- +1
統(tǒng)計(jì)學(xué)權(quán)威盤點(diǎn)過去50年最重要的統(tǒng)計(jì)學(xué)思想,因果推理、bootstrap等上榜

導(dǎo)語(yǔ)
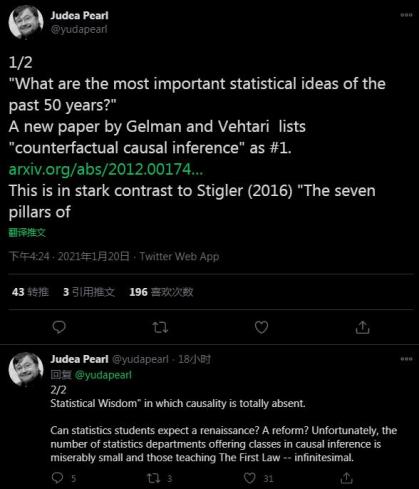
近日,圖靈獎(jiǎng)得主、“貝葉斯網(wǎng)絡(luò)之父”Judea Pearl在Twitter上分享了一篇新論文“What are the most important statistical ideas of the past 50 years?”(過去50年中最重要的統(tǒng)計(jì)思想是什么?)
這篇論文由哥倫比亞大學(xué)統(tǒng)計(jì)學(xué)教授Andrew Gelman和阿爾托大學(xué)計(jì)算機(jī)科學(xué)系副教授Aki Vehtari所著,他們根據(jù)自己的研究和文獻(xiàn)閱讀經(jīng)驗(yàn)總結(jié)出了過去半個(gè)世紀(jì)以來最重要的8個(gè)統(tǒng)計(jì)思想,并表示:“它們是獨(dú)立的概念,涵蓋了統(tǒng)計(jì)方面不同的發(fā)展。這些思想都在1970年前的理論統(tǒng)計(jì)文獻(xiàn)和各個(gè)應(yīng)用領(lǐng)域的實(shí)踐中就已經(jīng)出現(xiàn)。但是在過去的五十年中,它們各自已經(jīng)發(fā)展到足以成為新事物的程度。”
集智俱樂部聯(lián)合智源社區(qū),以因果科學(xué)和Causal AI為主題舉辦,精讀基礎(chǔ)教材、研讀重要論文,探討如何借助因果科學(xué)構(gòu)建可解釋的人工智能系統(tǒng)。詳情見文末。
陳彩嫻、Mr Bear | 作者
AI科技評(píng)論 | 來源

論文題目:
What are the most important statistical ideas of the past 50 years?
論文地址:
https://arxiv.org/pdf/2012.00174.pdf
他們認(rèn)為,過去半個(gè)世紀(jì)中最重要的統(tǒng)計(jì)思想是:反事實(shí)因果推理,基于bootstrapping(自助抽樣法)和基于模擬的推理,超參數(shù)化模型和正則化,多層模型,泛型計(jì)算算法(generic computation algorithms),自適應(yīng)決策分析,魯棒推理和探索性數(shù)據(jù)分析(未按時(shí)間順序,排序不分先后)。
在這篇論文中,他們將討論這些思想的共同特征、它們與現(xiàn)代計(jì)算和大數(shù)據(jù)的關(guān)系以及在未來幾十年中如何發(fā)展。“本文的目的是引起有關(guān)統(tǒng)計(jì)和數(shù)據(jù)科學(xué)研究更大主題的思考和討論。”
值得一提的是,Judea Pearl在推文中表示,“對(duì)作者將因果推理列入其中感到欣慰,這與Stigler在《統(tǒng)計(jì)學(xué)七支柱》中的總結(jié)截然不同,后者完全沒有提到因果推理。”另外,他也對(duì)大學(xué)統(tǒng)計(jì)專業(yè)很少安排因果推理課程感到擔(dān)憂,“統(tǒng)計(jì)學(xué)可以期待復(fù)興或改革嗎?不幸的是,統(tǒng)計(jì)系中提供因果推理課程的非常少,更不用提教'The First Law'的,簡(jiǎn)直是無(wú)窮少。”
以下是全文編譯:
1.過去50年最重要的統(tǒng)計(jì)思想
1.1 反事實(shí)因果推理
在這里,我們首先要介紹在統(tǒng)計(jì)學(xué)、計(jì)量經(jīng)濟(jì)學(xué)、心理測(cè)量、流行病學(xué)和計(jì)算機(jī)科學(xué)領(lǐng)域出現(xiàn)的一些重要思想,它們都圍繞著因果推理面臨的挑戰(zhàn)展開,并且都在某種程度上彌平了「對(duì)觀測(cè)推理的因果解釋」和「認(rèn)識(shí)到關(guān)聯(lián)關(guān)系并不意味著因果關(guān)系」這兩方面的差距。
核心的思想在于,在某些假設(shè)情況下,我們可以識(shí)別出因果關(guān)系,而且我們可以嚴(yán)謹(jǐn)?shù)芈暶鬟@些假設(shè),并且通過設(shè)計(jì)和分析以各種方式解決它們。
到目前為止,關(guān)于如何將因果模型應(yīng)用于真實(shí)數(shù)據(jù)的具體問題上的爭(zhēng)論仍在繼續(xù)。然而,在過去的五十年中,這一領(lǐng)域的工作進(jìn)展使因果推理所需要的這些假設(shè)變得精確得多,從而反過來又促進(jìn)了解決這些問題的統(tǒng)計(jì)方法的相關(guān)工作。
研究人員針對(duì)各個(gè)領(lǐng)域研發(fā)出了各種各樣的因果推理方法:在計(jì)量經(jīng)濟(jì)學(xué)領(lǐng)域中,人們主要關(guān)注對(duì)線性模型的因果估計(jì)的可解釋性;在流行病學(xué)領(lǐng)域中,人們主要關(guān)注基于觀測(cè)數(shù)據(jù)的推理;心理學(xué)家已經(jīng)意識(shí)到交互和各種處理效應(yīng)的重要性;在統(tǒng)計(jì)學(xué)領(lǐng)域中,出現(xiàn)了一系列有關(guān)匹配和其它調(diào)整并衡量實(shí)驗(yàn)組和對(duì)照組之間差別的方法;在計(jì)算機(jī)科學(xué)領(lǐng)域中,涌現(xiàn)出有關(guān)多維因果歸隱模型的研究工作。
在上述所有工作中,有一條研究主線,即從反事實(shí)或可能得到的結(jié)果的層面上對(duì)因果問題進(jìn)行建模,這相較于之前沒有明確區(qū)分描述性推理和因果推理的標(biāo)準(zhǔn)方法是一個(gè)巨大的飛躍。
在這個(gè)研究方向上,具有里程碑意義的工作包括 Neyman (1923),Welch (1937),Rubin (1974),Haavelmo (1973) 等人的研究成果,更加詳細(xì)的研究背景請(qǐng)參閱 Heckman 和 Pinto 于 2015 年發(fā)表的論文「Causal analysis after Haavelmo」。
反事實(shí)因果推理的思想和方法在統(tǒng)計(jì)學(xué)以及相關(guān)的應(yīng)用研究和策略分析領(lǐng)域都有深遠(yuǎn)影響。
1.2 bootstrap與基于模擬的推理
在過去的50年中,用計(jì)算取代數(shù)學(xué)分析是統(tǒng)計(jì)學(xué)的一大發(fā)展趨勢(shì)。這一變化甚至在「大數(shù)據(jù)」分析出現(xiàn)之前就開始了。
bootstrap是最純粹的基于計(jì)算定義的統(tǒng)計(jì)方法之一,它定義了一些估計(jì)量,并將其應(yīng)用于一組隨機(jī)重采樣數(shù)據(jù)集。其思想是將估計(jì)值視為數(shù)據(jù)的一個(gè)近似的充分統(tǒng)計(jì)量,并將自助分布視為對(duì)數(shù)據(jù)的采樣分布的近似。在概念層面上,人們推崇將預(yù)測(cè)和重新抽樣作為基本原則,可以推導(dǎo)出諸如偏差校正和收縮等統(tǒng)計(jì)學(xué)操作。
歷史上,這一方向誕生了「刀切法」和「交叉驗(yàn)證」等方法。此外,由于bootstrap思想的通用性及其簡(jiǎn)單的計(jì)算實(shí)現(xiàn)方式,bootstrap立刻被廣泛用于各種傳統(tǒng)的解析近似方法效果不佳應(yīng)用,從而產(chǎn)生了巨大的影響。時(shí)至今日,充足的計(jì)算資源也起到了幫助作用,使得對(duì)許多重采樣得到的數(shù)據(jù)集進(jìn)行反復(fù)的推理變得十分容易。
計(jì)算資源的增加也使得其它重采樣和基于模擬的方法流行了起來。在置換檢驗(yàn)中,我們通過隨機(jī)打亂排列真實(shí)值(target)來打破預(yù)測(cè)值和真實(shí)值之間的依賴關(guān)系,從而生成重采樣數(shù)據(jù)集。參數(shù)化的bootstrap、先驗(yàn)和后驗(yàn)預(yù)測(cè)檢查、基于模擬的校正都是根據(jù)模型創(chuàng)建了復(fù)制數(shù)據(jù)集,而不是直接從數(shù)據(jù)中重采樣。在分析復(fù)雜模型和算法時(shí),根據(jù)已知的數(shù)據(jù)生成機(jī)制采樣的做法往往被用于創(chuàng)建模擬實(shí)驗(yàn),用于補(bǔ)充或替代數(shù)學(xué)理論。
1.3 過參數(shù)化模型和正則化
自 20 世紀(jì) 70 年代以來,統(tǒng)計(jì)學(xué)受個(gè)方面的影響,發(fā)生了一個(gè)重大的變化,即用一些正則化過程得到穩(wěn)定的估計(jì)和良好的預(yù)測(cè)結(jié)果,從而擬合具有大量參數(shù)(有時(shí)參數(shù)比數(shù)據(jù)點(diǎn)更多)的模型。該思想旨在在避免過擬合問題的同時(shí),獲得一種非參數(shù)化的或高度參數(shù)化的方法。我們可以通過針對(duì)參數(shù)或預(yù)測(cè)曲線的懲罰函數(shù)來實(shí)現(xiàn)正則化。
早期的高度參數(shù)化的模型包括「馬爾科夫隨機(jī)場(chǎng)」、「樣條函數(shù)」、「高斯過程」,隨后又出現(xiàn)了「分類和回歸決策樹」、「神經(jīng)網(wǎng)絡(luò)」、「小波收縮」、「Lasso 和 Horseshoe 等最小二乘的替代方法」、「支持向量機(jī)及相關(guān)理論」。
上述所有模型都會(huì)隨著樣本規(guī)模的增加而擴(kuò)大,其參數(shù)往往也不能被直接解釋,它們是一個(gè)更大的預(yù)測(cè)系統(tǒng)的一部分。在貝葉斯方法中,我們可以首先在函數(shù)空間中考慮先驗(yàn),然后間接推導(dǎo)出相應(yīng)的模型參數(shù)的先驗(yàn)。
在人們能夠容易地獲得充足的計(jì)算資源之前,這些模型的使用還十分有限。此后,圖像識(shí)別、深度神經(jīng)網(wǎng)絡(luò)領(lǐng)域中的過參數(shù)化模型持續(xù)發(fā)展。Hastie、Tibshirani 以及 Wainwright 于 2015 年將許多該領(lǐng)域的工作定義為對(duì)稀疏結(jié)構(gòu)的估計(jì)。
但是在本文作者看來,正則化技術(shù)更為通用,這是因?yàn)樗钩砻艿哪P湍軌蜻m應(yīng)數(shù)據(jù)支持的程度。在統(tǒng)計(jì)學(xué)領(lǐng)域以外, 這方面也產(chǎn)出了許多成果,例如:非負(fù)矩陣分解、非線性降維、生成對(duì)抗網(wǎng)絡(luò)、自編碼器。它們都是可以尋找結(jié)構(gòu)和分解結(jié)果的無(wú)監(jiān)督學(xué)習(xí)方法。
隨著統(tǒng)計(jì)方法得到了發(fā)展,并被應(yīng)用于更大的數(shù)據(jù)集上,研究者們還研發(fā)了一些調(diào)優(yōu)、自適應(yīng),以及組合來自多個(gè)擬合結(jié)果的推理(包括 stacking 集成、貝葉斯模型平均、boosting 集成、梯度提升、隨機(jī)森林)的方法。
1.4 多層模型
多層模型的參數(shù)因組而異,它使模型可以適應(yīng)于聚類抽樣、縱向研究、時(shí)間序列橫斷面數(shù)據(jù)、元分析以及其它結(jié)構(gòu)化的環(huán)境。在回歸問題中,一個(gè)多層模型可以被看做特定參數(shù)化的協(xié)方差結(jié)構(gòu),或者是一個(gè)參數(shù)數(shù)量隨數(shù)據(jù)比例增加的概率分布。
多層模型可以被看做一種貝葉斯模型,它們包含未知潛在特征或變化參數(shù)的概率分布。反過來,貝葉斯模型也有一種多層結(jié)構(gòu),包含給定參數(shù)的數(shù)據(jù)和超參數(shù)的參數(shù)的分布。
對(duì)局部和一般信息進(jìn)行池化(pooling)的思想是根據(jù)帶有噪聲的數(shù)據(jù)進(jìn)行預(yù)測(cè)的固有數(shù)學(xué)原理。這一思想可以追溯到拉普拉斯和高斯,高爾頓也隱式地表達(dá)了這種思想。
部分池化的思想已經(jīng)被應(yīng)用于一些特定應(yīng)用領(lǐng)域(例如:動(dòng)物育種)。部分池化與統(tǒng)計(jì)估計(jì)問題中的多重性的一般關(guān)系由于 James 和 Stein 等人的工作而得到了理論上的重要進(jìn)展。最終,這啟發(fā)了心理學(xué)、藥理學(xué)、抽樣調(diào)查等領(lǐng)域的研究。Lindley 和 Smith 于 1972 年發(fā)表的論文,以及 Lindley 和 Novick 于 1981 年發(fā)表的論文提供了一種基于估計(jì)多變量正態(tài)分布的超參數(shù)的數(shù)學(xué)結(jié)構(gòu),而 Efron 和 Morris 等人則給出了相應(yīng)的決策理論方面的解釋,接著這些思想被融入了回歸建模并被應(yīng)用于廣泛的使用結(jié)構(gòu)化數(shù)據(jù)的問題。
從另一個(gè)方向來看,Donoho 等人于 1995 年給出了多元參數(shù)收縮的信息論解釋。我們更傾向于將多層模型看做將不同的信息源進(jìn)行組合的框架,而不是一個(gè)特定的統(tǒng)計(jì)模型或計(jì)算過程。因此,每當(dāng)我們想要根據(jù)數(shù)據(jù)的子集進(jìn)行推理(小面積估計(jì))或?qū)?shù)據(jù)泛化到新問題(元分析)上的時(shí)候,就可以使用這種模型。類似地,貝葉斯推理的可貴之處在于,它不僅僅是一種將先驗(yàn)信息和數(shù)據(jù)組合起來的方法,也是一種解釋推理和決策的不確定性的方法。
1.5 泛型計(jì)算方法
前文中討論過的建模方面的研究進(jìn)展高度依賴于現(xiàn)代計(jì)算科學(xué),這不僅僅指的是更大的內(nèi)存、更快的 CPU、高效的矩陣計(jì)算、對(duì)用戶友好的語(yǔ)言,以及其它計(jì)算科學(xué)方面的創(chuàng)新。用于高效計(jì)算的統(tǒng)計(jì)算法方面的進(jìn)展也是一個(gè)關(guān)鍵的因素。
在過去的 50 年中,在統(tǒng)計(jì)問題的結(jié)構(gòu)方面出現(xiàn)了許多具有創(chuàng)新性的統(tǒng)計(jì)算法。EM 算法、Gibbs 采樣、粒子濾波、變分推斷、期望傳播以不同的方式利用了統(tǒng)計(jì)模型的條件獨(dú)立結(jié)構(gòu)。
而 Metropolis 算法、混合或 Hamiltonian 蒙特卡洛算法則并沒有直接受到統(tǒng)計(jì)問題的啟發(fā),它們最初被提出用于計(jì)算物理學(xué)中的高維概率分布,但是它們已經(jīng)適應(yīng)了統(tǒng)計(jì)計(jì)算,這與在更早的時(shí)候被用于計(jì)算最小二乘以及最大似然估計(jì)的優(yōu)化算法相同。
當(dāng)似然的解析形式很難求解或計(jì)算開銷非常大時(shí),被稱為近似貝葉斯計(jì)算的方法(通過生成式模型仿真、而不是對(duì)似然函數(shù)進(jìn)行估計(jì)得到后驗(yàn)推理)是十分有效的。
縱觀統(tǒng)計(jì)學(xué)的歷史,數(shù)據(jù)分析的發(fā)展、概率建模和計(jì)算科學(xué)是共同發(fā)展的。新的模型會(huì)激發(fā)具有創(chuàng)新性的計(jì)算算法,而新的計(jì)算技術(shù)又為更加復(fù)雜的模型和新的推理思想開啟了大門(例如,高維正則化、多層建模、自助抽樣法)。通用的自動(dòng)推理算法使我們可以將模型的研發(fā)解耦開來,這樣一來變更模型并不需要對(duì)算法實(shí)現(xiàn)進(jìn)行改變。
1.6 自適應(yīng)決策分析
自 20 世紀(jì) 40 年代至 20 世紀(jì) 60 年代,決策理論往往被認(rèn)為是統(tǒng)計(jì)學(xué)的基石,代表性的工作包括:效用最大化、錯(cuò)誤率控制、以及經(jīng)驗(yàn)貝葉斯分析。
近年來,沿著上述工作的方向,研究人員在貝葉斯決策理論、錯(cuò)誤發(fā)現(xiàn)率分析等領(lǐng)域也取得了一系列成果。決策理論還受到了有關(guān)人類決策中的啟發(fā)與偏見的心理學(xué)研究的影響。
決策也是統(tǒng)計(jì)學(xué)的應(yīng)用領(lǐng)域之一。在統(tǒng)計(jì)決策分析領(lǐng)域的領(lǐng)域中,重要的研究成果包括:貝葉斯優(yōu)化、強(qiáng)化學(xué)習(xí),這與工業(yè)中的 A/B 測(cè)試的實(shí)驗(yàn)設(shè)計(jì)的復(fù)興以及許多工程應(yīng)用中的在線學(xué)習(xí)有關(guān)。
計(jì)算科學(xué)的最新進(jìn)展使我們可以將高斯過程和神經(jīng)網(wǎng)絡(luò)這些高度參數(shù)化的模型用作自適應(yīng)決策分析中的函數(shù)的先驗(yàn),還可以在仿真環(huán)境中進(jìn)行大規(guī)模的強(qiáng)化學(xué)習(xí),例如:創(chuàng)造能夠控制機(jī)器人、生成文本、以及參與圍棋等游戲。
1.7 魯棒的推理
魯棒性思想是現(xiàn)代統(tǒng)計(jì)學(xué)的核心,它指的是:即使在假設(shè)錯(cuò)誤的前提條件下,我們也可以使用模型。實(shí)際上,開發(fā)出能夠在違背上述假設(shè)的真實(shí)場(chǎng)景下良好運(yùn)行的模型對(duì)于統(tǒng)計(jì)理論來說是十分重要的。
Tukey 曾于 1960 年在論文「A survey of sampling from contaminated distributions」中對(duì)該領(lǐng)域的工作進(jìn)行了綜述,Stigler 也于 2010 年在論文「The changing history of robustness」中進(jìn)行了回顧。
受到 Huber 等人工作的影響,研究者們開發(fā)出了一系列在現(xiàn)實(shí)生活中(尤其是經(jīng)濟(jì)學(xué)領(lǐng)域,人們對(duì)統(tǒng)計(jì)模型的缺陷有深刻的認(rèn)識(shí))具有一定影響力的魯棒方法。在經(jīng)濟(jì)學(xué)理論中,存在「as if」分析和簡(jiǎn)化模型的概念,因此計(jì)量經(jīng)濟(jì)學(xué)家會(huì)對(duì)在一系列假設(shè)下還能運(yùn)行良好的統(tǒng)計(jì)程序十分感興趣。例如,經(jīng)濟(jì)學(xué)和其它社會(huì)科學(xué)領(lǐng)域的應(yīng)用研究人員廣泛使用魯棒標(biāo)準(zhǔn)誤差以及部分識(shí)別。
一般來說,正如在 Bernardo 和 Smith 于 1994 年所提出的 「M-開放世界」(在這個(gè)世界中,數(shù)據(jù)生成過程不屬于擬合的概率模型)下評(píng)估統(tǒng)計(jì)過程的想法一樣,統(tǒng)計(jì)研究中的魯棒性的主要影響并不在于對(duì)特定方法的發(fā)展。Greenland 認(rèn)為,研究者需要顯式地解釋傳統(tǒng)統(tǒng)計(jì)模型中沒有考慮的誤差來源。對(duì)魯棒性的關(guān)注與高度參數(shù)化的模型相關(guān),這是現(xiàn)代統(tǒng)計(jì)學(xué)的特點(diǎn),對(duì)模型評(píng)估有更普遍的影響。
1.8 探索性數(shù)據(jù)分析
上文討論的統(tǒng)計(jì)思想都涉及密集的理論和計(jì)算的結(jié)合。從另一個(gè)完全不同的方向來看,研究人員們進(jìn)行了一種具有影響力的「回歸到本質(zhì)」的探索,他們跳出概率模型,重點(diǎn)關(guān)注數(shù)據(jù)的圖形可視化。
Tukey 和 Tufte 等人在他們的著作中曾對(duì)統(tǒng)計(jì)圖的優(yōu)點(diǎn)進(jìn)行了討論,而許多這樣的思想通過他們?cè)跀?shù)據(jù)分析環(huán)境 S(目前在統(tǒng)計(jì)學(xué)及其應(yīng)用領(lǐng)域占據(jù)主導(dǎo)地位的 R 語(yǔ)言的前身)中的實(shí)現(xiàn)開展了統(tǒng)計(jì)實(shí)踐。
在 Tukey 之后,探索性數(shù)據(jù)分析的擁躉重點(diǎn)說明了漸進(jìn)理論的局限性以及開放式探索和通信的好處,并且闡明了超越統(tǒng)計(jì)理論的對(duì)統(tǒng)計(jì)科學(xué)的更一般的觀點(diǎn)。這與更加關(guān)注發(fā)現(xiàn)而非檢驗(yàn)固定假設(shè)的統(tǒng)計(jì)建模觀點(diǎn)不謀而合。
同時(shí),它不僅在特定的圖形化方法的發(fā)展中十分具有影響力,也從科學(xué)的數(shù)據(jù)中學(xué)習(xí),將統(tǒng)計(jì)學(xué)從定理證明轉(zhuǎn)向更開放、更健康的角度。舉例而言,在醫(yī)學(xué)統(tǒng)計(jì)學(xué)領(lǐng)域中,Bland 和 Altman 于 1986 年發(fā)表的一篇高被引論文推薦人們將圖形化方法用于數(shù)據(jù)對(duì)比,從而替換關(guān)聯(lián)性和回歸分析。
此外,研究人員試圖形式化定義探索性數(shù)據(jù)分析:Gelman 將數(shù)據(jù)展示與貝葉斯預(yù)測(cè)檢查的可視化相結(jié)合,Wilkinson 形式化定義了統(tǒng)計(jì)圖中固有的對(duì)比和數(shù)據(jù)結(jié)構(gòu),而 Wickham 通過這種方式得以實(shí)現(xiàn)了一個(gè)極具影響力的 R 語(yǔ)言程序包,從而在許多領(lǐng)域中改變了統(tǒng)計(jì)學(xué)實(shí)踐。
計(jì)算的進(jìn)步使從業(yè)者們能夠快速構(gòu)建大型的復(fù)雜模型,其中在理解數(shù)據(jù)、擬合的模型、預(yù)測(cè)結(jié)果之間的關(guān)系時(shí),統(tǒng)計(jì)圖是十分有用的。「探索性模型分析」有時(shí)被用來獲取數(shù)據(jù)分析過程的實(shí)驗(yàn)特性。研究人員們也一直進(jìn)行著將可視化囊括在模型構(gòu)建和數(shù)據(jù)分析過程中的研究工作。
2.相同點(diǎn)與不同點(diǎn)
2.1 思想能產(chǎn)生方法與工作流程
我們之所以認(rèn)為上面列出的思想重要,是因?yàn)樗鼈儾粌H解決了現(xiàn)有問題,還建立了新的統(tǒng)計(jì)思維方式和數(shù)據(jù)分析方式。換句話說,上述的每一種思想都是一部法典,其方法不僅局限于統(tǒng)計(jì)學(xué),而更像是一種“研究品味”或“哲學(xué)思想”:
? 反事實(shí)機(jī)制將因果推理置于統(tǒng)計(jì)或預(yù)測(cè)的框架中,其中,因果估量(causal estimands)可以根據(jù)統(tǒng)計(jì)模型中未觀察到的數(shù)據(jù)精確定義和表達(dá),并與調(diào)查抽樣和缺失數(shù)據(jù)推算的思想聯(lián)系起來。
? Boostrap 打開了隱式非參數(shù)建模(implicit nonparametric modeling)的大門。
? 過參數(shù)化的模型和正則化基于從數(shù)據(jù)中估計(jì)模型參數(shù)的能力,將限制模型大小的現(xiàn)有做法形式化和泛化,這與交叉驗(yàn)證和信息標(biāo)準(zhǔn)有關(guān)。
? 多層模型將從數(shù)據(jù)估計(jì)先驗(yàn)分布的“經(jīng)驗(yàn)貝葉斯”技術(shù)形式化,使這種方法在類別更廣泛的問題中使用時(shí)具備更高的計(jì)算與推理穩(wěn)定性。
? 泛型計(jì)算算法使實(shí)踐者能夠快速擬合用于因果推理、多層次分析、強(qiáng)化學(xué)習(xí)和其他許多領(lǐng)域的高級(jí)模型,使核心思想在統(tǒng)計(jì)學(xué)和機(jī)器學(xué)習(xí)中產(chǎn)生更廣泛的影響。
? 自適應(yīng)決策分析將最佳控制的工程問題與統(tǒng)計(jì)學(xué)習(xí)領(lǐng)域聯(lián)系在一起,遠(yuǎn)遠(yuǎn)超出了經(jīng)典的實(shí)驗(yàn)設(shè)計(jì)。
? 魯棒推理將對(duì)推理穩(wěn)定性的直覺形式化,在表達(dá)這些問題時(shí)可以對(duì)不同程序進(jìn)行正式評(píng)估和建模,以處理對(duì)異常值和模型錯(cuò)誤說明的潛在擔(dān)憂。此外,魯棒推理的思想也為非參數(shù)估計(jì)提供了信息。
? 探索性數(shù)據(jù)分析使圖形技術(shù)和發(fā)現(xiàn)成為統(tǒng)計(jì)實(shí)踐的主流,因?yàn)檫@些工具正好可以用于更好地理解和診斷正在與數(shù)據(jù)進(jìn)行擬合的概率模型的新型復(fù)雜類別。
2.2. 計(jì)算上的進(jìn)步
元算法(利用現(xiàn)有模型和推理步驟的工作流)在統(tǒng)計(jì)學(xué)中被廣泛使用,比如最小二乘法,矩估計(jì)(the method of moments),最大似然,等等。
在過去 50 年里所開發(fā)的許多機(jī)器學(xué)習(xí)元算法都有一個(gè)特征,就是它們會(huì)以某種方式拆分?jǐn)?shù)據(jù)或模型。學(xué)習(xí)元算法(Learning Meta-Algorithms)與分治計(jì)算方法相關(guān),最著名的是變分貝葉斯和期望傳播算法。
元算法和迭代計(jì)算在統(tǒng)計(jì)學(xué)中之所以重要,主要是有兩個(gè)原因:1)除了最初開發(fā)的元算法示例以外,通過多個(gè)來源整合信息,或通過整合弱分類器(weak learner)來創(chuàng)建強(qiáng)分類器的通用想法可以得到廣泛應(yīng)用;2)自適應(yīng)算法在在線學(xué)習(xí)中發(fā)揮了很好的作用,最終被認(rèn)為代表了現(xiàn)代統(tǒng)計(jì)觀點(diǎn):數(shù)據(jù)和計(jì)算分開,信息交換和計(jì)算架構(gòu)是元模型或推理過程的一部分。
新方法使用新技術(shù)工具并不稀奇:隨著計(jì)算速度越快、計(jì)算范圍越廣,統(tǒng)計(jì)學(xué)家不再局限于具備解析方案的簡(jiǎn)單模型與簡(jiǎn)單的封閉式算法(如最小二乘法)。我們可以簡(jiǎn)要說一下上述思想是如何利用現(xiàn)代計(jì)算:
? 一些思想(boostrapping,超參數(shù)化模型和機(jī)器學(xué)習(xí)元分析)直接利用了計(jì)算速度,這在計(jì)算機(jī)出現(xiàn)之前難以想象。例如,直到引入高效的GPU卡和云計(jì)算之后,神經(jīng)網(wǎng)絡(luò)才更加流行起來。
? 除了計(jì)算能力以外,計(jì)算資源的分散也很重要:臺(tái)式計(jì)算機(jī)能讓統(tǒng)計(jì)學(xué)家和計(jì)算機(jī)科學(xué)家嘗試新方法,然后由從業(yè)人員使用這些新方法。
? 探索性數(shù)據(jù)分析最初是從紙筆圖形開始,但隨著計(jì)算機(jī)圖形學(xué)的發(fā)展,探索性數(shù)據(jù)分析已經(jīng)歷徹底改變。
? 過去,貝葉斯推理僅限于可以通過分析解決的簡(jiǎn)單模型。隨著計(jì)算能力的提高,變分和馬爾可夫鏈模擬方法使得模型構(gòu)建和推理算法開發(fā)的分離成為可能,概率編程也因此允許不同領(lǐng)域的專家能夠?qū)W⒂谀P蜆?gòu)建并自動(dòng)完成推理。這導(dǎo)致了貝葉斯方法在1990年開始在許多應(yīng)用領(lǐng)域變得普及。
? 自適應(yīng)決策分析,貝葉斯優(yōu)化和在線學(xué)習(xí)應(yīng)用于計(jì)算和數(shù)據(jù)密集型問題,例如優(yōu)化大型機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)模型,實(shí)時(shí)圖像處理和自然語(yǔ)言處理。
? 魯棒的統(tǒng)計(jì)學(xué)不一定需要大量計(jì)算,但它的使用在一定程度上由計(jì)算驅(qū)動(dòng),與封閉式估計(jì)(如最小二乘法)有所區(qū)別。Andrews等人曾使用大量計(jì)算進(jìn)行了一項(xiàng)模擬研究,促進(jìn)了對(duì)魯棒方法的開發(fā)和理解。
? 減少多元推理的合理性不僅可以通過統(tǒng)計(jì)效率來證明,還可以從計(jì)算層面證明:激發(fā)了一種新的漸近理論。
? 反事實(shí)因果推理的關(guān)鍵思想與理論相關(guān),而不是計(jì)算相關(guān)。但是,近年來,因果推理在使用計(jì)算密集的非參數(shù)方法后已有了發(fā)展,促進(jìn)了統(tǒng)計(jì)學(xué)、經(jīng)濟(jì)學(xué)和機(jī)器學(xué)習(xí)中因果和預(yù)測(cè)模型的統(tǒng)一。
2.3 大數(shù)據(jù)
除了為統(tǒng)計(jì)分析開拓發(fā)展空間以外,現(xiàn)代計(jì)算還啟發(fā)了新統(tǒng)計(jì)方法的應(yīng)用和開發(fā),從而產(chǎn)生了大數(shù)據(jù),例子有:基因陣列,流圖像和文本數(shù)據(jù),以及在線控制問題,如自動(dòng)駕駛汽車。事實(shí)上,“數(shù)據(jù)科學(xué)”流行的原因之一就是因?yàn)椋诖祟悊栴}中,數(shù)據(jù)處理和高效計(jì)算是與用于擬合數(shù)據(jù)的統(tǒng)計(jì)方法一樣重要的。
這與 Hal Stern 的觀點(diǎn)相關(guān):統(tǒng)計(jì)分析最重要的方面不是對(duì)數(shù)據(jù)進(jìn)行的操作,而是你所使用的數(shù)據(jù)是什么。與先前的方法相比,本文討論的所有思想都有一個(gè)共同特征,即有助于使用更多的數(shù)據(jù):
? 反事實(shí)框架允許使用用于對(duì)受控實(shí)驗(yàn)建模的相同結(jié)構(gòu)從觀測(cè)數(shù)據(jù)中進(jìn)行因果推斷。
? Bootstrapping 可用于糾正偏差,與在分析計(jì)算無(wú)法進(jìn)行的復(fù)雜調(diào)查、實(shí)驗(yàn)設(shè)計(jì)和其他數(shù)據(jù)結(jié)構(gòu)上進(jìn)行方差估計(jì)。
? 正則化允許用戶在模型中加入更多預(yù)測(cè)變量,而不必?fù)?dān)心過度擬合。
? 多層模型使用部分匯集來合并來源不同的信息,從而更廣泛應(yīng)用元分析的原理。
? 泛型計(jì)算算法允許用戶擬合更大的模型,這對(duì)將可用數(shù)據(jù)連接到重要的基本問題來說可能是有必要的。
? 自適應(yīng)決策分析利用在數(shù)值分析中開發(fā)的隨機(jī)優(yōu)化方法。
? 魯棒推理可以更常規(guī)地使用具有異常值、相關(guān)性和其他可能阻礙常規(guī)統(tǒng)計(jì)建模的數(shù)據(jù)。
? 探索性數(shù)據(jù)分析為復(fù)雜數(shù)據(jù)集的可視化打開了大門,并推動(dòng)了整潔數(shù)據(jù)分析(tidy data analysis)的發(fā)展,以及統(tǒng)計(jì)分析、計(jì)算和通信的集成。
在過去的50 年里,統(tǒng)計(jì)編程環(huán)境也有了很大的發(fā)展,最著名的是S語(yǔ)言、R語(yǔ)言,還有以 BUGS 開頭命名的通用推理引擎及其后繼者。近日,數(shù)值分析、自動(dòng)推理和統(tǒng)計(jì)計(jì)算的思想開始以可復(fù)制的研究環(huán)境(如Jupyter notebook)和概率編程環(huán)境(如Stan,Tensorflow和Pyro)的形式混合在一起。因此,我們至少可以預(yù)計(jì)推理和計(jì)算方法的部分統(tǒng)一,例如使用自動(dòng)微分進(jìn)行優(yōu)化、采樣和靈敏度分析。
2.4 這些思想的關(guān)聯(lián)與交互
Stigler 在 2016 年提出,一些明顯不同的統(tǒng)計(jì)領(lǐng)域背后存在某些共同主題的相關(guān)性。這一互相聯(lián)系的思想也可以用于最近的發(fā)展。例如,魯棒統(tǒng)計(jì)學(xué)(側(cè)重于偏離特定模型假設(shè))和探索性數(shù)據(jù)分析(傳統(tǒng)上被認(rèn)為對(duì)模型根本不感興趣)之間有什么聯(lián)系?
探索性方法(如殘差圖和 hanging rootograms )可以從特定的模型分類(分別是累計(jì)回歸和泊松分布)中獲得,但是,它們的價(jià)值在很大程度上是在于其可解釋性,即無(wú)需參考啟發(fā)它們的模型。
同樣,你可以單獨(dú)將一種方法(如最小二乘法)看作對(duì)數(shù)據(jù)的運(yùn)算,然后研究表現(xiàn)好的數(shù)據(jù)生成過程的類別,再使用這種理論分析的結(jié)果來提出更魯棒的程序,能夠拓展無(wú)論是基于故障點(diǎn)(breakdown point),極小化極大風(fēng)險(xiǎn)或其他方式定義的適用范圍。相反,純粹的計(jì)算方法(例如蒙特卡洛積分估算)可以被有效解釋為統(tǒng)計(jì)推理問題的解決方案。
另一個(gè)聯(lián)系是,因果推理的潛在結(jié)果框架對(duì)人群中的每個(gè)單元都有不同的處理效應(yīng),因此自然而然就采用了一種元分析方法將效應(yīng)多樣化,并使用在實(shí)驗(yàn)或觀察性研究分析中使用多層次回歸進(jìn)行建模。
回過頭來看,研究 bootstrap 可以為我們提供一種新觀點(diǎn):將經(jīng)驗(yàn)貝葉斯(多層次)推理看作非透視方法。在該方法中,正態(tài)分布或其他參數(shù)模型用于部分匯集,但最終估計(jì)值不局限于任何參數(shù)形式。對(duì)小波(wavelets)和其他豐富參數(shù)化模型進(jìn)行正則化的研究與在魯棒背景下開發(fā)的穩(wěn)定推理程序之間存在意想不到的聯(lián)系。
其他方法論的聯(lián)系更為明顯。正則化的過參數(shù)化模型使用機(jī)器學(xué)習(xí)元算法進(jìn)行了優(yōu)化,反過來又可以得出對(duì) contamination 具有魯棒性的推論。這些連接可以用其他方式表示,魯棒回歸模型對(duì)應(yīng)混合分布,混合分布可以視為多層次模型,還可以使用貝葉斯推理進(jìn)行擬合。深度學(xué)習(xí)模型與一種多層次邏輯回歸相關(guān),也與復(fù)現(xiàn)核心的 Hilbert 空間(在樣條中使用,支持向量機(jī))相關(guān)。
高度參數(shù)化的機(jī)器學(xué)習(xí)方法可以構(gòu)建為貝葉斯分層模型,其中將懲罰函數(shù)正則化與超先驗(yàn)相一致,無(wú)監(jiān)督學(xué)習(xí)模型也可以被構(gòu)建為具有未知組員的混合模型。在許多情況下,是否使用貝葉斯生成框架是取決于計(jì)算,這也是雙向進(jìn)行:貝葉斯計(jì)算方法可以幫助掌握推理和預(yù)測(cè)中的不確定性,高效優(yōu)化算法也可以用于近似基于模型的推理 。
許多被廣泛討論的思想都涉及到豐富的參數(shù)化,并伴隨一些用于正則化的統(tǒng)計(jì)或計(jì)算工具。因此,它們可以被認(rèn)為是經(jīng)篩選思想的更廣泛實(shí)現(xiàn):隨著可用數(shù)據(jù)的增加,模型會(huì)變得更大。
2.5 理論促進(jìn)應(yīng)用,反之亦然
可以說所有這些方法的共同特征是易記的名稱和良好的傳播。但是作者懷疑這些方法的名稱僅在回顧時(shí)會(huì)引起注意。諸如“反事實(shí)”、“引導(dǎo)程序”、“堆疊”和“增強(qiáng)”之類的術(shù)語(yǔ)聽起來很專業(yè),而不是令人印象深刻,作者認(rèn)為是方法的價(jià)值使這些名字變得響亮。
創(chuàng)新的想法經(jīng)常會(huì)遇到阻力,這也是本文中討論的這些有影響力的想法的命運(yùn)。如果一個(gè)新思想起源于一個(gè)應(yīng)用領(lǐng)域,那么要說服理論家相信它的價(jià)值可能會(huì)遇到很大挑戰(zhàn)。相反,批評(píng)新方法在理論上是有用的,但在實(shí)踐中沒有用,倒是很容易。
我們應(yīng)該澄清,所謂“反對(duì)”不一定意味著積極反對(duì)。與其他一些學(xué)術(shù)領(lǐng)域相比,統(tǒng)計(jì)數(shù)據(jù)不是很政治化:學(xué)術(shù)界、政府和行業(yè)內(nèi)部對(duì)統(tǒng)計(jì)領(lǐng)域的發(fā)展很寬容,甚至邊緣思想也被允許發(fā)展。此處討論的許多方法(例如引導(dǎo)程序,lasso和多層模型)在統(tǒng)計(jì)和各種應(yīng)用領(lǐng)域中都立即流行起來,但即使是這些思想也面臨著阻力,即局外人需要確信其應(yīng)用的必要性。
理論統(tǒng)計(jì)學(xué)是應(yīng)用統(tǒng)計(jì)學(xué)的理論,這在一定程度上得益于諸如Cox的“Planning of Experiments”,Box and Tiao的“Bayesian Inference in Statistical Analysis”,Cox and Hinkley的“Theoretical Statistics”,Box,Hunter和Hunter的“Statistics for Experimenters”等有影響力的著作,幫助我們跨越了理論和應(yīng)用之間的鴻溝。
不同于純數(shù)學(xué),不存在純粹的統(tǒng)計(jì)。沒錯(cuò),一些統(tǒng)計(jì)思想是深刻而優(yōu)美的,并且與數(shù)學(xué)一樣,這些思想也具有基本的聯(lián)系。例如,回歸和均值之間的聯(lián)系,最小二乘和部分池化之間的聯(lián)系,但它們?nèi)耘c特定主題相關(guān)。就像摘下的蘋果一樣,脫離其營(yíng)養(yǎng)來源后,理論統(tǒng)計(jì)研究趨于枯竭。數(shù)學(xué)也是如此,但是純數(shù)學(xué)中的思想似乎可以存在更長(zhǎng)的時(shí)間,并且能以孤立的研究存在,而統(tǒng)計(jì)學(xué)思想則無(wú)法如此。
應(yīng)用統(tǒng)計(jì)理論帶來的好處是顯而易見的。人們可以將理論視為計(jì)算的捷徑。我們總是需要這樣的捷徑:建模的需求不可避免地隨著計(jì)算能力的增長(zhǎng)而增加,因此我們需要分析壓縮和逼近的價(jià)值。此外,理論可以幫助我們理解統(tǒng)計(jì)方法的工作原理,而數(shù)學(xué)邏輯可以啟發(fā)新的模型和數(shù)據(jù)分析方法。
2.6 和統(tǒng)計(jì)領(lǐng)域其他進(jìn)展的關(guān)聯(lián)
特定的統(tǒng)計(jì)模型與這些重要思想是什么聯(lián)系?在這里,作者考慮的是有影響力的工作,例如風(fēng)險(xiǎn)回歸、廣義線性模型、空間自回歸、結(jié)構(gòu)方程模型、潛在分類、高斯過程和深度學(xué)習(xí)。如上所述,在過去的半個(gè)世紀(jì)中,統(tǒng)計(jì)推斷和計(jì)算領(lǐng)域出現(xiàn)了許多重要的發(fā)展,這些發(fā)展都受到了上面討論的新模型和推斷思想的啟發(fā)和推動(dòng)。模型、方法、應(yīng)用程序和計(jì)算都結(jié)合在一起。
討論不同概念發(fā)展之間的聯(lián)系,并不意味著關(guān)于適當(dāng)使用和解釋統(tǒng)計(jì)方法的爭(zhēng)論仍然存在。例如,錯(cuò)誤發(fā)現(xiàn)率(false discovery rate)與多層模型之間存在雙重性,但是基于這些不同原理的過程可以給出不同的結(jié)果。通常使用貝葉斯方法來擬合多層模型,并且在后驗(yàn)分布中,沒有任何東西會(huì)一直收斂到零。
相反,錯(cuò)誤發(fā)現(xiàn)率方法通常使用p值閾值,目的是識(shí)別少量統(tǒng)計(jì)上顯著的非零結(jié)果。再例如,在因果推理中,人們?cè)絹碓疥P(guān)注密集參數(shù)化的機(jī)器學(xué)習(xí)預(yù)測(cè),然后進(jìn)行后分層(poststratification)以獲得特定的因果估計(jì),但是在更開放的環(huán)境中,需要發(fā)現(xiàn)非零因果關(guān)系。同樣,根據(jù)目標(biāo)是密集預(yù)測(cè)還是稀疏預(yù)測(cè),使用了不同的方法。
最后,我們可以將統(tǒng)計(jì)方法的研究與科學(xué)和工程學(xué)中統(tǒng)計(jì)應(yīng)用的趨勢(shì)聯(lián)系起來。在這里,作者提到了生物學(xué)、心理學(xué)、經(jīng)濟(jì)學(xué)和其他科學(xué)領(lǐng)域的復(fù)現(xiàn)危機(jī)或可復(fù)現(xiàn)性革命,這些領(lǐng)域的變異范圍足夠大,需要根據(jù)統(tǒng)計(jì)證據(jù)得出結(jié)論。
在可復(fù)現(xiàn)性革命中,具有里程碑意義的論文包括:
Meehl發(fā)表的“Theoretical risks and tabular asterisks: Sir Karl, Sir Ronald, and the slow progress of soft psychology”,概述了在原假設(shè)重要性檢驗(yàn)的標(biāo)準(zhǔn)用法中提出科學(xué)主張的哲學(xué)缺陷。
Ioannidis發(fā)表的“Why most published research findings are false”,其認(rèn)為,醫(yī)學(xué)上大多數(shù)已發(fā)表的研究都在使得結(jié)論不受其統(tǒng)計(jì)數(shù)據(jù)的支持。
Simmons,Nelson和Simonsohn發(fā)表的“False-positive psychology: Undisclosed flexibility in data collection and analysis allow presenting anything as significant ”,解釋了“研究人員的自由度”如何使研究人員即使從純?cè)肼晹?shù)據(jù)中也能常規(guī)獲得統(tǒng)計(jì)意義。
一些補(bǔ)救措施是程序性的,例如Amrhein,Greenland和McShane發(fā)表的“Scientists rise up against statistical significance”。
但也有人建議可以使用多層模型解決不可復(fù)現(xiàn)研究的某些問題,將估計(jì)值部分歸零以更好地反映研究中的效應(yīng)總量,例如van Zwet,Schwab和Senn發(fā)表的“The statistical properties of RCTs and a proposal for shrinkage”。
可再現(xiàn)性和穩(wěn)定性問題也直接涉及到引導(dǎo)程序和可靠的統(tǒng)計(jì)數(shù)據(jù),參見Yu. B.發(fā)表的“Stability.”。
3.未來幾十年的重要統(tǒng)計(jì)思想會(huì)是什么?
3.1 回顧
在考慮自1970年以來最重要的發(fā)展時(shí),回顧一下1920-1970年的重要統(tǒng)計(jì)思想(包括質(zhì)量控制、潛在變量建模、抽樣理論、實(shí)驗(yàn)設(shè)計(jì)、經(jīng)典和貝葉斯決策分析、置信區(qū)間和假設(shè)檢驗(yàn)、最大似然、方差分析和客觀貝葉斯推理)也很有意義。當(dāng)然還有1870年至1920年(概率分布分類、均值回歸、數(shù)據(jù)現(xiàn)象學(xué)建模),以及Stigler在《The History of Statistics》中提到的更早年代的統(tǒng)計(jì)思想。
在本文中,作者試圖提供一個(gè)廣泛的視角,以反映不同的觀點(diǎn)。但是其他人可能對(duì)過去五十年來最重要的統(tǒng)計(jì)思想有自己的看法。確實(shí),問這個(gè)問題主要是引起人們對(duì)統(tǒng)計(jì)學(xué)觀念的重要性的討論。在本文中,作者避免了使用引文計(jì)數(shù)或其他數(shù)值方法對(duì)論文進(jìn)行排名,但是他們隱含地以類似page-rank的方式來衡量影響力,因?yàn)樗麄冊(cè)噲D將注意力集中在那些影響了統(tǒng)計(jì)實(shí)踐的方法發(fā)展的思想上。
3.2 展望
接下來會(huì)發(fā)生什么?作者同意卡爾·波普爾(Karl Popper)的觀點(diǎn),即人們無(wú)法預(yù)見所有未來的科學(xué)發(fā)展,但是我們可能對(duì)當(dāng)前的趨勢(shì)將如何持續(xù)有比較可靠的見解。
最安全的選擇是,在現(xiàn)有方法組合上持續(xù)取得進(jìn)展:對(duì)潛在輸出的豐富模型進(jìn)行因果推理,并使用正則化估計(jì);結(jié)構(gòu)化數(shù)據(jù)的復(fù)雜模型,例如隨時(shí)間演變的網(wǎng)絡(luò),對(duì)多層模型的可靠推斷;對(duì)超參數(shù)化模型的探索性數(shù)據(jù)分析;用于不同計(jì)算問題的子集(subsetting)和機(jī)器學(xué)習(xí)元算法等等。此外,作者期望在結(jié)構(gòu)化數(shù)據(jù)的實(shí)驗(yàn)設(shè)計(jì)和采樣方面取得進(jìn)展。
另一個(gè)成熟的發(fā)展領(lǐng)域是模型理解,有時(shí)也稱為可解釋機(jī)器學(xué)習(xí)。這里的矛盾之處在于,理解復(fù)雜模型的最佳方法通常是使用簡(jiǎn)單模型對(duì)其進(jìn)行近似。但問題是,在這過程中是什么在進(jìn)行交流?一種可能有用的方法是計(jì)算對(duì)數(shù)據(jù)和模型參數(shù)擾動(dòng)的推斷敏感性,將魯棒性和正則化的思想與基于梯度的計(jì)算方法相結(jié)合,該方法在許多不同的統(tǒng)計(jì)算法中使用。
最后,鑒于幾乎所有新的統(tǒng)計(jì)和數(shù)據(jù)科學(xué)思想在計(jì)算上都是昂貴的,因此,作者設(shè)想了對(duì)推論方法驗(yàn)證的未來研究,將諸如軟件工程中的單元測(cè)試之類的思想應(yīng)用到從噪聲數(shù)據(jù)中學(xué)習(xí)的問題中。隨著統(tǒng)計(jì)方法變得越來越先進(jìn),理解數(shù)據(jù)、模型和實(shí)體理論之間的聯(lián)系將變得越來越重要。
作者簡(jiǎn)介:
Andrew Gelman,美國(guó)統(tǒng)計(jì)學(xué)家,哥倫比亞大學(xué)統(tǒng)計(jì)學(xué)和政治學(xué)教授。他1986年獲得麻省理工學(xué)院數(shù)學(xué)和物理學(xué)博士學(xué)位。隨后,他獲得了博士學(xué)位。在哈佛大學(xué)統(tǒng)計(jì)學(xué)榮譽(yù)退休教授Donald Rubin的指導(dǎo)下,于1990年從哈佛大學(xué)獲得統(tǒng)計(jì)學(xué)博士學(xué)位。他是美國(guó)統(tǒng)計(jì)協(xié)會(huì)與數(shù)理統(tǒng)計(jì)學(xué)會(huì)的院士,曾三度獲得美國(guó)統(tǒng)計(jì)協(xié)會(huì)頒發(fā)的“杰出統(tǒng)計(jì)應(yīng)用獎(jiǎng)”,谷歌學(xué)術(shù)顯示,他的論文總引用量超過12萬(wàn),h-index為110。
Aki Vehtari,阿爾托大學(xué)計(jì)算機(jī)科學(xué)系副教授,主要研究領(lǐng)域?yàn)樨惾~斯概率理論和方法、貝葉斯工作流、概率編程、推理方法(例如Laplace,EP,VB,MC)、推理和模型診斷、模型評(píng)估和選擇、高斯過程以及分層模型。谷歌學(xué)術(shù)顯示,他的論文總引用量近4萬(wàn)。他和Andrew Gelman都是《貝葉斯數(shù)據(jù)分析》的作者,這本書因在數(shù)據(jù)分析、研究解決難題方面的可讀性、實(shí)用性而廣受讀者好評(píng),被認(rèn)為是貝葉斯方法領(lǐng)域的優(yōu)秀之作。
因果科學(xué)第二季讀書會(huì)報(bào)名中
因果推斷與機(jī)器學(xué)習(xí)領(lǐng)域的結(jié)合已經(jīng)吸引了越來越多來自學(xué)界業(yè)界的關(guān)注,為深入探討、普及推廣因果科學(xué)議題,智源社區(qū)攜手集智俱樂部將舉辦第二季「」。本期讀書會(huì)著力于實(shí)操性、基礎(chǔ)性,將帶領(lǐng)大家精讀因果科學(xué)方向兩本非常受廣泛認(rèn)可的入門教材。
1. Pearl, Judea, Madelyn Glymour, and Nicholas P. Jewell. Causal inference in statistics: A primer. John Wiley & Sons, 2016.(本書中譯版《統(tǒng)計(jì)因果推理入門(翻譯版)》已由高等教育出版社出版)
2. Peters, Jonas, Dominik Janzing, and Bernhard Sch?lkopf. Elements of causal inference: foundations and learning algorithms. The MIT Press, 2017.
讀書會(huì)每周將進(jìn)行直播討論,進(jìn)行問題交流、重點(diǎn)概念分享、閱讀概覽和編程實(shí)踐內(nèi)容分析。非常適合有機(jī)器學(xué)習(xí)背景,希望深入學(xué)習(xí)因果科學(xué)基礎(chǔ)知識(shí)和重要模型方法,尋求解決相關(guān)研究問題的朋友參加。
目前因果科學(xué)讀書會(huì)系列,已經(jīng)有接近400多位的海內(nèi)外高校科研院所的一線科研工作者以及互聯(lián)網(wǎng)一線從業(yè)人員參與,吸引了國(guó)內(nèi)和國(guó)際上大部分的因果科學(xué)領(lǐng)域的專業(yè)科研人員,如果你也對(duì)這個(gè)主題感興趣,想要深度地參與,就快加入我們吧!
詳情請(qǐng)點(diǎn)擊:
原標(biāo)題:《統(tǒng)計(jì)學(xué)權(quán)威盤點(diǎn)過去50年最重要的統(tǒng)計(jì)學(xué)思想,因果推理、bootstrap等上榜,Judea Pearl點(diǎn)贊》
本文為澎湃號(hào)作者或機(jī)構(gòu)在澎湃新聞上傳并發(fā)布,僅代表該作者或機(jī)構(gòu)觀點(diǎn),不代表澎湃新聞的觀點(diǎn)或立場(chǎng),澎湃新聞僅提供信息發(fā)布平臺(tái)。申請(qǐng)澎湃號(hào)請(qǐng)用電腦訪問http://renzheng.thepaper.cn。



- 報(bào)料熱線: 021-962866
- 報(bào)料郵箱: news@thepaper.cn
滬公網(wǎng)安備31010602000299號(hào)
互聯(lián)網(wǎng)新聞信息服務(wù)許可證:31120170006
增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:滬B2-2017116
? 2014-2025 上海東方報(bào)業(yè)有限公司

