- +1
Nature:新冠流行難預測,超級計算機和氣象學家來幫忙
原創 Leo 集智俱樂部

流行病傳播模型是政府決策的重要參考,而預測疾病傳播的模型通常會依賴于數百個參數——這就會引入不確定性。當流行病預測模型的參數多到有點夸張時,預測出來的結果恐怕可靠性不足。最近的Nature官網的一篇報道,介紹了科學家怎樣借助超級計算機和氣候模型來改善一個經典的流行病傳播模型。

在一群計算機科學家耗時數月審核了一個最具影響力的流行病傳播模型 CovidSim 后,他們認為:如果希望對新冠流行趨勢的預測更加可靠,流行病學家可以嘗試使用氣候模型。
倫敦帝國理工學院開發了流行病預測模型 CovidSim。在說服英美政府為降低死亡人數而制定的封鎖政策中,CovidSim 模型給出的預測結果起到了一定的推進作用。然而,其可靠性卻也一直受到懷疑。
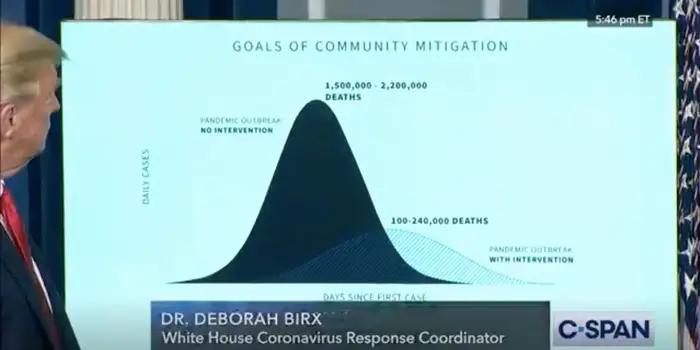
CovidSim模型的早期預測顯示,如果各國政府不采取行動,英國最多將有50萬人死亡,美國最多將有220萬人死亡。這一度成為英美兩國政府決策的重要參考。
近日,受倫敦皇家學會委托的研究員使用超級計算機,對CovidSim進行了深入研究。這項研究結果于11月發布于預印本平臺 Research Square 。
論文題目:
Model uncertainty and decision making: Predicting the Impact of COVID-19 Using the CovidSim Epidemiological Code
論文地址:
https://www.researchsquare.com/article/rs-82122/v3
領導該課題的倫敦大學學院化學家兼計算機科學家 Peter Coveney 表示,他們的研究表明,CovidSim 對輸入數值微小變化的敏感程度被人們忽略了,因此預測結果高估了封鎖政策能減少的死亡人數。

Coveney 不愿批評由流行病學家 Neil Ferguson 領導的帝國理工學院研究團隊。畢竟,Coveney 贊同這個團隊做出了最好的預測工作。Coveney 表示,CovidSim 的確表明,如果什么措施都不做確實會造成嚴重的后果。但流行病學家應該對“集成”模型('ensemble' models)的模擬效果進行壓力測試。
類似于機器學習中的多個模型相結合的集成學習(Ensemble Learning)概念,“集成”模型也包含著數千個不同版本的小模型。這些模型運行在不同的輸入條件和假設中,以應對不同的概率的場景。從天氣預報到分子動力學,在計算量很大的領域中,這種概率混合方法都很常見。
Coveney 的團隊已經為 CovidSim 做到了這一點。其研究結果表明:如果該模型作為一個整體“集成”,運行后得到的一系列可能的死亡人數,其平均值是原來預測結果的兩倍——并且更接近實際數值。
Coveney 說:“雖然 CovidSim 被捧為最復雜的流行病學模型,但與真正復雜的超級計算應用程序相比,它就像一個玩具。”英國皇家學會大流行建模快速援助(Royal Society’s Rapid Assistance in Modelling the Pandemic,RAMP)倡議的一部分就是基于 Coveney 所做的性能檢查。
超級計算機捕捉復雜參數變化
Coveney 團隊使用了位于波茲南超級計算和網絡中心的 Eagle 超級計算機對CovidSim 進行了6000次獨立的運行測試。每次測試都有一組獨特的參數。這些參數表示了流行病的一些特征:包括病毒的傳染性和致命性、人們在各種環境中潛在的接觸者數量以及居家工作等政策的執行情況等。在三月份帝國理工的團隊做出預測的時候,這些參數依然依賴于推測:其中一些來自關于病毒本身的初步數據,另一些則是基于對過往流感等傳染性疾病的經驗。
預測疾病傳播的模型通常會依賴于數百個參數——這就會引入不確定性。發起建立 RAMP 的人群中就有一種隱憂:流行病預測模型的參數多到有點夸張,預測出來的結果恐怕可靠性不足。
他的團隊從 CovidSim 代碼中發現了940個參數,其中對結果影響非常大的有19個。而且,不同的預測結果中三分之二的差異其實是由三個參數造成的:在出現癥狀且具有傳染性之前的潛伏期長度、社交隔離的執行情況以及感染者的隔離期。
研究表明,這些參數的微小變化可能會對模型的輸出產生巨大的非線性影響。例如,數千次模擬測試中的大多數結果表明,在封鎖政策下,英國的死亡人數遠遠高于帝國理工的初步預測——在某些情況下,甚至高出5-6倍。平均死亡人數也是帝國理工預測人數的2倍。
在一個模擬的情景中,假設英國每周有60人需要住院接受重癥監護,那么三月份的報告預測英國共計將有8700人死亡。Coveney小組得出的結果表明,這一數字平均約為15,000人;在某些情況下,甚至可能超過40,000人。很難將這些預測與英國新冠肺炎死亡的實際數字進行比較,因為封鎖政策開始的時間比任何模型假設的結果都晚了一周,那時已經有大量的感染者在傳播疾病了。
Coveney 表示,帝國理工的團隊做錯了——他們正確地運行了模擬,但是不知道如何從模型中得出包含概率的混合結果。這意味需要做另一番計算。Coveney 也認為,不應將該模型作為一個整體“集成”運行其得到的結果用來決策是否改變防疫政策。但是英國愛丁堡大學的流行病學家和數據科學家 Rowland Kao 指出,政府應當比較、綜合多種預測模型的結果。如果基于單一的模型來做決策,就太草率了。
引入氣候模型和貝葉斯工具
帝國理工團隊的領導者 Ferguson 認同了 Coveney 的大部分意見。但他也表示:“只不過,在三月份我們尚無能力進行這樣的模擬測試。”Ferguson 同時表示,帝國理工團隊已經對模型進行了很大的改進,現在模型已經可以得到包含概率的混合結果了。例如,他們現在使用貝葉斯概率來表示 CovidSim 輸入的不確定性。這種做法在一些流行病學模型中很常見,例如口蹄疫。
還有一個更簡單模型的預測結果被用來建議英國政府本月應重新執行封鎖政策。這種模型比CovidSim更靈活:“基于不確定性方面的考量,如果我們可以一周多次運行模擬程序,實時擬合數據要容易多了。”Ferguson 表示。
Coveney 表示,“這樣聽上去就像是在做正確的改進,且與我們的預測結果也一致了。”
Ferguson 表示,技術方案的選擇通常取決于對計算能力的權衡。“如果你想一板一眼正確地描述所有的不確定性,用一個計算難度較小的模型會更加容易。”
英國牛津大學的氣候物理學家 Tim Palmer 認為,使用貝葉斯工具是進步的做法。Tim 率先在天氣預報中使用了集成建模。但也只有通過在最強大的計算機上運行的集成建模技術,我們才能得到最可靠的流行病預測。在政府間氣候變化專門委員會(Intergovernmental Panel on Climate Change,IPCC)的協調下,這些新技術提高了氣候預測模型的可靠性。
Palmer 也表示,流行病模型預測也需要類似IPCC的機構,我們需要某些國際間合作的設施,我們可以在這樣的設施中開發流行病模型。情況緊急,這件事的推進將會很倉促,但是我們需要某種國際組織來綜合全世界的流行病學模型進行預測。
Simulating the pandemic: What COVID forecasters can learn from climate model
翻譯自:https://www.nature.com/articles/d41586-020-03208-1
作者:Leo
審校:趙雨亭
編輯:鄧一雪
復雜科學最新論文
集智斑圖頂刊論文速遞欄目上線以來,持續收錄來自Nature、Science等頂刊的最新論文,追蹤復雜系統、網絡科學、計算社會科學等領域的前沿進展。現在正式推出訂閱功能,每周通過微信服務號「集智斑圖」推送論文信息。掃描下方二維碼即可一鍵訂閱:
推薦閱讀
集智俱樂部QQ群|877391004
原標題:《Nature:新冠流行難預測,超級計算機和氣象學家來幫忙》
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

