 x86 的 Intel 和 AMD 主要專注于 CISC ,而 ARM 專注于 RISC。其實每種方法都有利弊,但最終,由于基于 ARM 的智能手機的蓬勃發展,RISC 在移動設備中占據了上風。現在,隨著亞馬遜基于 ARM 的 AWS Graviton 處理器等的發布,RISC 在云中也開始占據主導地位。
特定領域的 ISA
值得注意的是,RISC 和 CISC 都是用于構建通用處理器的通用指令集架構。但在加速器的背景下, CISC 與 RISC 相比, RISC 具有簡單性和簡潔性,更受歡迎(至少對于智能手機而言)。
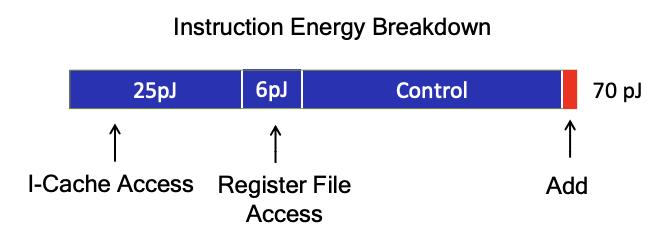
45nm CMOS 處理器中執行 ADD 指令能耗。圖源:M.Horowitz ISSCC 2014
很多 AI 加速器公司采用特定領域的 ISA。鑒于現有的精簡指令集架構(以及潛在的處理核心),可以通過僅支持目標應用領域所需的指令子集來進一步減少它。特定領域的 ISA 進一步簡化了處理內核和硬件 / 軟件接口,以實現高效的加速器設計。在通常由線性代數和非線性激活組成的 AI 應用中,不需要許多「奇異」類型的運算。因此,ISA 可以設計為支持相對較窄的操作范圍。
使用現有 RISC ISA 的簡化版本的好處是,一些 RISC 公司(如 ARM )出售現有 IP,即支持完整 ISA 的現有處理內核,可用作定制處理的基線,用于加速器芯片的核心。這樣,加速器供應商就可以依賴已經過驗證并可能部署在其他系統中的基線設計;這是從頭開始設計新架構更可靠的替代方案,對于工程資源有限、希望獲得現有處理生態系統支持或希望縮短啟動時間的初創公司尤其有吸引力。
超長指令字 (VLIW) 架構
VLIW 架構是由 Josh Fisher 在 20 世紀 80 年代早期提出,當時集成電路制造技術和高級語言編譯器技術出現了巨大的進步。其主要思想是:
將多個相互無依賴的指令封裝到一條超長的指令字中;
CPU 中有對應數量的 ALU 完成相應的指令操作;
指令之間的依賴性和調度由編譯器來完成。
就像特定領域的 ISA 可以被認為是 RISC 思想(更簡單的指令,支持的操作較少)的擴展,同樣地,我們可以將 CISC 進行多個操作組合成單個復雜指令擴展,這些架構被稱為超長指令字 (VLIW)。
VLIW 架構由算術和存儲單元的異構數據路徑陣列組成。異構性源于每個單元的時序和支持功能的差異:例如,計算簡單邏輯操作數的結果可能需要 1-2 個周期,而內存操作數可能需要數百個周期。
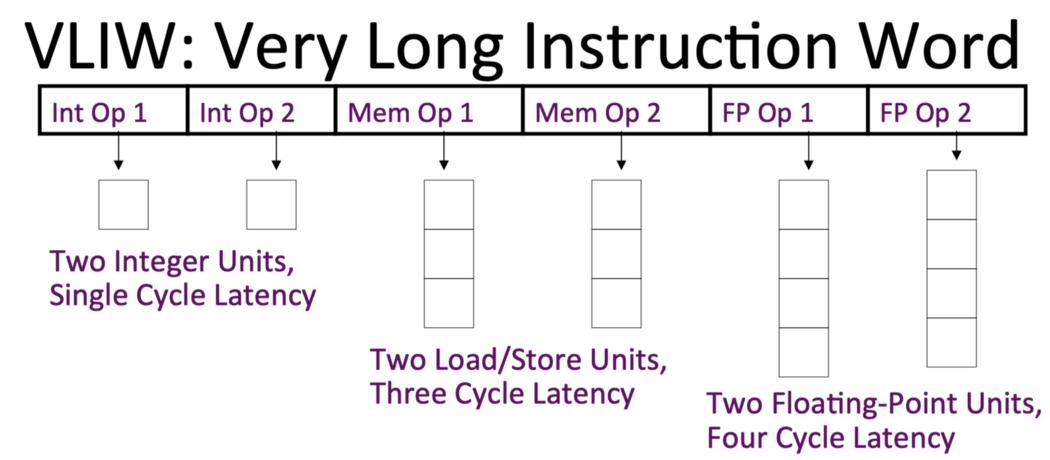
一個簡單的 VLIW 數據路徑框圖。圖源:普林斯頓大學
VLIW 架構依賴于一個編譯器,該編譯器將多個操作組合成一個單一且復雜的指令,該指令將數據分派到數據路徑陣列中的單元。例如,在 AI 加速器中,這種指令可以將張量指向矩陣乘法單元,并且并行地將數據部分發送到向量單元和轉置單元等等。
VLIW 架構的優勢在于,通過指令編排處理器數據路徑的成本可能顯著降低;缺點是我們需要保證數據路徑中各個單元之間的工作負載得到平衡,以避免資源未得到充分利用。因此,要實現高性能執行,編譯器需要能夠進行復雜的靜態調度。更具體地說,編譯器需要分析程序,將數據分配給單元,知道如何對不同的數據路徑資源計時,并以在給定時間利用最多單元的方式將代碼分解為單個指令。歸根結底,編譯器需要了解不同的數據路徑結構及其時序,并解決計算復雜的問題,以提取高指令級并行 (ILP) 并實現高性能執行。
脈動陣列
脈動陣列由 H. T. Kung 和 C. E. Leiserson 于 1978 年引入。2017 年,Google 研發的 TPU 采用脈動陣列作為計算核心結構,使其又一次火了起來。
脈動陣列本身的核心概念就是讓數據在運算單元的陣列中進行流動,減少訪存次數,并且使得結構更加規整,布線更加統一,提高頻率。整個陣列以「節拍」方式運行,每個 PE (processing elements)在每個計算周期處理一部分數據,并將其傳達給下一個互連的 PE。
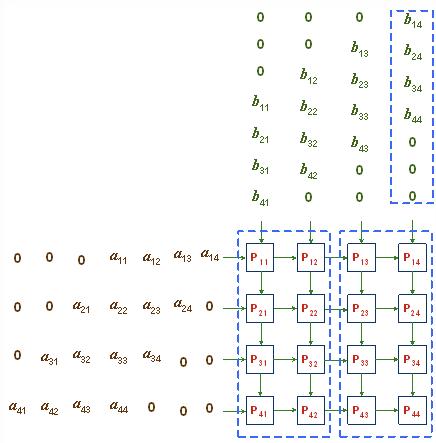
矩陣通過 4x4 脈動網。圖源:NJIT
脈動結構是執行矩陣乘法的有效方式(DNN 工作負載具有豐富的矩陣乘法)。谷歌的 TPU 是第一個使用 AI 的脈動陣列。因此,在這之后,其他公司也加入了脈動陣列行列,在自家加速硬件中集成了脈動執行單元,例如 NVIDIA 的 Tensor Core。
可重構處理器
我們所熟悉的處理器包括 CPU、GPU 和一些加速器,它們的流程依賴于預先確定數量的算術單元和運行時行為,這些行為是在運行時根據執行的程序指令確定的。但是,還有其他類別的處理器稱為「可重構處理器」。
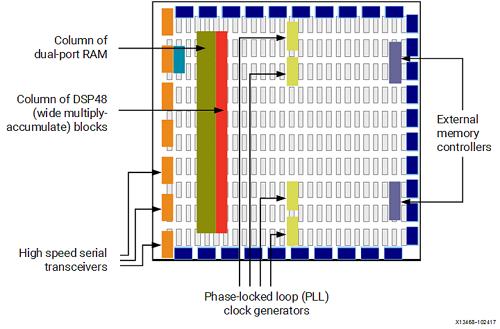
基礎 FPGA 架構。圖源:Xilinx
可重構處理器由包含互連計算單元、內存單元和控制平面的復制陣列組成。為了運行程序,專用編譯器會構建一個配置文件,這個文件包含設置數組中每個元素行為的控制位。最常見的可重構處理器類別是現場可編程門陣列 (FPGA)。
FPGA 通過啟用位級可配置性來支持廣泛的計算范圍:可以配置算術單元來實現對任意寬度數量進行操作的功能,并且可以融合片上存儲塊以構建不同大小的存儲空間。
可重構處理器的一個優點是它們可以對用硬件描述語言 (HDL) 編寫的芯片設計進行建模;這使公司能夠在幾個小時內測試他們的設計,而不是流片芯片,這個過程可能需要幾個月甚至幾年的時間。FPGA 的缺點是細粒度的位級可配置性效率低下,典型的編譯時間可能需要數小時,并且所需的額外線路數量占用大量空間,而且在能量上也是浪費。因此,FPGA 通常用于在流片之前對設計進行原型設計,因為由此產生的芯片將比其 FPGA 同類產品性能更高、效率更高。
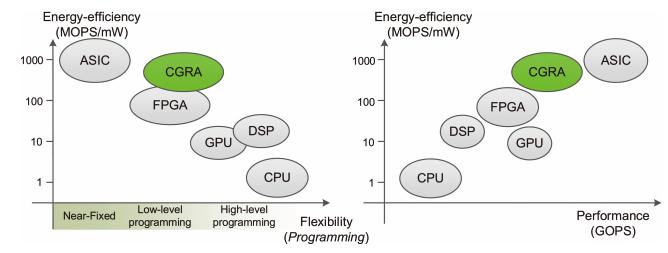
處理器架構的性能、功耗和靈活性的比較。圖源:ACM Computing Surveys
雖然 FPGA 在性能和功耗方面存在問題,但可重構性仍然是 AI 加速器一個非常理想的特性。一般來說,一個芯片的設計周期大約是 2-3 年,每天會有數不清的實驗依賴芯片運行。但是,一個近期制造完成并花費數百萬美元的芯片,往往是基于兩年多前存在的 AI 模型的假設設計的,可能與當前的模型無關。
為了將高效、性能和可重構性結合起來,一些初創公司設計了可重構處理器,它們被稱為 CGRA(Coarse-Grained Reconfigurable Arrays)。
CGRA 在 1996 年被提出,與 FPGA 相比,CGRA 不支持位級可配置性,并且通常具有更嚴格的結構和互連網絡。CGRA 具有高度的可重構性,但粒度比 FPGA 更粗。
數據流操作
數據流(Dataflow)已經有一段時間了,起源可以追溯到 1970 年代。不同于傳統的馮諾依曼模型,它們是計算的另一種形式。
在傳統的馮諾依曼模型中,程序被表示為一系列指令和臨時變量。但在數據流模型中,程序被表示為數據流圖(DFG,dataflow graph),其中輸入數據的一部分是使用預定的操作數(predetermined operands)計算的,計算機中的數據根據所表示的圖一直「流動」到輸出,這一過程由類似圖形的硬件計算而來。值得注意的是,硬件本質上是并行的。
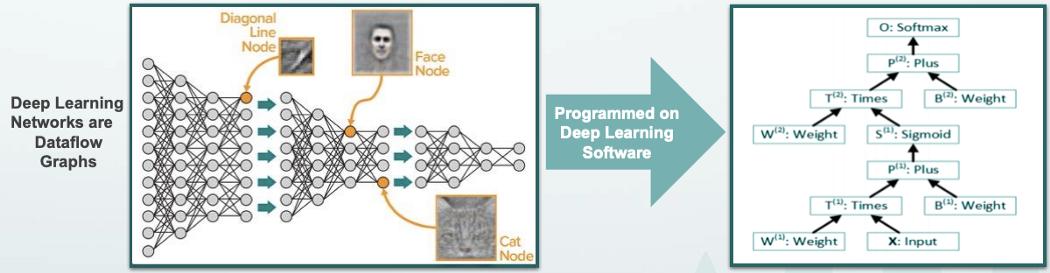
深度學習軟件到數據流圖映射的例子。圖源:Wave Computing — HotChips 2017
在 AI 加速器的背景下,執行數據流有以下兩個優勢:
深度學習應用程序是結構性的,因此有一個由應用程序層的層級結構決定的計算圖。所以,數據流圖已經被放入代碼中。相比之下,馮諾依曼應用程序首先被序列化為一系列指令,這些指令隨后需要(重新)并行化以提供給處理器;
數據流圖是計算問題的架構不可知(architecturally-agnostic)表示。它抽象出所有源于架構本身的不必要的約束(例如,指令集支持的寄存器或操作數等),并且程序的并行性僅受計算問題本身的固有并行維度的限制,而不是受計算問題本身的并行維度限制。
內存處理
研究人員在提高加速器的計算吞吐量 (FLOP) 上花費了大量精力,即芯片(或系統)每秒提供的最大計算數量。然而,片上計算吞吐量并不是全部,還有內存寬帶,因其片上計算速度超過片外內存傳輸數據的速度,造成性能瓶頸。此外,從能量角度來看, AI 模型中存在著很高的內存訪問成本,將數據移入和移出主存儲器比進行實際計算的成本高幾個數量級。
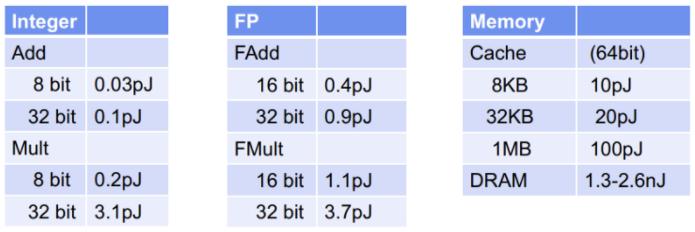
45nm CMOS 技術的典型內存和計算成本。圖源:ISSCC 2014 / M.Horowitz
AI 加速器公司為降低內存成本常采用「近數據處理,near-data processing」方法。這些公司設計了小型且高效的軟件控制存儲器(也稱為便箋存儲器,Scratchpad Memory),它們將處理過的部分數據存儲在核心芯片上,用于高速和低功耗并行處理。通過減少對片外存儲器(大而遠存儲器)的訪問次數,這種方法在減少訪問數據時間和能源成本方面邁出了第一步。
近數據處理的極端是 PIM(Processing-in-Memory),這種技術可以追溯到 1970 年代。在 PIM 系統中,主內存模塊是用數字邏輯元件(如加法器或乘法器)制造的,計算處理位于內存內部。因此,不需要將存儲的數據傳送到中間線緩沖器。商業化的 PIM 解決方案仍然不是很常見,因為制造技術和方法仍然穩定,而且設計通常被認為是僵化的。
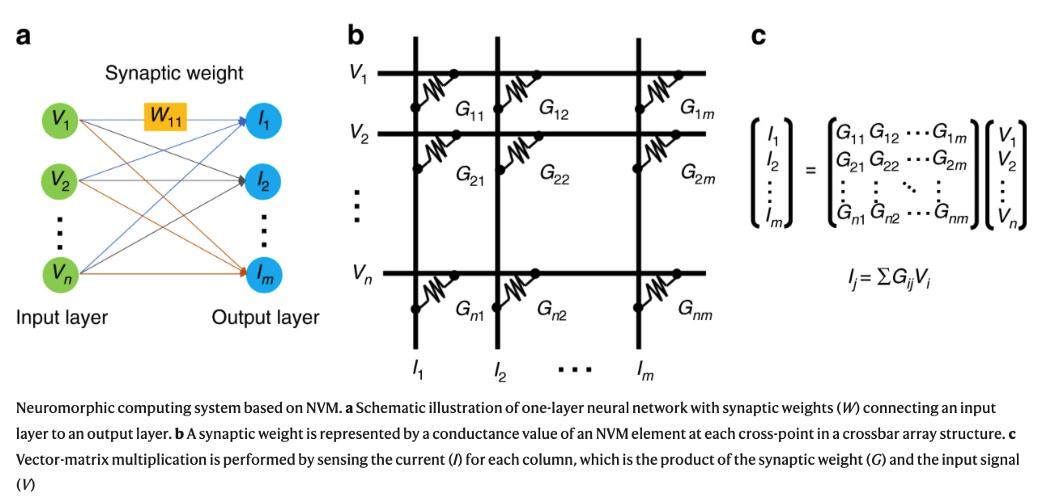
基于點積模擬處理的神經形態計算。圖源:Nature Communications
許多 PIM 依賴于模擬計算(analog computations)。具體來說,在 AI 應用中,加權點積在模擬域中的計算方式類似于大腦處理信號的方式,這就是為什么這種做法通常也被稱為「神經形態計算」的原因。由于計算是在模擬域中完成的,但輸入和輸出數據是數字的,神經形態解決方案需要特殊的模數和數模轉換器,但這些在面積和功率上的成本都很高。
相關閱讀:
原文鏈接:https://medium.com/@adi.fu7/ai-accelerators-part-iii-architectural-foundations-3f1f73d61f1f? THE END
轉載請聯系本公眾號獲得授權
投稿或尋求報道:content@jiqizhixin.com
原標題:《詳解AI加速器(三):架構基礎離不開ISA、可重構處理器……》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

