- +1
全民自動駕駛5年內真的會來嗎?這是Lyft的自動駕駛2.0
機器之心報道
編輯:杜偉、小舟
過去十年,盡管機器學習已經在圖像識別、決策制定、NLP 和圖像合成等領域取得很多成功,但卻在自動駕駛技術領域沒有太多進展。這是哪些原因造成的呢?近日,Lyft 旗下 Level 5 自動駕駛部門的研究者對這一問題進行了深入的探討。他們提出了自動駕駛領域的「Autonomy 2.0」概念:一種機器學習優先的自動駕駛方法。

論文地址:https://arxiv.org/pdf/2107.08142.pdf
自 2005 至 2007 年的 DARPA 超級挑戰賽(DARPA Grand Challenge,由美國 DARPA 部門出資贊助的無人駕駛技術大獎賽)以來,自動駕駛汽車(SDV)就已經成為了一個活躍的研究領域,并經常成為頭條新聞。許多企業都在努力開發 Level 4 SDV,有些企業已經在該領域耕耘了十多年。
已經有一些研究展示了小規模的 SDV 測試,雖然很多預測都認為「僅需要 5 年就可以迎來無處不在的 SDV 時代」,但應看到生產級的部署似乎依然遙不可及。鑒于發展進程受限,我們不可避免地會遇到一些問題,比如為什么研究社區低估了問題的困難度?當今 SDV 的發展中是否存在一些根本性的限制?
在 DARPA 挑戰賽之后,大多數業內參與者將 SDV 技術分解為 HD 地圖繪制、定位、感知、預測和規劃。隨著 ImageNet 數據庫帶來的各種突破,感知和預測部分開始主要通過機器學習(ML)來處理。但是,行為規劃和模擬很大程度上仍然基于規則,即通過人類編寫的越來越詳細的關于 SDV 應如何驅動的規則實現性能提升。一直以來有種說法,在感知非常準確的情況下,基于規則的規劃方法可能足以滿足人類水平的表現。這種方法被稱為 Autonomy 1.0。
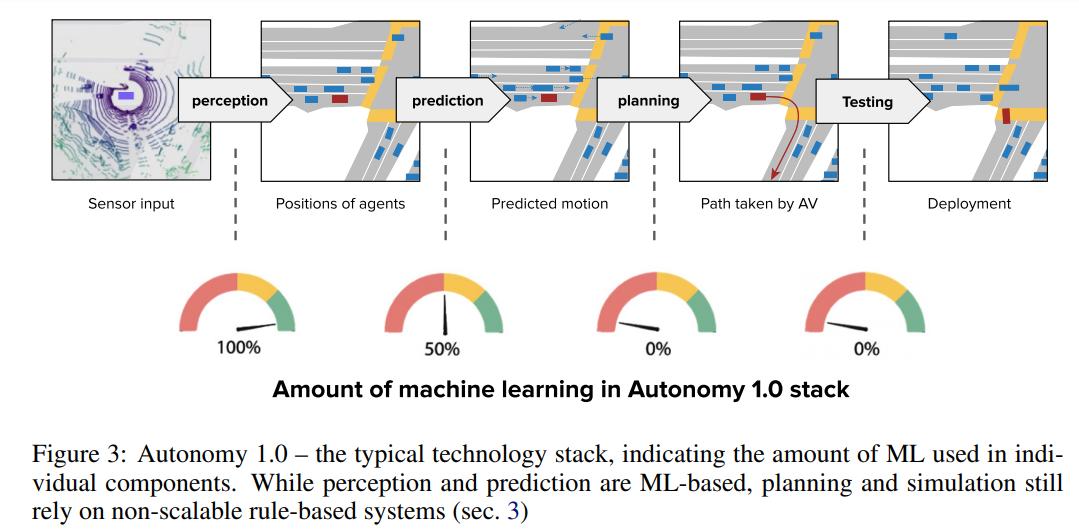
圖 3:Autonomy 1.0 的典型技術堆棧,展示了各個組件中使用到的 ML 數量。從圖中可以看到,感知和預測組件是基于 ML 的,但規劃和模擬依然依賴于非擴展、基于規則的系統。
但是,生產級的性能需要大規模地擴展以發現和妥當處理小概率事件的「長尾效應(long tail)」。研究者認為 Autonomy 1.0 無法實現這一點,原因有以下三點:
一是基于規則的規劃器和模擬器無法有效地建模駕駛行為的復雜度和多樣性,需要針對不同的地理區域進行重新調整,它們基本上沒有從深度學習技術的進展中獲得增益;
二是由于基于規則的模擬器在功效上受限,因此評估主要通過路測完成,這無疑延遲了開發周期;
三是 SDV 路測的成本高昂,且擴展性差。
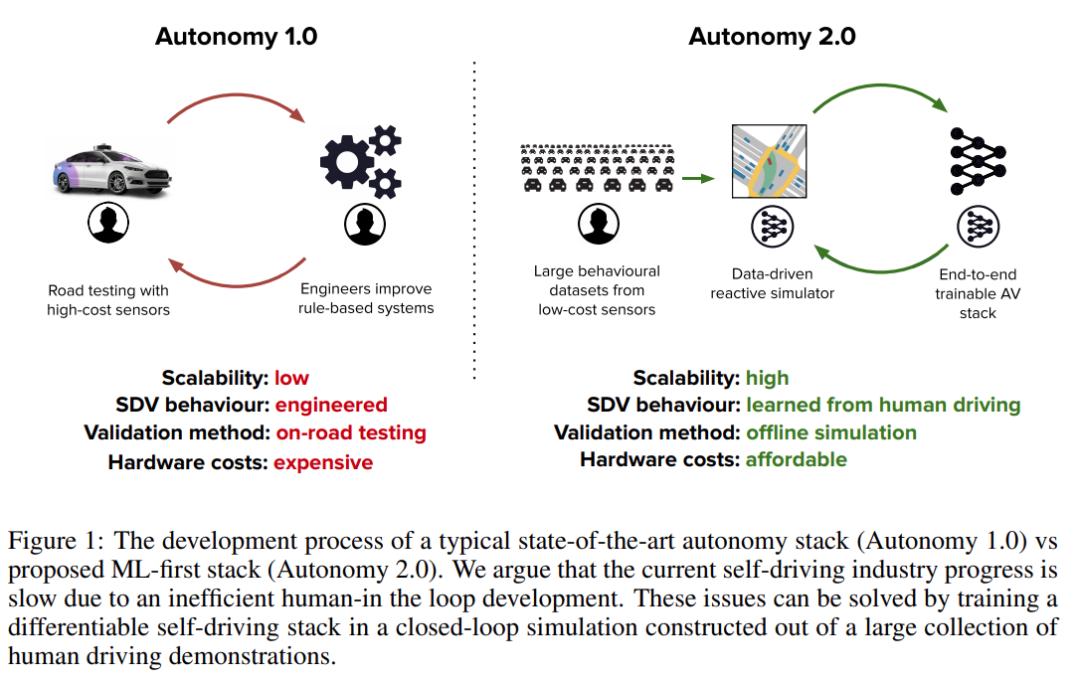
因此,針對這些擴展瓶頸,研究者提出將整個 SDV 堆棧轉變成一個 ML 系統,并且該系統可以使用包含多樣化且真實的人類駕駛數據的大規模數據集來訓練和離線驗證。他們將這個 ML 系統稱為 Autonomy 2.0,它是一個數據優先的范式:ML 將堆棧的所有組件(包括規劃和模擬)轉化為數據問題,并且通過更好的數據集而不是設計新的駕駛規則來實現性能的提升。這樣做極大地釋放了處理小概率事件長尾效應和擴展至新的地理區域所需要的擴展性,唯一需要做的是收集規模足夠大的數據集并重新訓練系統。
Autonomy 1.0 與 Autonomy 2.0 的開發流程對比,可以看到 Autonomy 1.0 的可擴展性低、SDV 行為由工程師賦予、驗證方法為路測、硬件成本高,而 Autonomy 2.0 的可擴展性高、SDV 行為從人類駕駛中學得、驗證方法為離線模擬、硬件成本在可負擔范圍內。
不過,Autonomy 2.0 也面臨著以下幾項主要挑戰:
將堆棧表示為端到端可微網絡;
在閉環中利用機器學習的模擬器進行離線驗證;
收集訓練這些模擬器需要大量人類駕駛數據。
Autonomy 2.0
Autonomy 2.0 是一種 ML 優先的自動駕駛方法,專注于實現高可擴展性。它基于三個關鍵原則:i) 閉環模擬,即模型從收集的真實駕駛日志中學習;ii) 將 SDV 分解為端到端的可微分神經網絡;iii) 訓練規劃器和模擬器所用的數據是使用商品傳感器大規模收集的。
數據驅動的閉環反應模擬
Autonomy 2.0 中的大部分評估都是在模擬中離線完成的。基于規則的模擬具有一些局限性,這與 Autonomy 1.0 對路測的依賴形成鮮明對比。但這并不意味著 Autonomy 2.0 完全放棄了路測,不過其目標在開發周期中不太突出,主要用于驗證模擬器的性能。為了使模擬成為開發道路測試的有效替代品,它需要三個屬性:
適用于任務的模擬狀態表征;
能夠以高保真度和強大的反應能力合成多樣化和逼真的駕駛場景;
應用于新的場景和地域時,性能隨著數據量的增加而提升。
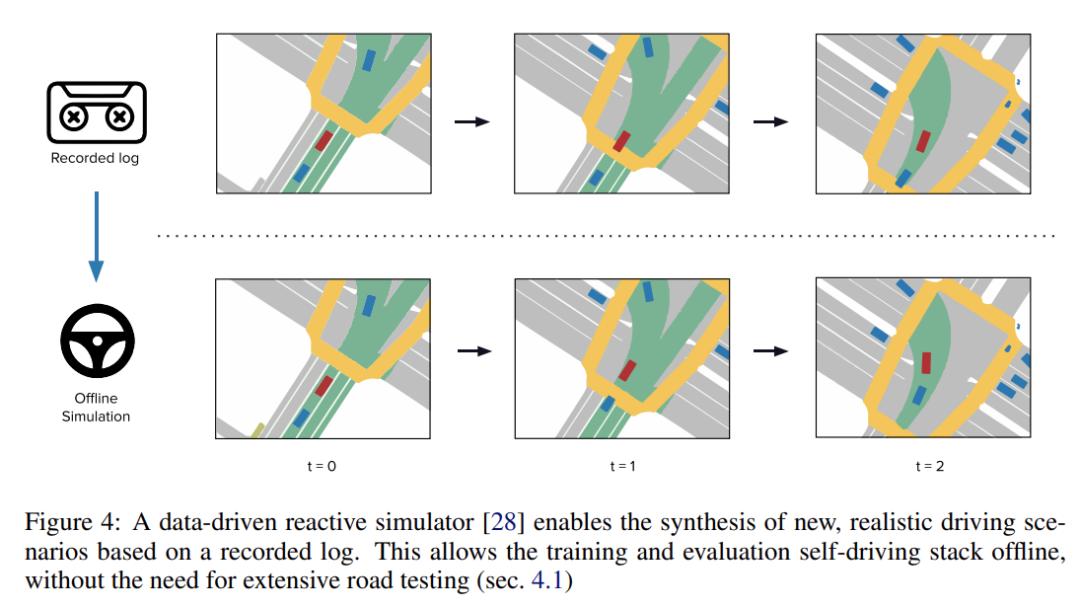
模擬結果必須非常真實,因為模擬和現實之間的任何差異都會導致性能估計不準確,但它不需要是照片般逼真的 [29],而是只關注規劃器的表示。該研究推斷,為了達到高水平的真實感,模擬本身必須直接從現實世界中學習。最近,[28] 展示了如何使用鳥瞰圖表示從先前收集的真實世界日志中構建逼真的和反應性的模擬。如圖 4 所示,然后可以部署此模擬將任何日志轉換為反應式模擬器,用于測試自動駕駛策略。
從人類演示中訓練出來的完全可微的堆棧
Autonomy 1.0 具有手工設計的基于規則的組件,以及感知、預測、規劃和模擬之間的人類可解釋接口。與 之不同,Autonomy 2.0 堆棧完全可以通過人類演示進行訓練,因此其復雜性與訓練數據量成正比。為了訓練這樣一個系統,需要滿足幾個條件:
每個組件,包括規劃,都需要可訓練且端到端的可微分;
可使用人工演示進行訓練;
性能與訓練數據量成正比。
下圖 5 是完全可微的 Autonomy 2.0 堆棧架構,可以從數據進行端到端的訓練,而無需設計單個塊和接口。其中, d、h、f 和 g 是可學習的神經網絡。d 和 h 給出了規劃發生的場景的潛在表示。f 代表 SDV 和場景中代理的策略。g 是狀態轉移函數。I_0 是網絡的輸入,而 {I_1, ··, I_3} 在訓練期間提供監督。

大規模低成本數據采集
到目前為止討論的系統使用人類演示作為訓練數據,即具有由人類駕駛員選擇的相應軌跡的傳感器數據作為監督。要解鎖生產級性能,這些數據需要具備:
足夠的規模和多樣性以包括罕見事件的長尾;
足夠的傳感器保真度,即用于收集數據的傳感器需要足夠準確才能有效地訓練規劃器和模擬器;
足夠便宜,可以以這種規模和保真度收集。
雖然最近第一個帶有人類演示的公開數據集已發布,但這些數據僅限于幾千英里的數據。觀察長尾可能需要收集數億英里的數據,因為大多數駕駛都是平安無事的,例如在美國,每百萬英里大約有 5 起撞車事故 。
應該使用哪些傳感器呢?感知算法的最新進展表明,在 KITTI 基準測試 [44] 上,高清和商用傳感器(如相機 和稀疏激光雷達 [42])之間的感知精度差距縮小了,如下表 1 所示。
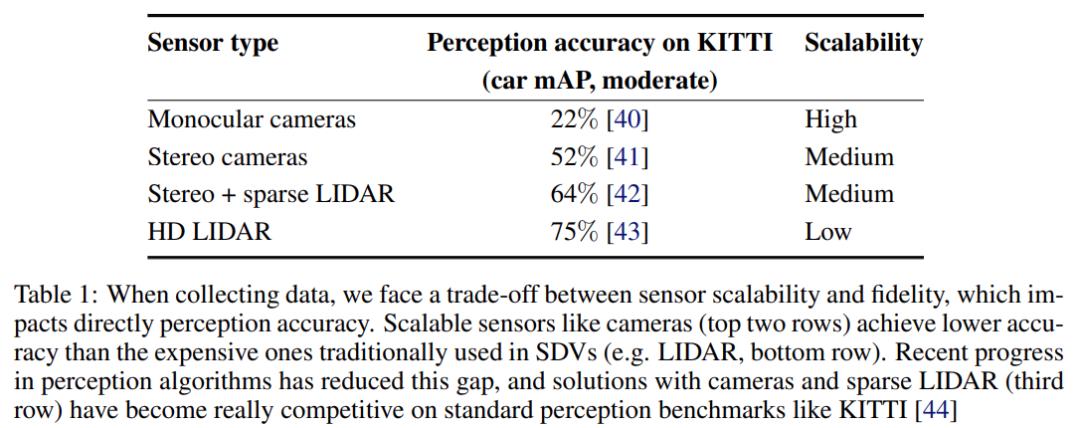
表 1:收集數據時面臨傳感器可擴展性和保真度之間的權衡,這會直接影響感知精度。
未來需要解決哪些問題
研究者概述了 Autonomy 2.0 的范式,旨在使用 ML 優先的方法解決自動駕駛問題。并且,通過消除人在回路(human-in-the-loop),這一范式的擴展性更強,這也是實現高性能自動駕駛汽車技術的主要痛點。雖然 Autonomy 2.0 范式的發展前景很好,但依然有需要解決的問題,具體如下:
模擬和規劃的恰當狀態表示是什么?我們應如何衡量場景概率?
我們應如何檢測異常值(outlier)以及從未見過的情況(case)?
與使用搜索進行的實時推理相比,通過人類演示進行離線訓練的極限在哪里?
我們需要在模擬上投入多少?又應如何衡量離線模擬本身的性能?
我們在訓練高性能規劃和模擬組件上需要多少數據?在大規模數據收集時又應該使用什么傳感器呢?
解答這些問題對于自動駕駛和其他現實世界的機器人問題至關重要,并且可以激發研究社區盡早解鎖高性能 SDV。
數據智能技術實踐論壇——從數據到知識的「智變」
8月27日15:00-17:00,百分點科技與機器之心聯合舉辦「數據智能技術實踐論壇」全程線上直播,四位業界專家與學者詳細解讀多模態數據融合治理、計算機視覺、基于知識圖譜的認知智能、知識圖譜構建等領域的技術進展和實踐心得。
演講一:融合創新——計算機視覺技術與產業化發展之道
演講二:從「治」理到「智」理,多模態數據管理PAI應用方法論
演講三:從知識圖譜到認知智能
演講四:知識圖譜技術及行業應用實踐
直播設有QA環節,歡迎加群交流答疑。
? THE END
轉載請聯系本公眾號獲得授權
投稿或尋求報道:content@jiqizhixin.com
原標題:《全民自動駕駛5年內真的會來嗎?這是Lyft的自動駕駛2.0》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

